
Apache Iceberg - What Is It
Diving Deep With A Guest Post From Julien Hurault
Hi everyone 👋, Ben here.
I’m excited to feature Julien Hurault, a Data Engineer Consultant who specializes in building modern data platforms. In today’s article he’ll be digging into Iceberg and what he’s learned after digging into its various features.
This article consolidates everything I've learned about Iceberg over the past month. It’s a bit long, I hope you will enjoy it!
I publish weekly in my newsletter about data engineering trends, patterns, and tricks. Subscribe for free to receive new posts!

Paris, July 26, 2024.
The Olympic Games are about to begin.
You have just arrived in Paris, and you have started searching for a hotel.
But “catastrophe”…
Your brand new AI pine struggles (once again) to understand your pronunciation of this peculiar French hotel name: "L'Hôtel Élégance”.

Arrrgh.
How are you going to find your destination ?!

Fortunately, you remember one thing about the hotel: you paid around 600€ for your night (how would you forget 🫣).
Driven by a mix of frustration and urgency, you spot a local who seems friendly enough, seated alone at the bustling airport café:
"Excuse me," you start tentatively.
"I’m trying to find my hotel but only remember paying about 600 euros for the night. Can you help?”

His initial response is a curt "Non" delivered without looking up from his newspaper.
The famous Parisian kindness…
Just as you turn to leave, he gruffly adds, "Wait! I may know someone—actually, several taxi drivers—who could help you."
He points to a long queue of taxis outside. "That one, maybe... ah, no, too old. This one... mmm... neither. Yes, this one!”

Waving energetically, he calls over a driver. "Hey, Tohspans, come here!”

After some French blablabla between them, Tohspans turns to you with a reassuring smile.
"Yes, I can assist you! You're in luck today.
While I don't know the price of each hotel, I can provide the minimum and maximum rates for each neighborhood.
This should help narrow down your search.”

That's great!
Instead of going from hotel to hotel and scanning the entire city, you can focus only on neighborhoods with hotels within your price range.
From the moment you asked the grumpy guy, his scan of the taxi line, and your interaction with Tohspans, you accessed various levels of metadata that helped you narrow down your search.
And you see me coming…
This is exactly what Iceberg enables: it sets a standard for exposing metadata and statistics about files stored in a data lake.
It consists of three components: a catalog, vx.metadata.json files (snapshots), and manifests files.
They are represented in our story as follows:
• Data files = hotel prices per night.
• Manifest = lowest and highest price per night in each area.
• Snapshots / vx.metadata.json = hotel prices at a certain time.
• File of taxi = hotel prices history (all the historical snapshots).
• Catalog = the old grumpy guy pointing to the latest version of the hotel prices (Tohspans).
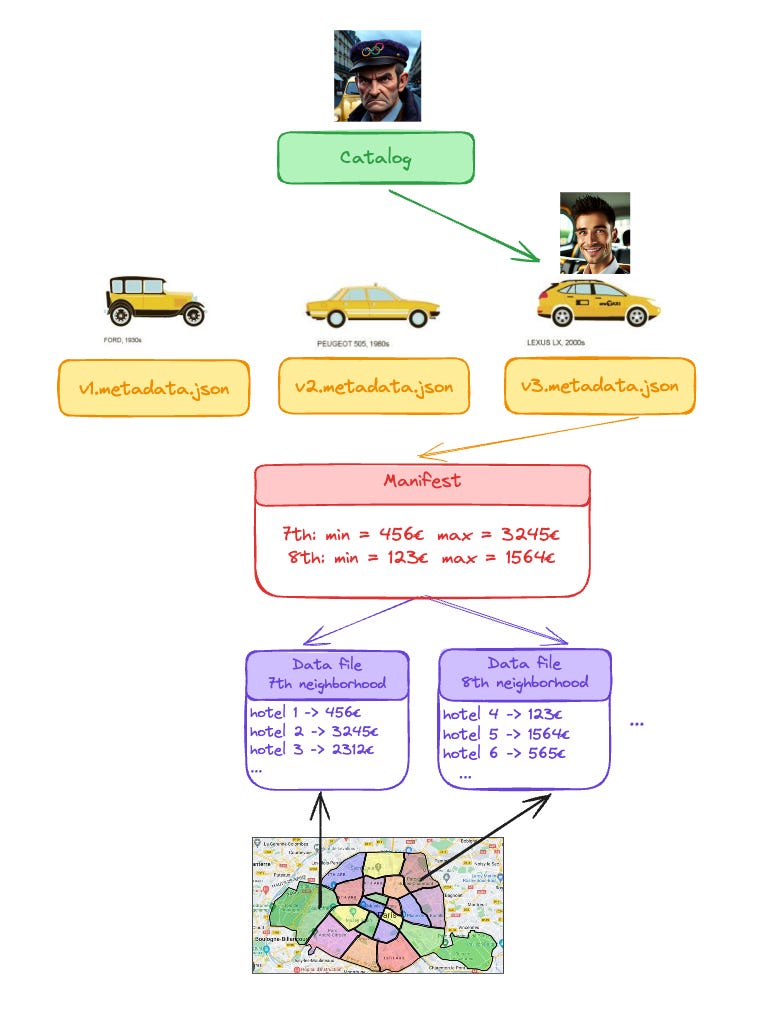
One abstraction we missed in the story is the manifest list files. These files contain statistics about a group of data files and track all associated manifests and some aggregated statistics.
Below is a more formal overview of the metadata organization in Iceberg and how the query engine accesses it.

Iceberg features
Iceberg offers more than just metadata exposure; it transforms files stored in a data lake into proper database tables!
Let’s explore some of the features Iceberg enables:
ACID Consistency
ACID stands for Atomicity, Consistency, Isolation, and Durability. These four crucial properties guarantee data integrity, even if an issue arises during a transaction.
The Iceberg metadata management system, particularly snapshot isolation, ensures no changes are made if a transaction is not completed. Therefore, a transaction either fully succeeds, updating all required data, or fails, leaving everything as it was.
Snapshot isolation also enables multiple users to read and write to the database simultaneously without disrupting each other. This feature is especially useful for avoiding conflicts when different users try to update the same data concurrently.
Note: To ensure atomic transactions, a catalog is essential because S3 alone doesn't support simultaneous writes.
Partitioning
Partitioning improves query speed by grouping similar data together, reducing the number of files the engine must open.
One common partitioning method used in data lakes is Hive partitioning.
In Hive, partitioning arranges data into a hierarchy of folders based on the values of specific columns.
For example, in an S3 bucket, our hotel data might be stored in the following way:
/hotel-prices/neighborhood=7/pricing-date=2024-04-12/prices.parquetHere, a data file contains prices for a specific neighborhood on a specific date.
However, this structure can make it hard to access data via a different access pattern.
For example, you'd need to open many files to check prices across different neighborhoods for a specific date, which is less efficient.
One solution might be to rearrange the data that way:
/hotel-prices/pricing-date=2024-04-12/neighborhood=7/prices.parquetBut this would mean rewriting the data for different query needs.
Iceberg offers instead an intelligent way to manage partitions using metadata and not folder structures. This allows you to update how data is partitioned by adjusting metadata without moving the data itself.
Furthermore, Iceberg also supports hidden partitioning.
For instance, if you want to partition data by pricing date on a monthly rather than daily basis, you would have to manually calculate the month for each date and store it in the data.
However, with Iceberg, built-in functions (year(), month(), day(), hour()) automatically handle these calculations behind the scenes.
For instance, to partition a table by month, you can simply use the month() function in the table definition:
CREATE TABLE hotel_prices(
pricing_date date,
hotel_id int,
price double,
)USING iceberg
PARTITIONED BY (month(pricing_date))The actual partition values are not visible to the user, hence this is referred to as "hidden partitioning".
Time Travel
Iceberg keeps track of all updates to a table by creating separate snapshots for each change.
This feature allows you to return to a previous table version easily.
To revert to an earlier version, the Iceberg catalog simply points the table to the desired snapshot file.

This also enables the easy creation of virtual copies of data, similar to Snowflakes or Databrick's zero-copy clone feature.
Iceberg maintenance
Query performance heavily depends on the number of files a database needs to access during a query. Handling streaming data, which often creates many small files, can slow down Iceberg’s performance.
To address this issue, a process called compaction merges small data files into larger ones. This reduces the number of files the database needs to access, thereby improving performance.
Some catalogs, like Glue offer automatic compaction for Iceberg tables, automating this process and eliminating the need for manual intervention.
Compaction can be straightforward, simply combining files randomly, or it can be more complex, involving sorting records before merging.
Iceberg Eco-System
Catalog Implementations
The catalog in Iceberg plays a crucial role as it acts as a centralized hub.
It provides the query engine with all the necessary information to access a table's metadata and ensures that transactions are handled correctly.
There are several types of catalog implementations available, each suited to different environments and needs:
Open source catalogs: Hive Metastore, Apache Nessie
Vendor catalogs: AWS Glue, Snowflake Catalog, Dremio Catalog, Starburst Catalog, GCP BigLake Metastore
JDBC Catalogs: PostgreSQL catalog, AWS DynamoDB catalog
REST Catalog (more about it below)
Choosing the right catalog involves considering several factors:
Compatibility - Ensure the catalog supports read-and-write operations with the query engines you plan to use.
Infrastructure management - Some catalogs require additional infrastructure, like a database for the PostgreSQL catalog or a dedicated server for Nessie and Hive.
Transaction support - If your use case involves complex transactions across multiple tables, choose catalogs that support these capabilities.
REST Catalog
The REST catalog in Apache Iceberg is essentially a standard API interface for interacting with an Iceberg catalog through HTTP requests.
In our hotel story, this would be like filling out a standard paper form to communicate with the old grumpy guy.

The REST catalog provides a standard API interface, but the actual implementation can vary depending on the backend system in use.
This design ensures the interface remains consistent regardless of the specific technology or system handling the catalog operations. As a result, it increases interoperability and reduces vendor lock-in.
Apache Nessie

The way Apache Iceberg handles snapshots for each table update is similar to version control systems like Git.
Apache Nessie capitalizes on this concept, offering Git-like semantics for data management on top-of-iceberg tables
Snapshots as Commits - Like Git commits, each snapshot in Iceberg represents a specific state of the table at a point in time. This allows you to track changes and revert to previous versions if needed.
Branches - Like Git, Nessie uses branches to manage different lines of development or testing for datasets. Each branch represents a sequence of snapshots, allowing you to work on different versions of data in parallel without interference.
Merge - When changes from one branch are ready to be integrated into the main dataset, they can be merged, similar to merging branches in Git.
The flexibility provided by this approach is particularly valuable for implementing a Write Audit Pattern, as explained here:

Catalog War
As this article highlights, the catalog in Iceberg functions as a crucial access point to the data lake.
When a vendor controls this catalog, they essentially control access to the data and become the data gatekeepers.
If an engine wants to read/write to a table, it first needs to ask the catalog where to find its metadata.
This control position offers strategic benefits to a business: you can potentially limit interoperability with other platforms or promote specific integrations.
This issue becomes apparent when looking at the read/write capabilities of catalogs run by warehouse providers.
For example, Snowflake can only read from an external catalog, and an external catalog can only read from a Snowflake catalog.

This restriction makes it impossible for users to have a single, universally accessible catalog that can also write to native Snowflake tables.
This trend is not unique to Snowflake; other providers like Dremio, Starburst, and Databricks exhibit similar behaviors. They push users toward using their catalogs by restricting the functionalities of tables not managed by them.
To work around this, you might consider using multiple catalogs dedicated to specific tables. You could then transfer data between these catalogs using commands like:
CREATE TABLE snowflake_iceberg_table AS SELECT * FROM external_engine_iceberg_tableFor more details on this process, you can check here:
PyIceberg
PyIceberg is a Python library designed to work with Iceberg tables. It directly supports a range of catalogs, including REST, SQL, Hive, Glue, and DynamoDB.
Catalog is setup via a YAML config file stored in ~/.pyiceberg.yml:
# Glue Catalog
catalog:
default:
type: glue
aws_access_key_id: <ACCESS_KEY_ID>
aws_secret_access_key: <SECRET_ACCESS_KEY>
aws_session_token: <SESSION_TOKEN>
region_name: <REGION_NAME>
# DynamoDB Catalog
catalog:
default:
type: sql
uri: postgresql+psycopg2://username:password@localhost/mydatabase
# REST Catalog
catalog:
default:
uri: http://rest-catalog/ws/
credential: t-1234:secretOnce you've set up and loaded the catalog in PyIceberg, you can create namespaces (similar to schemas in other databases) and tables.
In the example below, the table schema is directly inferred from a parquet file.
from pyiceberg.catalog import load_catalog
import pyarrow.parquet as pq
import os
# LOAD CATALOG
catalog = load_catalog("glue")
# CREATE SCHEMA
catalog.create_namespace("paris_og")
# CREATE TABLE
catalog.create_table(
"paris_og.hotel_prices",
schema=pq.read_table("/tmp/hotel_prices.parquet").schema,
location="s3:///paris_og/hotel_prices",
)PyIceberg supports two modes for writing data: "append," which adds new data to an existing table, and "overwrite," which replaces the existing data in the table. Merging is not an option for now.
import pyarrow.parquet as pq
from pyiceberg.catalog import load_catalog
catalog = load_catalog(name="glue")
table = catalog.load_table("paris_og.hotel_prices")
df = pq.read_table("/tmp/hotel_prices_2024-04-04.parquet")
table.append(df)The data in PyIceberg is handled using Apache Arrow, a format designed for efficient in-memory columnar data storage.
This format is compatible with multiple data processing engines.
For example, DuckDB, an in-memory database, can directly interact with datasets stored in Arrow format.
This means you can use DuckDB to perform queries on the data and then directly stream the query results back into an Arrow format.
from pyiceberg.catalog import load_catalog
catalog = load_catalog(name="glue")
# Load data from Iceberg into DuckDB
con = catalog.load_table("paris_og.hotel_prices").scan().to_duckdb(table_name="hotel_prices")
# Run SQL in DuckDB and send back the result to Arrow
output = con.execute("""
SELECT *
FROM hotel_prices
WHERE price > 1000
""").arrow()
# Write output in Iceberg table
catalog.load_table("paris_og.my_hotel").overwrite(output)PyIceberg has shown promising performance: some tests have been conducted here: 6.7GB, 10M row files were loaded in 16s by 8 threads.
Iceberg Use-Cases
Data platforms typically follow a certain setup where data is stored in a data lake, then moved to a data warehouse to be cleaned and merged before it's used for BI.
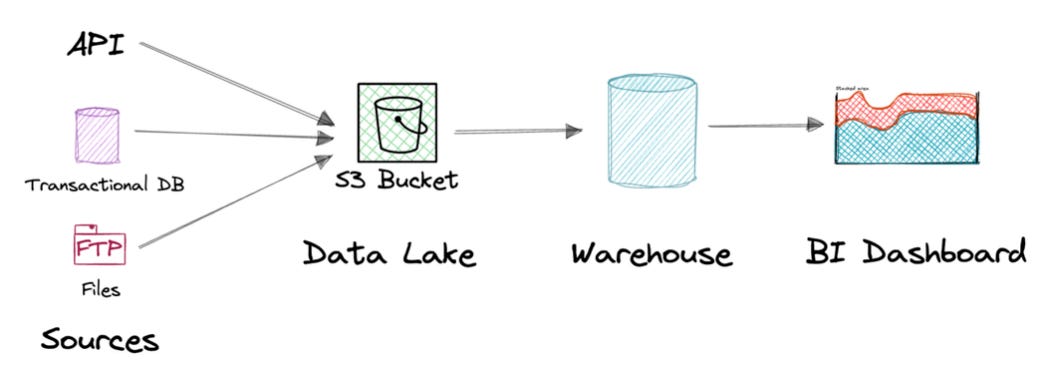
Maintaining an ETL process between the data lake and the warehouse involves data duplication, which is error-prone, requires maintenance, and can get expensive.
By using Iceberg in the data lake, data can be loaded into the warehouse without being copied.
This is the major use case for Iceberg: query data without copying it.
A side effect of this is making compute engines interoperable. Any engine can access the data without being locked into a specific provider.
Users can choose the best engine based on dataset size, pipeline latency, or transformation complexity.
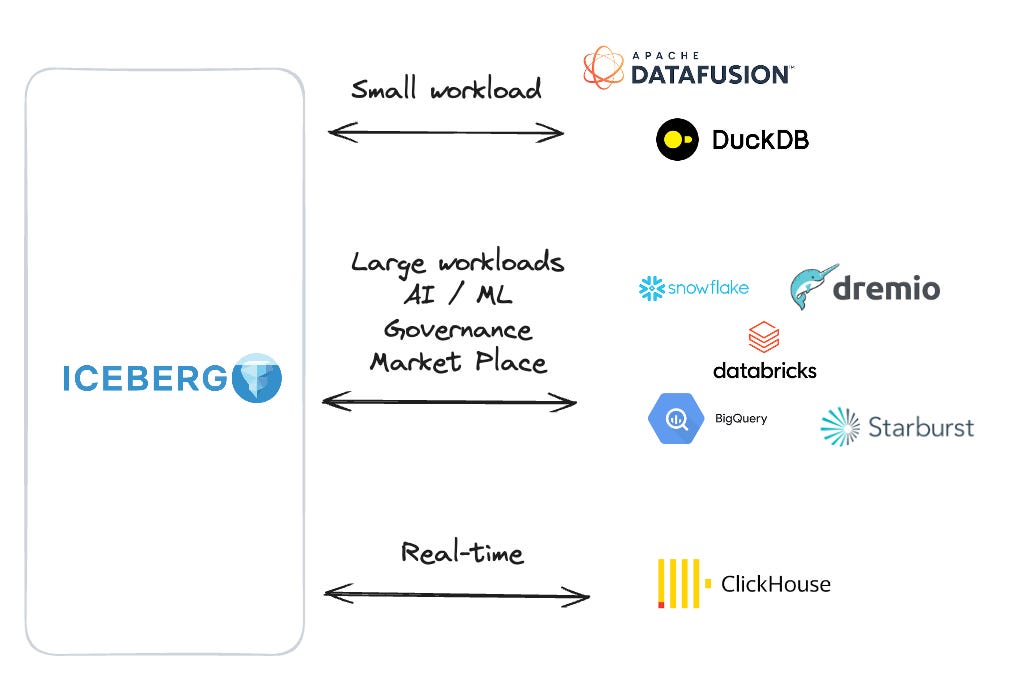
You can gain additional efficiency by using Iceberg not just for data pipelining but also for data distribution.
Imagine a scenario where a data scientist needs to explore raw data.
Accessing a warehouse table could be expensive, especially for an “offline” use case without performance constraints.
Moving the table to Iceberg allows them to experiment using a smaller, possibly local, engine without worrying about escalating warehouse costs.
If we push this thinking a step further, with Iceberg, the gravity of the stack should shift from the warehouse to the lake.
The warehouse and compute engines would become commodities used only for their strengths.
They would be used in an almost stateless manner, systematically reading from and writing to Iceberg.
… much like supercharged Lambda functions?
Sources:
Thanks for reading,
-Ju
Video Of The Week: 5 SQL AI Functions Databricks Has And How To Use Them
Join My Data Engineering And Data Science Discord
If you’re looking to talk more about data engineering, data science, breaking into your first job, and finding other like minded data specialists. Then you should join the Seattle Data Guy discord!
We are close to passing 7000 members!
Join My Data Consultants Community
If you’re a data consultant or considering becoming one then you should join the Technical Freelancer Community! I recently opened up a few sections to non-paying members so you can learn more about how to land clients, different types of projects you can run, and more!
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Chronon, Airbnb’s ML Feature Platform, Is Now Open Source
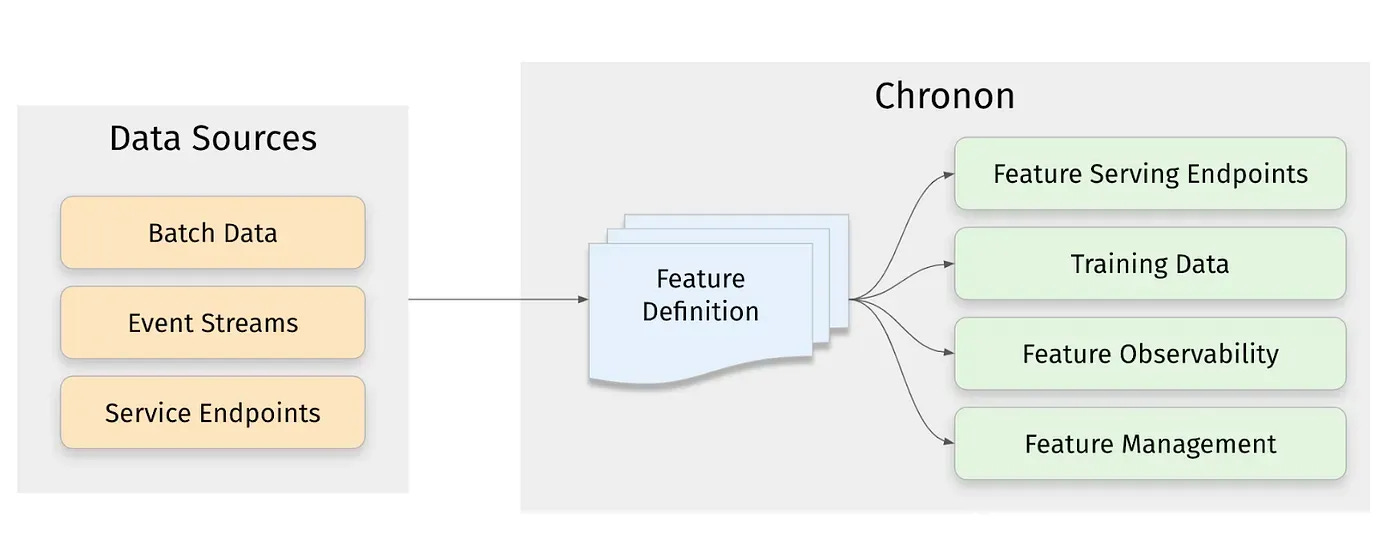
Airbnb built Chronon to relieve a common pain point for ML practitioners: they were spending the majority of their time managing the data that powers their models rather than on modeling itself.
End Of Day 129
Thanks for checking out our community. We put out 3-4 Newsletters a month discussing data, tech, and start-ups.
 | A guest post by
|
Note: Nessie is an open source project. But it is not an "Apache" project.
So, we should mention it as "Nessie" instead of "Apache Nessie" in all the places.
Amazing article! Lot of depth. Is choosing between Apache Iceberg format or a delta table format depends on whether we use Databricks or Snowflake? Or, are there other factors to consider when laying down the architecture foundations? Might be a stupid question but I am just getting started on these formats.