
Optimizing Your Data Infrastructure Costs: How To Approach It And Common Issues
I once had an engineer tell me that they essentially didn’t want to consider cost as they were building a solution. I was baffled. Don’t get me wrong, yes, when you’re building, you iterate and aim to improve your solutions cost.
But from my perspective, I don’t think completely ignoring costs from day one is a good plan.
Cost plays a role in all forms of projects, whether you’re building bridges or writing code. How much budget is allocated to build and maintain a solution is important. In the real world, it can change the materials used, the timeline, or the final product’s design.
Whereas in the software and data world, it might push other features and decisions that you make.
If anything, cost and performance optimization are likely one of the top things I enjoy doing as an engineer. Sure, it’s fun to build new solutions and infrastructure. But it’s often when we are trying to figure out how to run systems more efficiently or cost-effectively that I’ve felt myself solving a real problem.
It forces you to consider methods of storing or processing data in more effective ways that are still easy to maintain, which can feel limiting.
There are plenty of common issues that drive up data infrastructure costs, but to find them, you likely first need to approach your cost-saving efforts in an organized way.
Approaching Cost-Saving
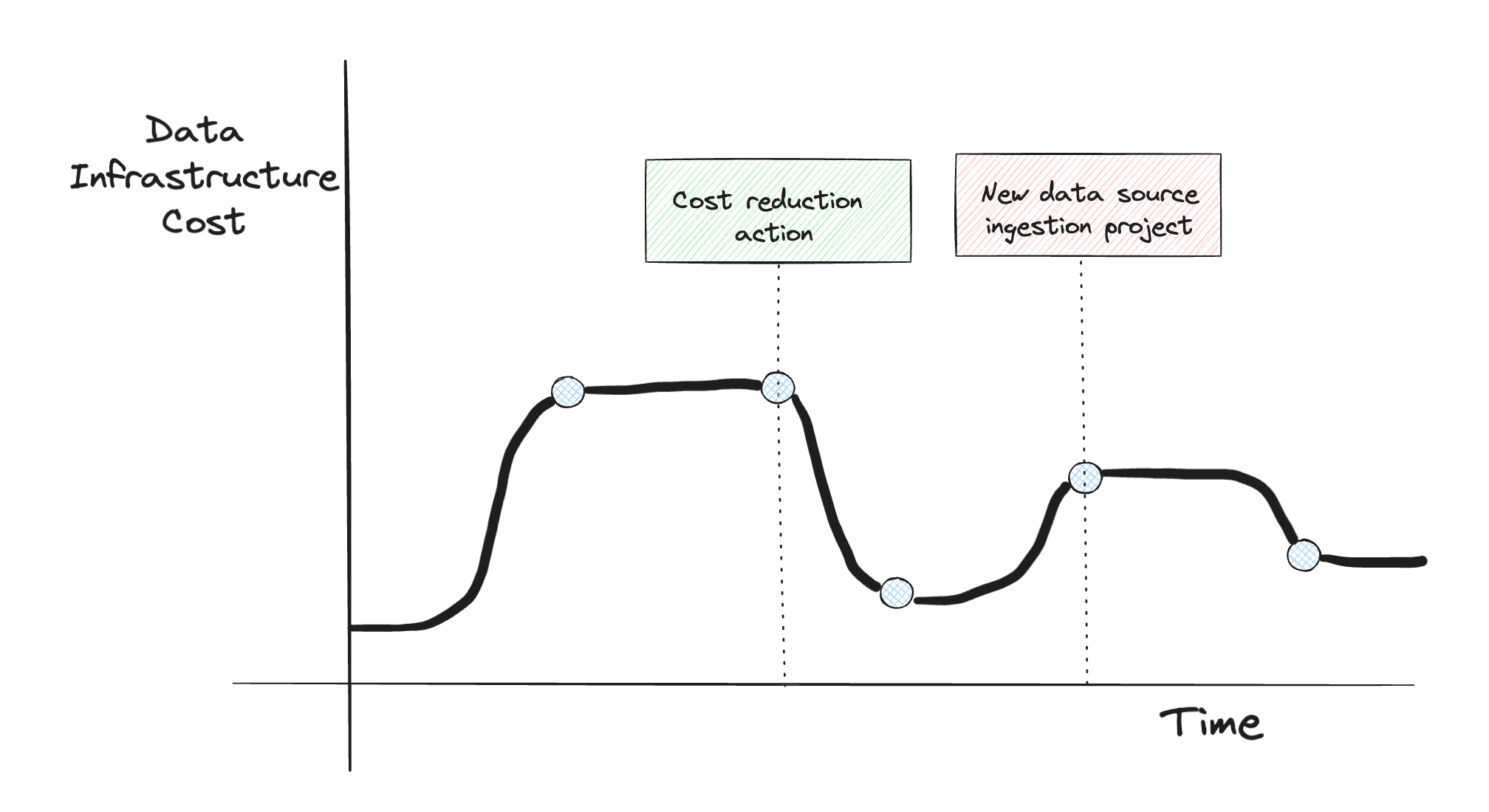
The pursuit of cost efficiency is an ongoing journey. Even after deployment, we must revisit systems to incrementally improve optimization. The key is continually questioning and diving deeper.
Before diving into some of the common culprits for data infrastructure costs, I’d like to start by going through how you can start to approach this problem.
Step one in my mind, after deciding that you’d like to reduce your data infrastructure costs, is to highlight, by product and by job/dashboard/process, how much things are costing.
For example, in general, I will put together a sheet that looks like the one below(you might add some other columns such as prioritization, data processed, etc).

