
Building LLMs on Databricks
A New Era of Data Engineering?

By Daniel Beach author of Data Engineering Central
Unless you live far away in some distance forest in a cave or in a log cabin you built with your hands (call me if you do), it’s impossible to miss the literal explosion of AI tooling coming out of Databricks these days.
Not a week goes by where there isn’t some new “shiny thingy” that is released in the AI and LLM space on Databricks.
Databricks has clearly taken the position that ML and AI are the future of the Data Space in the future, and are betting the house on it.
If you have any doubts, look at their homepage. AI.

And if you look at the context and news surrounding Databricks, that only solidifies the fact they are pouring a lot of time, money, and energy into AI.
Well … if it wasn’t obvious before it should be now. Databricks is jumping headfirst into the AI and ML craze and they want to be The GOAT of the AI space.
The future of Data Engineering in an AI and ML context.
Since Databricks is one of the key players in the Data Platform and Data Engineering space, it’s not a stretch to say that they can and do have a big impact on the work and future of Data Engineering as a whole.
This should raise the question in the minds of many data practitioners … “How can, and should I hitch myself to this AI and ML bandwagon.”
There are certain large, industry-wide inflection points that we all experience in our careers. We have a choice when we hit those moments.
Ask yourself this question.
Where will I be and what will I be working on 10 years from now? Do you still want to be the SQL Server DBA working on SSIS and writing stored procedures while everything else is playing around with Snowflake and Databricks?
While some people might buck the system, I’m going to assume a large majority of engineers want to move along with the industry. The rise of the LLM and AI has solidified its place in the tech landscape.
We can’t go back. Not everything will change, but many things will.
So, if our choice is to hide under the rug or put our hat on and set off into the AI and ML sunset … let’s lock arm and arm and walk together into the sunset of AI and ML (LLM) Data Engineering in a Databricks context.
AI and LLMs on Databricks.
While Databricks has clearly been working a lot in the ML space, given things like Feature Stores and managed mlflow … it’s amazing how quickly they pivoted to providing LLM-specific tooling and resources in such a short amount of time.
And we are not talking milk toast LLM stuff either, but the real deal as you will see soon enough.
Building LLMs on Databricks can be boiled down into the following thoughts based on the tooling currently available.
Vector Indexes
Open-source LLM models
Hosted endpoints for the above
This might not seem like much on the face, but I assure you that given today’s fast-moving and haphazard LLM tooling space, having a reliable and easy (and I mean easy) product that allows you to write your own RAG with your own data and interact with an LLM with ~50 lines of Python code is quite amazing.

Learning LLMs on Databricks with a RAG application.
What we are going to do now is give you a crash course in LLMs, RAG, and Vectors … all on the Databricks Platform. One of the benefits of Databricks making the barrier of entry so low for AI on their platform is that it allows Data Engineers and others to easily build and experiment with LLMs.
This has the benefits of …
Allowing you to learn AI and LLM skills that will be valuable in the future
Gain a broader understanding of AI technology and terminology that will make you an expert to others as they look to adopt these new AI stacks.
First, let’s do a 20,000-foot view of LLMs and RAG workflows in the AI context.
AI/LLM Context.
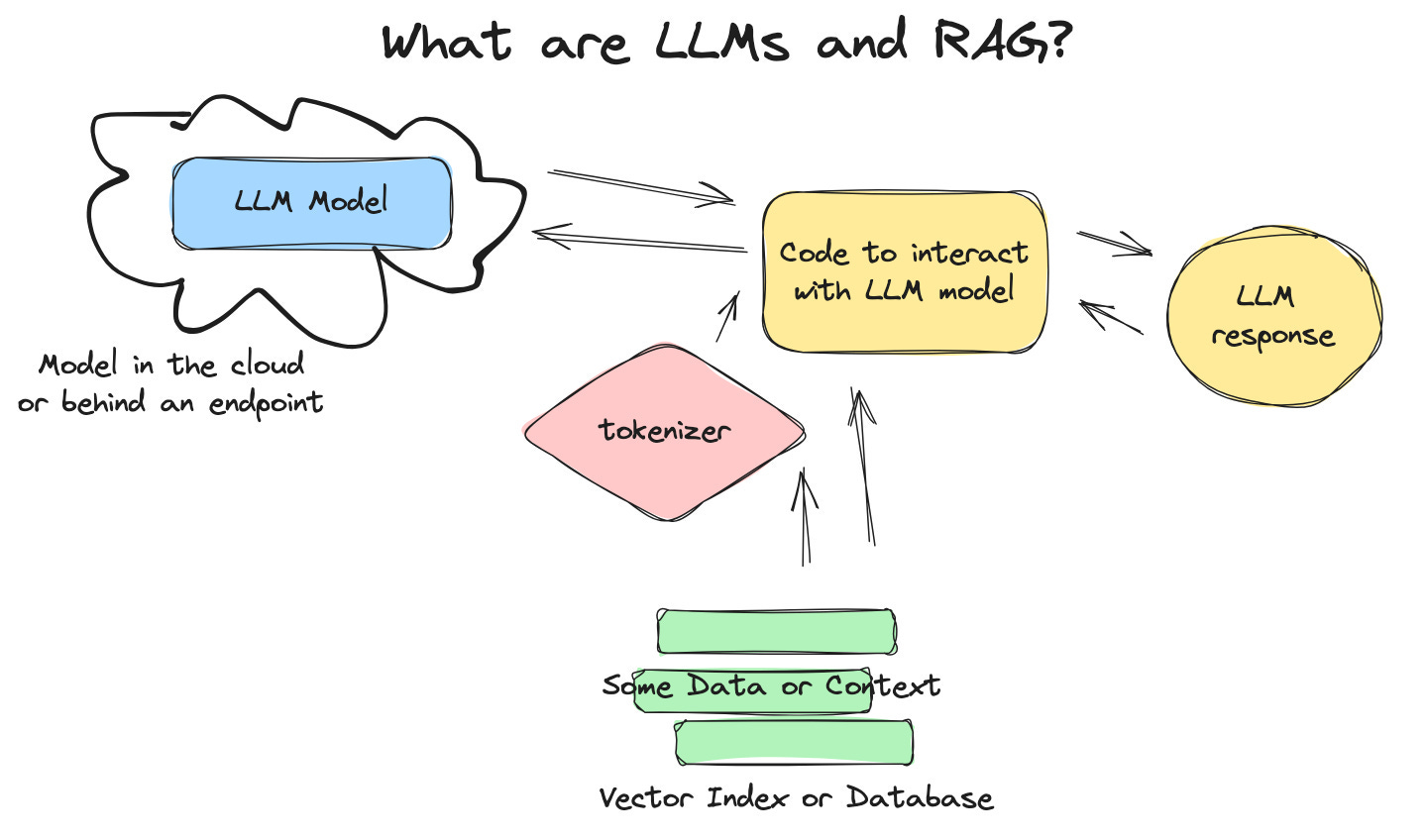
LLM in the machine learning context is not all that different from what has been done before, from a Data Engineering perspective. Here are the highlights.
LLMs are model objects (you need the model file).
LLMs are very large and require a lot of memory to “load” them.
LLMs are “data-centric” models.
You need the ability to “exercise” or “call to the model” with a request and get a response (prediction).
There is a lot of DevOps and “glue” to create a “pipeline” to interact with a LLM model.
Massaging data to send to the model in a format it expects is important.
As someone who’s worked around ML systems for years, yes LLMs are new and some of the tooling is new, but at its core, it has a very similar set of Data Engineering steps that need to be taken.
To be clear here are the main components you will run into when playing around with LLMs in a Databricks AND non Databricks context.
Vector Database or Index that holds “context” or other data/documents specific to your use case.
LLM model behind and Endpoint/API etc.
Code and packages (glue) to interact between user, data, context, and the LLM endpoint.
I think this will make more sense to you when you see it in action, so let’s show you what this looks like inside Databricks.
Example.
Let’s start by doing a simple example of how easy it is within a Databricks Notebook to interact with an LLM.
First, we install a bunch of Python libraries to make our lives easier.
%pip install mlflow==2.10.1 lxml==4.9.3 transformers==4.30.2 langchain==0.1.5 databricks-vectorsearch==0.22
dbutils.library.restartPython()Next, we will interact with a pre-configured `llama-2` endpoint provided by Databricks.
from langchain_community.chat_models import ChatDatabricks
chat_model = ChatDatabricks(endpoint="databricks-llama-2-70b-chat", max_tokens = 200)
print(f"Test chat model: {chat_model.predict('What is Apache Spark')}")If we ran this we get a reasonable response.
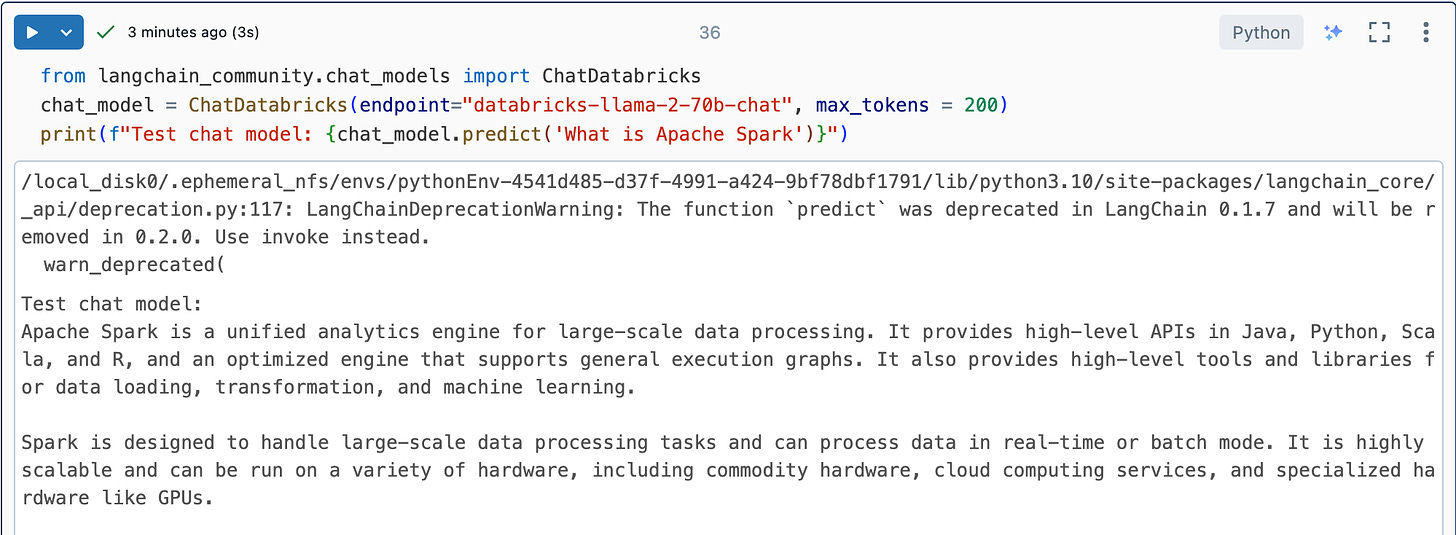
There you have it, you’ve done your first LLM work as a Data Engineer! Not much, but you can see how quickly one can get up and running with LLMs on the Databricks platform.
This sets the stage for more complex use cases.
Example RAG on Databricks with Vector Indexes.
So, we took our first baby steps into the Land of AI on Databricks, with a few lines of Python we found out how easy it can be to do LLM workflows.
Of course in real life, things can get a little more complicated, enter the RAG workflows.
RAG stands for "Retrieval-Augmented Generation." It's a technique that combines the retrieval of documents or information from a large corpus of text with a generative model to enhance the quality, accuracy, and relevance of the generated text.
What “RAG” does is complicate the LLM workflow we saw previously a little, by adding some sort of “context,” usually in the form of internal docs and datasets, injecting this context into the LLM pipeline.
Why is this helpful?
Well, since the LLMs we have access to were not trained on our specific data and context, by adding this extra step of injecting our data and text corpus into the workflow, our LLM can be extended to include this information.
Let’s work through the code for doing this on Databricks. It’s a little more complicated because we are introducing some new concepts like Vector Indexes.
Quickly … what are Vector Indexes?
Boiling it down to something as simple as possible, Vector Databases and Indexes allow us to take our data/text and …
create “embeddings” of that text that our LLM understands.
store those “embeddings” somewhere they can be accessed.
To put in the technical Databricks terms …
“A vector database is a database that is optimized to store and retrieve embeddings. Embeddings are mathematical representations of the semantic content of data, typically text or image data.” - Databricks
“With Vector Search, you create a vector search index from a Delta table. The index includes embedded data with metadata. You can then query the index using a REST API to identify the most similar vectors and return the associated documents.” - Databricks
Let’s get cracking with our RAG example on Databricks and see if the code helps you make sense of what is going on.
Step 1: Make an index and index endpoint based on our data.
First, we create a Delta Table to hold the data we would want to index (in many cases internal documents, data gathered from the web, or tabular data massaged into a text format).
CREATE TABLE IF NOT EXISTS default.blog_sentence_data
(
primary_key BIGINT,
blog_sentence STRING,
blog_date DATE
)
USING DELTA
PARTITIONED BY (blog_date);
ALTER TABLE default.blog_sentence_data SET TBLPROPERTIES (delta.enableChangeDataFeed = true);Step 2: Get your data into storage.
We would then do the necessary transformations for our use case, whatever that is, and insert the data into our Delta Table (if you need an example to help the thought process, think about blogs like this one you are reading specific to Data Engineering … gathering all that text and storing it here).
my_data.createOrReplaceTempView('my_data')
spark.sql("""
INSERT INTO default.blog_sentence_data
(primary_key,
blog_sentence,
blog_date)
VALUES
(SELECT * FROM my_data)Step 3: Create a Vector Index and endpoint.
Next, we want to actually create the vector index endpoint that can be accessible by other processes and make sure any new data in our base table is automatically synced and embedded into our vector index.
from databricks.sdk import WorkspaceClient
import databricks.sdk.service.catalog as c
from databricks.vector_search.client import VectorSearchClient
vsc = VectorSearchClient()
#The table we'd like to index
source_table_fullname = "default.blog_sentence_data"
# Where we want to store our index
vs_index_fullname = "default.databricks_index_blog_sentence_data"
VECTOR_SEARCH_ENDPOINT_NAME = 'RAG_testing'
vsc.create_delta_sync_index(
endpoint_name=VECTOR_SEARCH_ENDPOINT_NAME,
index_name=vs_index_fullname,
source_table_name=source_table_fullname,
pipeline_type="TRIGGERED",
primary_key="primary_key",
embedding_source_column='blog_sentence',
embedding_model_endpoint_name='databricks-bge-large-en'
)Of course, this code is a little more complicated, but it’s easy enough to read and follow along with …
Set our source table and target index table
Go ahead and create the index while indicating …
the primary_key column
the column that has the data we to get embedded and stored in the vector index.
Even now, with just our vector index created, we can do fancy things like similarity search which has many applications in a Data Engineering context, I suggest you read more here.
Let’s move on.
Combining the Vector Index with the LLM.
Now we can get to the crux of the matter, combining our previous LLM work with our next vector index containing our data. We can do this by building a “retriever” (remember our RAG definition?)
Our “retriever” will be able to hit the vector index we previously created and pass this information along (chain) to our LLM.
Let’s just jump straight into the code.
from databricks.vector_search.client import VectorSearchClient
from langchain_community.vectorstores import DatabricksVectorSearch
from langchain_community.embeddings import DatabricksEmbeddings
import os
host = "https://" + spark.conf.get("spark.databricks.workspaceUrl")
os.environ['DATABRICKS_TOKEN'] = 'XXXXXXXXXXXXXXXXXXXXX'
embedding_model = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
def get_retriever(persist_dir: str = None):
os.environ["DATABRICKS_HOST"] = host
vsc = VectorSearchClient(workspace_url=host,
personal_access_token=os.environ["DATABRICKS_TOKEN"])
vs_index = vsc.get_index(
endpoint_name=VECTOR_SEARCH_ENDPOINT_NAME,
index_name=vs_index_fullname
)
# Create the retriever
vectorstore = DatabricksVectorSearch(
vs_index, text_column="blog_sentence", embedding=embedding_model
)
return vectorstore.as_retriever()We are now ready to combine the index retriever with our LLM.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatDatabricks
chat_model = ChatDatabricks(endpoint="databricks-llama-2-70b-chat", max_tokens = 200)
TEMPLATE ="""You are an Data Engineer. You need to be as technical as possible.
Question: {question}
Answer:
"""
prompt = PromptTemplate(template=TEMPLATE, input_variables=["question"])
chain = RetrievalQA.from_chain_type(
llm=chat_model,
chain_type="stuff",
retriever=get_retriever(),
chain_type_kwargs={"prompt": prompt_string}
)
answer = chain.run(prompt)
print(answer)As you can see again, while the LLM code is a little longer than our first baby steps example, the flow has changed a little to add in our “retriever,” which contains the information in our vector index.
Reviewing our whirlwind tour of LLMs on Databricks.
Yikes, that might have been a lot of information compacted into a pretty tight space. I can understand if your eyes are a little glazed over. That’s ok.
The point here was to try and do a crash course on LLMs, in the context of Databricks, and take away some of the “scaries” that can surround the topic of AI and LLMs for Data Engineers.
I wanted to make a few things clear …
AI and LLMs are here to stay and will only continue to expand as companies like Databricks invest ALOT of time, money, and energy into them.
AI and LLMs have infrastructure that has come a long way, and companies like Databricks are making them extremely approachable.
There is no reason, as a Data folk, to be scared of LLMs or the code that surrounds them, thinking it’s out of your reach. We saw how a few lines of Python got us started.
Once you understand a few basics, and play around with some toy examples (which are extremely easy to do on Databricks), you will see that at the core, LLMs and their dataflow can easily be handled by Data Engineers once a little experience is under the belt.
I encourage you to use this information to learn about some of the topics you saw and just read about …
vector indexes and databases
different types of LLM models
model serving endpoints
Databricks and their tooling
RAG workflows
I think it’s certain that a few years from now you will be happy with yourself if you take the time to dig into these topics, to understand them a little more, and even better, to play around on your own!
Thanks for reading!
The Magic of Hudi + Flink, Stream Processing on the Data Lakehouse

Implementing Stream Processing on the Data Lakehouse for High Performance, Operational Efficiency and Cost Savings
Join DeltaStream and Onehouse April 16 on LinkedIn for a conversation on the magic of pairing Hudi+Flink.
Explore stream processing within the data lakehouse to create efficient data pipelines and minimize operational expenses. Learn about common patterns in the lakehouse and streaming landscapes, then discover ways to streamline how you move, process and store data.
DeltaStream, the unified stream processing platform, and Onehouse, the universal data lakhouse, have teamed up for this live conversation. Register now!
Thanks DeltaStream for sponsoring this newsletter!
Join My Data Engineering And Data Science Discord
If you’re looking to talk more about data engineering, data science, breaking into your first job, and finding other like minded data specialists. Then you should join the Seattle Data Guy discord! We are close to passing 6000 members!
Join My Data Consultants Community
If you’re a data consultant or considering becoming one then you should join the Technical Freelancer Community! I recently opened up a few sections to non-paying members so you can learn more about how to land clients, different types of projects you can run, and more!
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
A Decade In Data Engineering - What Has Changed?

The concepts and skills data engineers need to know have been around for decades. However, the role itself has really only been around for a little over 10 years, with companies like Facebook, Netflix and Google leading the charge. Throughout those ten years, there were significant breakthroughs and tools through hype, and general acceptance became stand…
Scaling AI/ML Infrastructure at Uber
Machine Learning (ML) is celebrating its 8th year at Uber since we first started using complex rule-based machine learning models for driver-rider matching and pricing teams in 2016. Since then, our progression has been significant, with a shift towards employing deep learning models at the core of most business-critical applications today, while actively exploring the possibilities offered by Generative AI models. As the complexity and scale of AI/ML models continue to surge, there’s a growing demand for highly efficient infrastructure to support these models effectively.
Over the past few years, we’ve strategically implemented a range of infrastructure solutions, both CPU- and GPU-centric, to scale our systems dynamically and cater to the evolving landscape of ML use cases. This evolution has involved tailored hardware SKUs, software library enhancements, integration of diverse distributed training frameworks, and continual refinements to our end-to-end Michaelangelo platform. These iterative improvements have been driven by our learnings along the way, and continuous realignment with industry trends and Uber’s trajectory, all aimed at meeting the evolving requirements of our partners and customers.
End Of Day 122
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
 | A guest post by
|
I like the terms like corpus, agent, etc, that appear in context of OpenAI, Fixie.ai and several other AI companies. Seeing the use of SQL in this article is a definite turnoff
Nice. Very useful. Thanks.