
Data Engineering Vs Machine Learning Pipelines
What's the difference?
Data engineering and machine learning pipelines are both very different but oddly can feel very similar. Many ML engineers I have talked to in the past rely on tools like Airflow to deploy their batch models.
So I wanted to discuss the difference between data engineering vs machine learning pipelines.
To answer this question, I pulled in Sarah Floris, who is both an experienced data engineer as well as the author behind the newsletter The Dutch Engineer.
So let’s dive in.
Over the past 5 years, data accumulation driven by the popularity of social media platforms such as TikTok and Snapchat has highlighted the difference between data and machine learning (ML) pipelines. These two are essential components of every company, but they are often confused. Although they share similarities, their objectives are vastly different.
Building a data and ML platform is not as simple as it sounds. It requires a lot of work, and it is what I do every day. In this post, we will explore the differences between how machine learning and data pipelines work, as well as what is required for each.
Data Engineering Pipelines
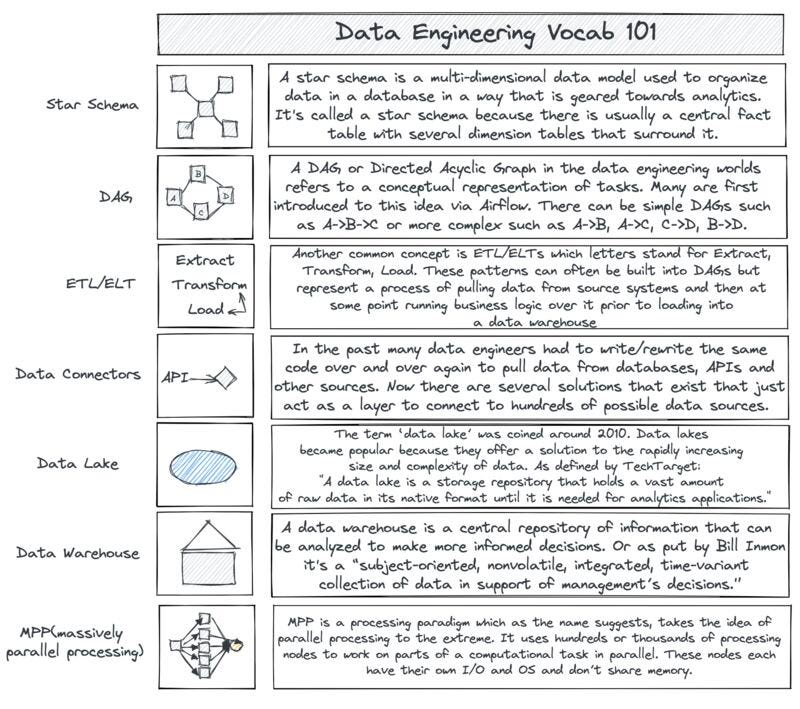
First, let's dive into data pipelines. Data pipelines are a series of processes that extract data from different sources, clean it, and then store it in a data warehouse or database. This is important for companies because it helps them make informed decisions. A data pipeline is made up of four parts:

Data collection: This is where data is gathered from different sources like databases, APIs, and file systems. The data can be in different formats like structured, semi-structured, or unstructured. Data collection needs careful planning and execution to ensure high-quality data.
Data cleaning: This is where data is cleaned by checking for missing values, correcting errors, and transforming it into a consistent format. This makes sure that the data is accurate and reliable.
Data integration: This is where data from different sources is merged into a single dataset. This is important for businesses because it ensures consistent and accurate information for better decision-making.
Data storage: This is where processed data is stored. It's important for quick and easy access to data, as well as data protection and security.
These 4 data pipeline parts are also often referred to as Extract (data collection), Transform (data cleaning and integration), and Load (data storage). The process of extracting, transforming, and loading data is commonly referred to as ETL or ELT.
Some will note that ELTs and ETLs are a subset of the overarching “data workflows” or data pipelines as there are several other sub-classes that often include streaming patterns such as pub/sub or CDC. - Ben Rogojan
These processes can be performed in various sequences, depending on the requirements of the project.
Regardless of how data pipelines are performed, they will generally always follow a linear process starting from the source and ending at storage.
Thus, that’s why you generally hear data engineers say they move data from point A to point B.
Machine Learning Pipelines
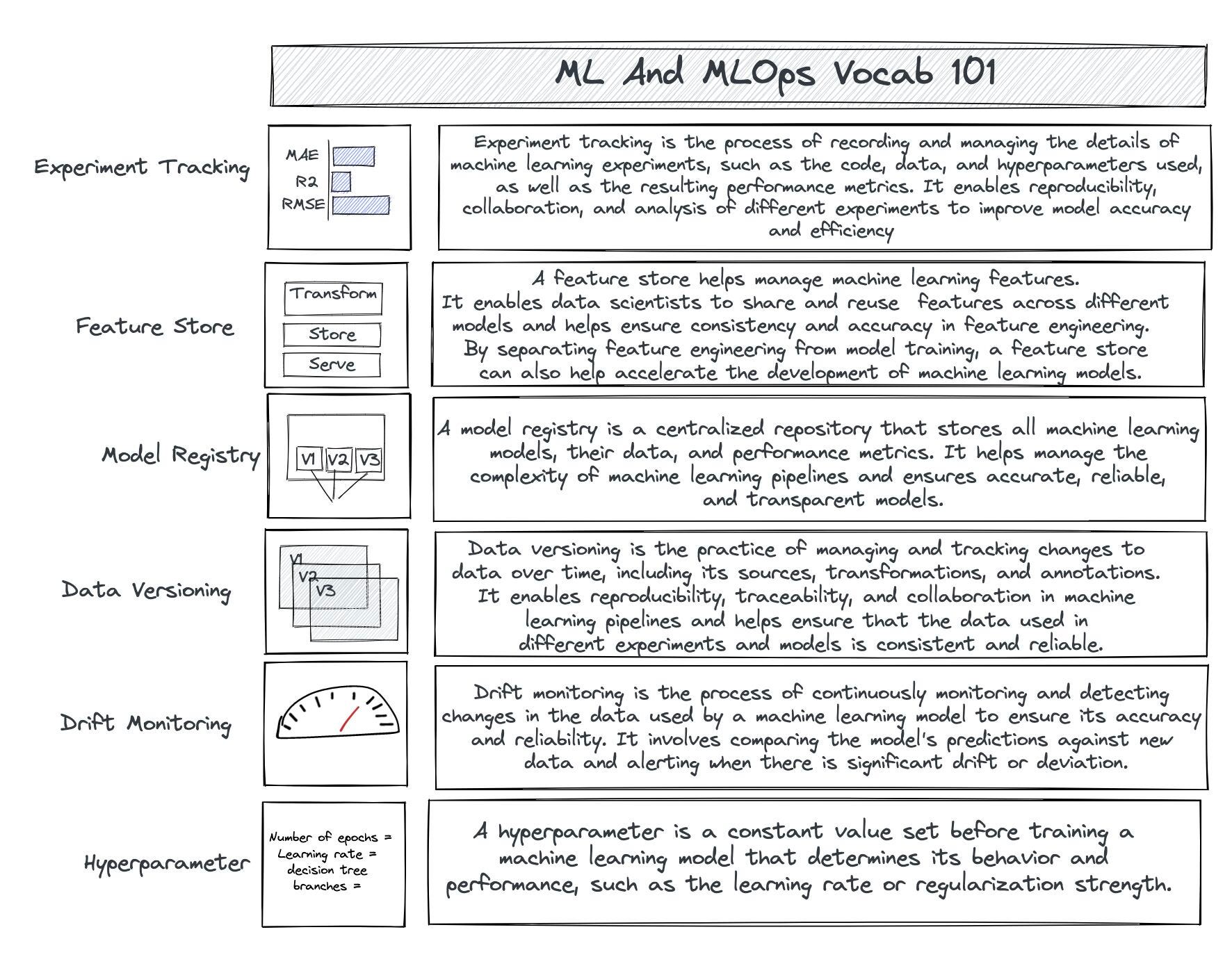
Machine Learning (ML) pipelines don't work in a straight line like data pipelines. Instead, they involve building, training, and deploying ML models. This is used to automate the entire process of building an ML model, from collecting data to deploying it in production. An ML pipeline is made up of five parts:
Data Cleaning: Data cleaning and standardizing data is a crucial aspect of machine learning pipelines. While data engineers do an initial cleaning, data scientists take it further to ensure accuracy and usefulness. This includes tasks such as ensuring consistent date formats, removing null values, and binning ages. They may also perform exploratory data analysis to identify patterns and trends. The role requires a deep understanding of both technical aspects of data cleaning and the broader context in which the data is used.
Feature engineering: Feature engineering is the process of selecting and extracting relevant features from raw data to improve the performance of machine learning models. To increase iteration speed, machine learning engineers will built out a feature store, essentially a few tables that are versioned and created for each model focus area i.e. areas like sales, acquisition, or the likes.
Model training: Model training typically begins with finding an appropriate machine learning algorithm(s). Once the algorithm has been selected, we proceed to train it on the data that we have feature engineered. This process usually involves iterating on the model architecture and hyperparameters until the desired level of performance is achieved. Finally, the trained model can be used to make predictions on new data.
Model evaluation: This phase involves assessing the performance of the trained ML model on a test dataset. When the model has been evaluated and is ready for deployment, we will often save it to a model registry.
Model Registry A model registry is a vital part of a company's machine learning setup. It acts as a central hub to store details about the models that have been trained and deployed. It tracks not only the models themselves but also performance metrics for each model, and other metadata. This information is critical to ensure models can be reproduced and tracked throughout their lifecycle.
Model deployment: We will use the saved model (whether that is from a model registry or wherever stored model) and integrate into a production system where it can be used to make predictions on new data.
Model monitoring: The primary monitoring techniques are performance analysis monitoring and data drift monitoring.
Performance analysis monitoring involves setting up rules to identify whether a metric has failed within a certain time period, such as an hour, month, or other cadence. For example, accuracy above 80% is a good benchmark to aim for, but it's also important to monitor other metrics such as accuracy if working with regression models or precision and recall if working with classification models. In addition to these checks, it's helpful to keep track of any anomalies or patterns in the data that may impact the model's performance over time.
The other primary way to monitor a model's performance is to examine the underlying data. To do this, we need to compare the distribution of the data using statistical techniques and other methods.
All of these components are completed in a circular step, meaning we are starting from data and ending with reintroducing data and going through the cycle again.
Job Types
Batch jobs process data or predict user behavior at regular intervals, storing the results. For data pipelines, this means taking data every 30 minutes or hour, while machine learning pipelines often make offline predictions or batch jobs. The latter predicts user preferences while they are not currently watching shows.
Data pipelines and ML pipelines have another one in common and that is on-demand pipelining.
In data pipelines, this often looks like the “push mechanism” where an event is created and the data from that event is pushed to a Kafka cluster.

In machine learning pipelines, this type of process is often referred to as an online inference. For example, when a user clicks on a website page that requires a new prediction to be made.

Another example is when you finish watching HBO Max's Last of Us show and need a recommendation for a new show, whether it be along similar lines or different ones.
I have only seen one type of job that involves data pipelines: streaming. A streaming data pipeline is a system that processes and moves data in real-time from one place to another. While some may argue that this is similar to on-demand pipelining, I disagree since streaming data happens continuously, while on-demand pipelining happens sporadically.
Data pipelines have three types of jobs: streaming, batch, and on-demand. In contrast, ML pipelines only have batch and on-demand (or "inference") job types.
Computational Needs
Data and ML pipelines are critical components of every organization and can have similar computational requirements.
Data pipelines depend on the volume of incoming data, which ideally changes infrequently. However, sudden changes in data volume can happen, and it is important to ensure that the data pipelines can adjust accordingly. Otherwise, there will be a delay in data processing, which can negatively impact an organization's operations.
On the other hand, ML pipelines depend on both the amount of data and the stage of the ML pipeline process. The computational needs of an ML pipeline change based on the stage of the pipeline, because training requires more compute power than processing or predicting. Therefore, we need to adjust the computational needs accordingly.
Regardless of whether we are using data or ML pipelines, it is critical to ensure that our pipelines can handle sudden and significant changes in compute requirements. This is especially important for data pipelines, where unexpected changes in data volume can cause a backlog of data that affects the organization's ability to make informed decisions. Therefore, it is crucial to ensure that data and ML pipelines are scalable and can handle changes in compute requirements. Otherwise, these pipelines will fail and cause delays in data processing, resulting in a poor user experience.
Never Ending Pipelines
In conclusion, both data pipelines and ML pipelines are important for companies that deal with data. They have different goals, job types, and computational needs. Understanding these differences is important for building, scaling, and maintaining effective pipelines that can handle sudden changes in compute requirements and ensure accurate, timely, and actionable data for better decision-making and improved performance.
Data Events You’re Not Going To Want To Miss!

Stacks & Taps with Mozart Data - San Diego
Resume Critique Workshop for Data Engineers (with Patricia Ho from Netflix) - Virtual
How To Become A Data Engineer - Live Data Engineering Career Advice - Virtual
Data Engineering Video You May Have Missed
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Data Observability for Analytics and ML teams
Nearly 100% of companies today rely on data to power business opportunities and 76% use data as an integral part of forming a business strategy. In today’s age of digital business, an increasing number of decisions companies make when it comes to delivering customer experience, building trust, and shaping their business strategy begins with accurate data. Poor data quality can not only make it difficult for companies to understand what customers want, but it can end up as a guessing game when it doesn’t have to be. Data quality is critical to delivering good customer experiences.
Are Model Explanations Useful in Practice? Rethinking How to Support Human-ML Interactions.
Model explanations have been touted as crucial information to facilitate human-ML interactions in many real-world applications where end users make decisions informed by ML predictions. For example, explanations are thought to assist model developers in identifying when models rely on spurious artifacts and to aid domain experts in determining whether to follow a model’s prediction. However, while numerous explainable AI (XAI) methods have been developed, XAI has yet to deliver on this promise. XAI methods are typically optimized for diverse but narrow technical objectives disconnected from their claimed use cases. To connect methods to concrete use cases, we argued in our Communications of ACM paper [1] for researchers to rigorously evaluate how well proposed methods can help real users in their real-world applications.
End Of Day 78
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
 | A guest post by
|
One Remark:
On the subject of data cleansing for ML Pipelines, the article states: "While data engineers do an initial cleaning, data scientists take it further to ensure accuracy and usefulness."
From my own experience as a data engineer in the real estate sector, I can say that we often perform extensive cleansing and enrichment of the data to ensure that it can be used not only by data scientists, but also by other areas such as market research, e.g. to analyze price trends in recent years.
The cleansing, which is independent of the application purpose, is intended to ensure that the data is cleansed and enriched uniformly so that the results of the various application-areas are consistent.
I think it's important to remember (or acknowledge) that before the ML Engineer title (and now AI engineer) became 'sexy' the people doing this work were...data engineers. My first job doing what became ML engineering (and my 3rd overall) was a data engineering role. This likely accounts for the similarities, even though the titles have grown apart in the last 5-6 years. In my opinion, ML engineering and data engineering are siblings with the same core and ancestry, but have their own flavors and cultures now. DE seems even more focused on serving the BI world, while MLE's customers are usually internal R&D teams while bridging the gap between R&D and product engineering.
I also strongly believe that the differences between the two roles in practice are much smaller than posted here, or non-existent (pipelines used in ML workflows can certainly be streaming! MLEs build data pipelines as a matter of course for the ML development lifecycle!), and examining the similarities could be even more instructive than the differences.