
Different Types Of "Data Engineering" Teams
The role of data engineer has morphed drastically in the last decade. A decade ago it seemed like employers thought their data scientists should both be able to calculate eigenvectors and understand how to write MapReduce jobs for Hadoop.
Eventually, this work became more specialized and the term data engineer started to appear more and more. Originally referring to those faithful data practitioners who interacted with Hadoop in its purest form. Then later being assisted by tools such as Flume, Sqoop, and Pig.
As time continued, the role of data engineer started to bifurcate. At larger organizations at least. Perhaps they merely started to fit into the old roles that used to hold their place such as ETL developer. Regardless, individuals and teams began to specialize.
Generally speaking the breakdown at varying-sized companies might look something like the diagram below.

There is far from a perfect set-up when it comes to teams. However, you will want to make sure you balance the work being done, your data quality, output, security, and usability.
I have worked with companies of all sizes and seen some of the combinations above. But what do each of these teams do?
Although it’s not always cut and dry, let’s break down what many of these teams do.
Software Engineer, Data Infra Teams
Some software engineers enjoy working heavily on data infrastructure projects. For example, these engineers like designing and building query optimizers, data catalogs, and or data pipeline solutions.
Solutions that are just focused on storing, processing, and managing all of the data we have been collecting over the past few decades. It can get very meta as they focus more on solutions like data catalogs or security.
One person who I believe has had their career mostly focused on this type of work would be Neelesh Salian. Throughout his career, he has worked on projects that were focused on building tools for other data practitioners. He has contributed to Apache projects such as Spark, Hive, Iceberg, and Hadoop. Ensuring that all of the rest of us, data engineers, analysts, and data scientists, can work with the ever-growing pile of data.
These engineers build the components that will be managed by the next grouping of data-focused engineers.
Data Platform Teams
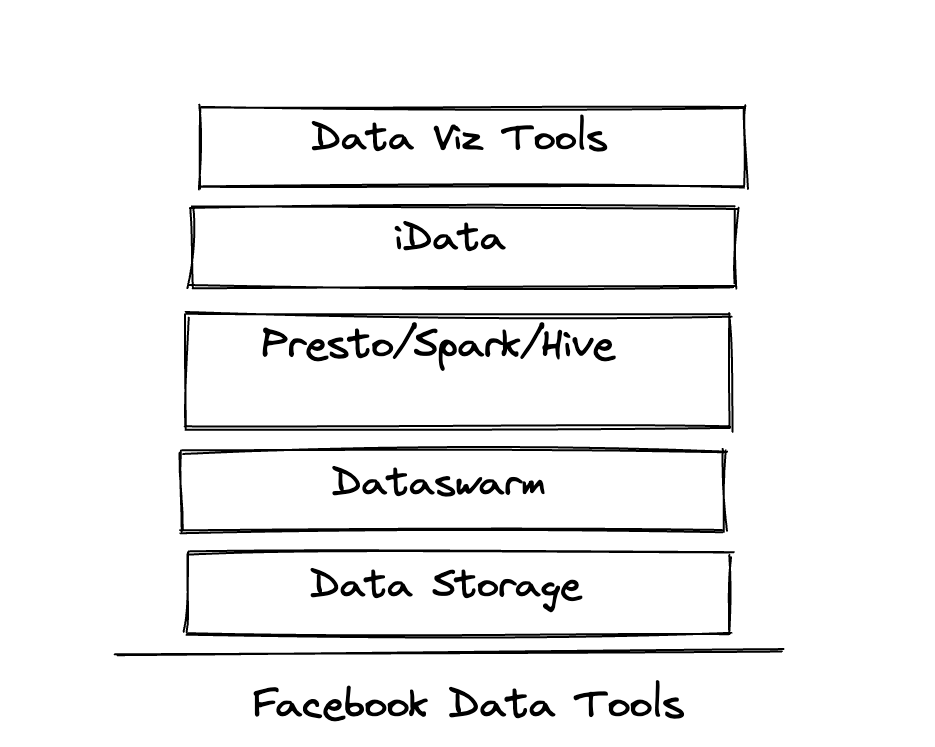
When I worked at Facebook, much of the heavy lifting in terms of managing Presto, the distributed file system, or even our version of Airflow(Dataswarm) wasn’t managed by the data engineers.
At companies with smaller teams, this will often just be a single team called the data platform team. Truthfully, at even smaller companies this will just be a subset of either the data engineering or DevOps team’s responsibilities.
Nuance aside, this team’s focus is managing the infrastructure that other data practitioners use. They keep the lights on so that the likes of us data engineers can do our work. For example, they ensure that as the data grows, and pipelines increase, VMs and workers don’t go down. They are making sure that we have enough storage space and will occasionally act as admins of specific solutions.
Or as GitLab puts it:
The Data Platform Team is both a development team and an operations/site reliability team. The team supports all Data Fusion Teams with available, reliable, and scalable data compute, processing, and storage. - GitLab
While also helping deploy new features and solutions that can help improve the functionality of the data platform.
When I was interviewing engineers for my “What Is A Data Catalog Video” I ran into several examples of data platform engineers who were spinning up data catalogs from scratch. All on top of Kubernetes of course.
All so the data engineers could create and track their data pipelines.
Data Engineering Teams
This is where the roles and responsibilities become even murkier. Besides the obvious differences between data platform engineers, software engineers, and data engineers…
The line between all the other various roles can sometimes seem to cross. For example, if you have ever interviewed for the BI Engineer or the data engineer role at Amazon, then you likely got the exact same study guide(at least 4-5 years ago).
At companies where they have a large enough staff to have a separate data engineering and data platform teams, the data engineers generally focus on parsing data from logs, creating custom data connectors when required, building data pipelines, and building a core data layer. This core layer is often used by the rest of the company to build off of.
At Facebook, this was the team I worked on. We weren’t directly connected to a product. Instead, the data we managed was used by other data engineers along with their product data to develop their analytics and aggregations.
Some of the individuals I interviewed in the last week also referenced that their data engineering team was purely focused on the “EL part of the work”.
I do like being involved in creating the core layer of data and not just extracting data. But to each their own.
In all this madness of data flying around, data access requests coming from every direction, and just a general explosion of sources, someone needs to try to manage all of this chaos to make sure data is being used correctly.
Data Governance Teams
If you haven’t worked at an enterprise then terms like data governance and data stewards can be a little strange. To give a quick answer in terms of what data governance is, you can use the one below.
Data governance (DG) refers to the overall management of the availability, usability, integrity, and security of the data employed in an enterprise. - TechTarget
Of course, about a year or two ago I started to notice that Airbnb started hiring for data governance roles. This was pretty uncommon at most FAANGs/tech for a while. Most FAANG employees I talked to discussed the fact that their data infrastructure was often very mature, but their data governance processes were limited or at least managed independently team by team rather than having one central team.
To counter that all of my enterprise clients have data governance teams. These teams ensure that there are systems and processes in place to ensure data accuracy but also that the data that is being used isn’t abused.
There are a lot of risks companies take on when not incorporating data governance into their data strategy. This includes both risks such as having an employee misuse data and having it become a story in Tech Crunch.
Wait that happened.
All in all, these teams all prepare said data for the final end-users.
BI And Analytics Engineering Teams
Once all the data has been parsed, cleaned up, and in a core data layer. Then there is often more business logic that might need to be layered on top. This could be aggregations, enrichment with product-specific data that is pulled, modeling data, and using business intelligence tools to drive value.
All of this is often handled by a combination of different teams. These could be BI engineers, analytics engineers, data scientists, and or analysts. Of course, there are also roles like report engineers, BI analysts, and a whole other set of roles that all have slight nuances and differences(The fact that I have even lumped BI and Analytics engineering together is going to ruffle some feathers. I did it more out of not wanting to make an exhaustive list of every plausible team).
However, in this assembly line of data, the goal is to take the processed and purified core data sets and make them into something. Whether that's a data set that's further enriched with other data sets, dashboards, models, or operationalized data applications, well that's just all details.
The result is meant to align with business goals(which you should have been thinking about the whole time).
What Kind Of “Data Engineer” Are You?
Data engineering and data infrastructure offer many roles that require a very diverse set of skills. As companies grow their need for increased specialization will generally increase.
Each of these roles tends to build off each other, one building the infrastructure, another managing it, and still, others using it. The reason I wrote this article was two-fold. To help give some insight into how some companies set up their data teams. But also to let those out there who may feel like they only have 1-2 options in terms of data roles know there are plenty of other options.
What other teams should we include?
What’s the future of data catalogs? Active Metadata.
Embed enriched context wherever you are, whenever you need it.
Traditional approach to data catalogs doesn’t work anymore. Instead of just collecting metadata from the rest of the stack and bringing it back into a passive data catalog, active metadata platforms make a two-way movement of metadata possible, sending enriched metadata back into every tool in the data stack.
Atlan is a pioneering Active Metadata Platform for the modern data stack. It stitches together metadata from various sources (Snowflake, dbt, Databricks, Looker, Tableau, Postgres, etc.) to create a unified data discovery, cataloging, lineage, and governance experience across all your data assets, from columns and queries to metrics and dashboards.
A Leader in the Forrester Wave™️: Enterprise Data Catalogs for DataOps in 2022, Atlan powers modern data teams at companies like Plaid, Postman, Unilever, Ralph Lauren, and WeWork.

Learn more about Atlan or download the Forrester Wave Report to read more about this evolving category.
Special thanks to Atlan for sponsoring this newsletter!
Video Of The Week: What is A Data Catalog
Join My Data Engineering And Data Science Discord
Recently my Youtube channel went from 1.8k to 46k and my email newsletter has grown from 2k to well over 25k.
Hopefully we can see even more growth this year. But, until then, I have finally put together a discord server. Currently, this is mostly a soft opening.
I want to see what people end up using this server for. Based on how it is used will in turn play a role in what channels, categories and support are created in the future.
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Super Tables: The road to building reliable and discoverable data products
Many companies, including LinkedIn, have experienced exponential data growth ever since the Apache Hadoop adoption a decade ago. With a proliferation of self-service data authoring tools and publishing platforms, different teams have created and shared datasets to address business needs quickly. While the use of self-service tools and platforms was a scalable and agile way to unlock data value by various teams, it introduced multiple issues: 1) multiple similar datasets often led to inconsistent results and wasted resources, 2) a lack of standard in data quality and reliability made it hard to find a trustworthy dataset among the long list of potential matches, and 3) complex and unnecessary dependencies among datasets led to poor and difficult maintainability.
Build Data Engineering Projects, with Free Template
Setting up data infra is one of the most complex parts of starting a data engineering project. If you are overwhelmed by
Setting up data infrastructure such as Airflow, Redshift, Snowflake, etc
Trying to setup your infrastructure with code
Not knowing how to deploy new features/columns to an existing data pipeline
Dev ops practices such as CI/CD for data pipelines
Then this post is for you. This post will cover the critical concepts of setting up data infrastructure, development workflow, and a few sample data projects that follow this pattern. We will also use a data project template that runs Airflow, Postgres, & Metabase to demonstrate how each concept works.
By the end of this post, you will be able to understand how to set up data infrastructure with code, how developers work together on new features to data pipeline, & have a GitHub template that you can use for your data projects.
End Of Day 57
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
If you want to learn more, then sign up today. Feel free to sign up for no cost to keep getting these newsletters.
Thanks for sharing Ben. In terms of data governance I’ve observed that this is typically neglected in start-ups, but then becomes increasingly imported as the company grows to the point where one of the data engineers takes on this responsibility building out the first capabilities and workflows internally. As the company grows further this does not scale anymore, and a dedicated data governance team is built out which then looks for third party solutions. However, it will be key that the data teams remains involved.
Great piece. It is nice to see the same sort of patterns I have seen in my experience and even how my teams evolved well-articulated in this systematic approach. Kudos for helping others make sense of it!