Building Data Reliability Systems Is Hard
Recently I have found myself listening to engineering disaster podcasts and videos.
And I mean physically engineered structures and systems. This includes nuclear reactors, bridges and chemical plants.
These are real disasters. Disasters that don’t lead to accidental double billing but instead tens if not hundreds of lives being lost and impacted.
In most of these examples, there were a lot of similar causes. For example, some of the common causes were:
Poor notifications or warning systems
Lack of maintenance and QA
A Large amount of manual processes
Poor documentation and best practices
And replacing experienced staff with junior employees
Now software systems general don’t have cost lives to the same extent. However, it’s hard not to draw parallels to the work of data professionals. Yes the failure in our systems will rarely have the same impact.
We create virtual systems that can become very complex very fast. But these systems are just that. Virtual.
They rarely impact humans directly. Instead, they often cost companies a large amount of money when they fail.
For example, here is what some DAGs can look like in Airflow.
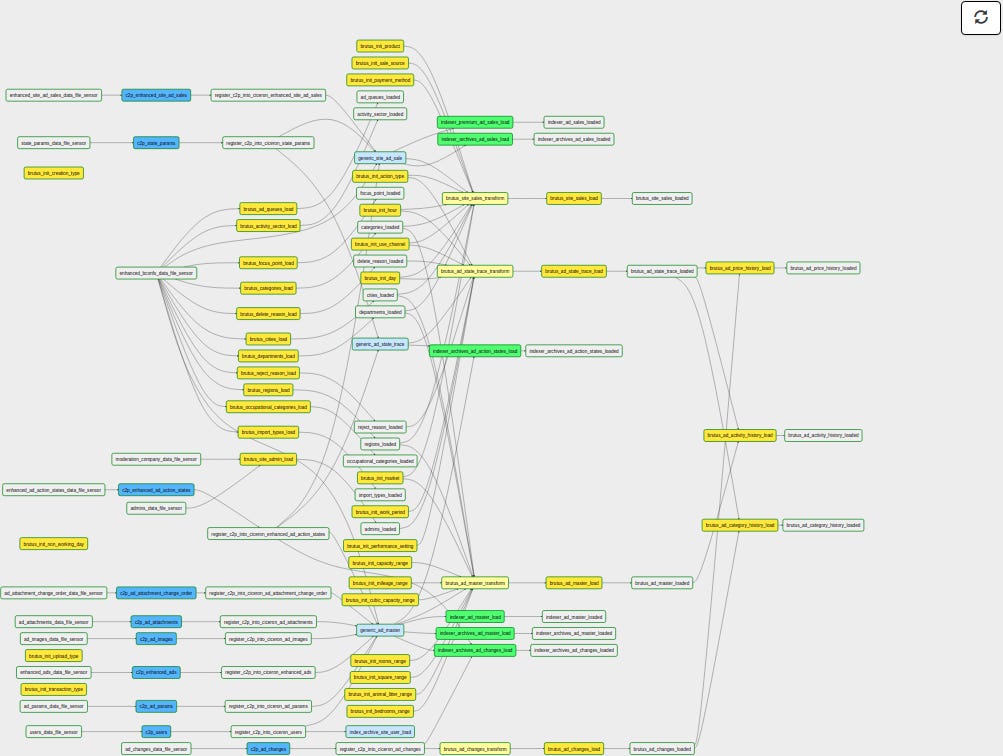
This complexity inevitably breeds the need for better data quality and reliability systems. Because complexity breeds a higher likelihood of failures.
What Does Failure Look Like For Data Systems?
Failures in the data world tend to look very different compared to physically engineered systems.
However, data system failures still cost companies millions of dollars annually. They still create headaches and issues that need to be solved and Gartner has calculated that poor data quality costs companies upwards of $12.9 million a year.
Poorly managed data pipelines, tables and systems will cost your company one way or another.
What this often looks like in practice is:
Investing in bad decisions and strategies
Mis-reporting financial statements to regulators
Improperly billing clients and customers
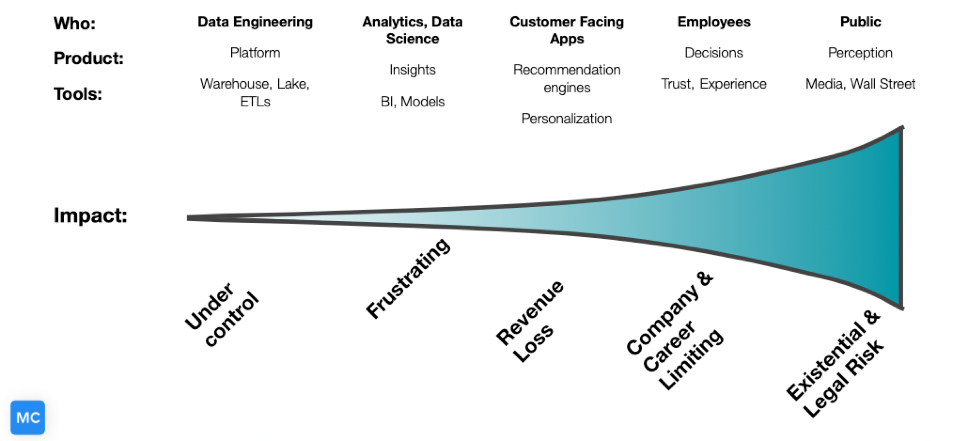
Monte Carlo put out a great graphic that kind of helps depict the possible cost/impact of bad data shown below.