
Data Warehousing Essentials: A Precursor
Looking Into Dimensional Modeling
Over the past few months, I have written about data modeling several times.
So I wanted to continue down that path and go through some of the basics in terms of dimensional modeling as well as discuss an example of a common data modeling decision you often have to make.
Now like anything, picking a specific data model or design pattern is a decision that shouldn’t just be made because you read an article. There are pros and cons to every decision, and it's important to know why so you can confidently get past the “it depends” phase.
Let’s start by going over Kimball’s goal of Data Warehousing(and to be clear there are plenty of other authors and individuals you can dig into that discuss data warehousing and dimensional modeling).
The Goal of a Data Warehouse
Before we delve into the details of modeling and implementation, it is helpful to focus on the fundamental goals of the data warehouse. The goals can be developed by walking through the halls of any organization and listening to business management. Inevitably, these recurring themes emerge:
-“We have mountains of data in this company, but we can’t access it.”
-“We need to slice and dice the data every which way.”
-“You’ve got to make it easy for business people to get at the data directly.”
…
-“It drives me crazy to have two people present the same business metrics at a meeting, but with different numbers.”
-“We want people to use information to support more fact-based decision-making.”
These goals have been echoed for decades. In fact, I am sure if you read a few articles written in the past few months, some of these points will come out as if they were being listed for the first time.
It’s almost as if we are in a continuous cycle in the data world, never truly escaping the same set of problems.
But let’s get past these problems for now and look at an example of a design decision you might need to make when you are focusing on using dimensional modeling.
Example of Data Modeling Decisions
When you’re designing your data analytics platform(there are so many types these days that it's hard to just write “data warehouse), there are a lot of important design decisions that you’ll need to make. These decisions can lead to better or worse performance, unexpected costs, and change the general usability of your data.
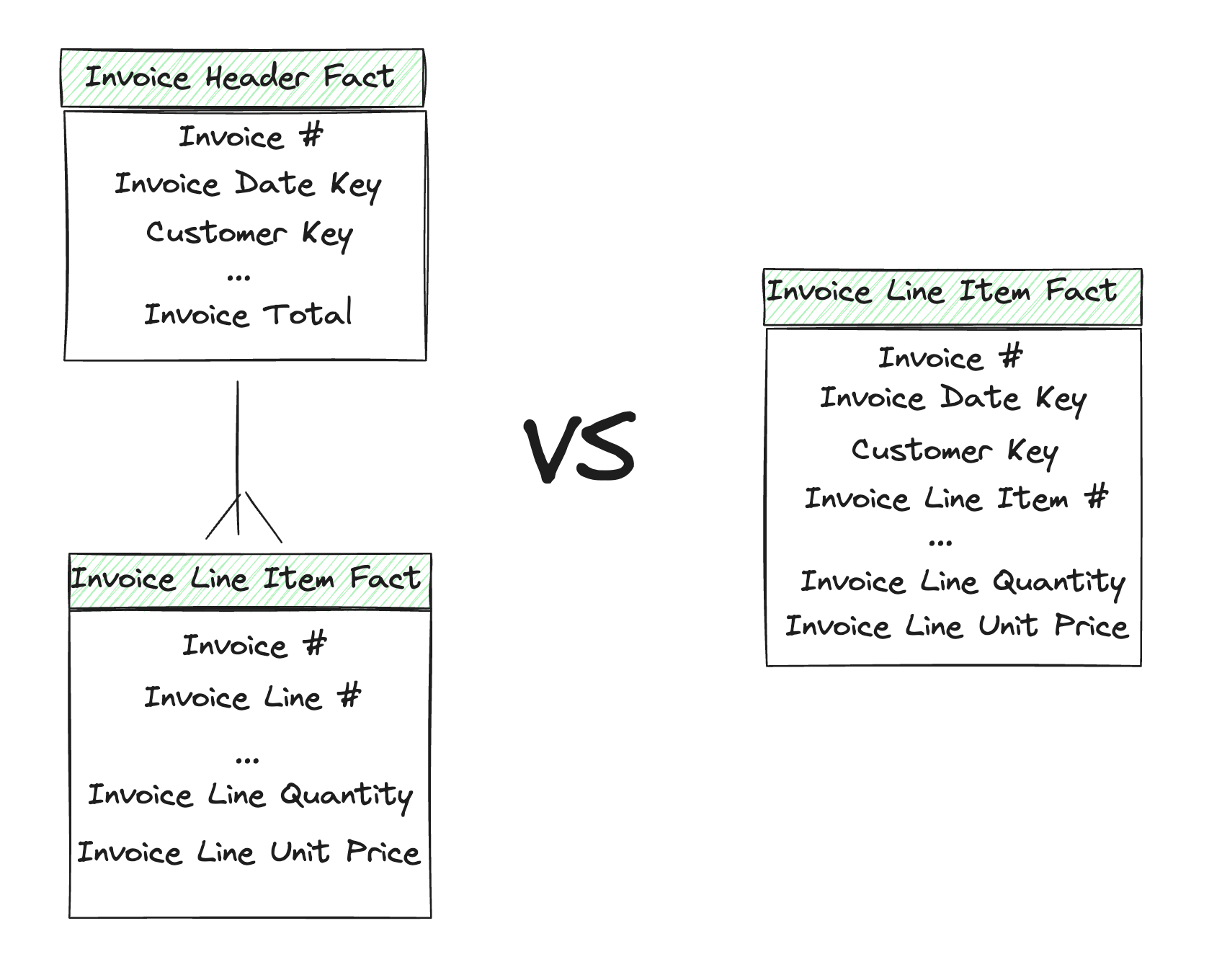
One example that you’ll likely run into as a data professional is having to data model a header and line item table.
This situation happens all the time; if you’ve got invoices in your data warehouse, then you’re likely very familiar with the concept of headers and line items.

So how do you model this data? There are two methods outlined below. In the first example your data is normalized creating both a line item and header fact table.
Quick Pause - As 2024 is coming to a close I am planning a lot more content for 2025. In particular I want to give paying subscribers even more. Meaning private AMAs and videos discussing the data industry.
If you’d like to support this newsletter and get access to future paid content, then until December 31st 2024 you can use the discount below to get 55% off forever.
Thanks all!
The line item and header will need to join together to get all the information in this method. This approach is often discouraged, at least by Kimball who points out several issues caused by this modeling pattern. In particular, joining two large fact tables is computationally expensive and might not return depending on the database you’re running on.
Instead, his suggestion is to denormalize the two tables into one. With this design, you’ve now got to be wary of double counting the invoice number as it might show up multiple times for each line.
But as I said before, this is a decision that shouldn’t just be made. I have seen both work successfully.
Now just in case some of these terms are new to you, such as fact table, I did want to dedicate some of this newsletter to discussing the basics of different types of tables in a dimensional model.
Different Types Of Tables
Fact Tables
“A fact table is the primary table in a dimensional model where the numerical performance measurements of the business are stored.” -Ralph Kimball
These tables contain the quantitative data for analysis and are typically transactional. For example, these transactions often represent sales, shipments, calls made, clicks, etc. If you’re keeping to a very strict data warehouse approach(most data warehouses I see don’t) then fact tables generally have two types of columns: measures and foreign keys to dimension tables.
Measures are the numerical data (such as quantity sold, revenue, etc.) that analysts want to sum, average, or perform other calculations on. The foreign keys are the connections to the dimension tables.
Dimension Tables:
“Dimension attributes serve as the primary source of query constraints, groupings, and report labels. In a query or report request, attributes are identified as the by words. For example, when a user states that he or she wants to see dollar sales by week by brand, week and brand must be available as dimension attributes.” -Ralph Kimball
These tables are descriptive attributes related to fact data. They provide context to the data in the fact tables, such as time, location, product details, customer information, etc.
Dimension tables are often denormalized, meaning they might contain redundancy and usually include a wide variety of attributes to allow for flexible analysis. For example, a product dimension table might include not just an ID and name but also category, size, color, and other attributes that could be useful for analysis.
Bridge Tables (or Link Tables)
“These are used in “many-to-many relationships” between dimensions. For instance, if you have a scenario where multiple products can be in different promotions at the same time, a bridge table would be used to manage this relationship. “ -Ralph Kimball
Another common example used in most articles and in Kimballs’ books is healthcare and a patient’s diagnosis, which can have more than one diagnosis at a time. In turn, you’ll often see a bridge table used (See the model below).

Many data modelers try to avoid implementing too many bridge table situations as they can add a lot of risk in terms of miscounting or joining across the tables.
Role-Playing Dimension Tables
“Role-playing in a data warehouse occurs when a single dimension simultaneously appears several times in the same fact table.” -Ralph Kimball
A single physical dimension can be referenced multiple times in a fact table, playing different roles. For instance, a date dimension might be used in one fact table as the order date, shipping date, and delivery date. This is likely the most common example of a role playing dimension and honestly most people probably still just reference it as a dimension table.
Stay Tuned For More
Data modeling still plays an important role in today's modern data world, and the decisions you make impact the cost of computing, the data’s usability, and more. With that, I hope this refresher was helpful.
If you want me to write more about data modeling in the future, comment below and let me know!
Thanks for reading.
Serverless CDC for Snowflake, Databricks, and any query engine - Live webinar

Struggling to ingest data with minute-level freshness for Snowflake, Databricks, or your data lake? In this webinar, you’ll learn how Onehouse enables you to easily ingest with CDC from any data source at scale, in minutes, and at a fraction of the cost. Data is ingested in a universal data lake that can be queried with Snowflake, Databricks, and every popular query engine. Save your spot today!
State Of Data Engineering And Infrastructure 2023!
If you missed it, last year we had well over 400 people fill out a survey to help provide insights into the data world. If you’re interested in participating, then please check out the survey here!
We would love to have 1000 people fill out the survey this year so we can share with our readers. You can also check out the articles from last year here.
Join My Data Engineering And Data Science Discord
If you’re looking to talk more about data engineering, data science, breaking into your first job, and finding other like minded data specialists. Then you should join the Seattle Data Guy discord! We recently passed 4000 members!
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Uber: GC Tuning for Improved Presto Reliability

Uber uses open-source Presto to query nearly every data source, both in motion and at rest. Presto’s versatility empowers us to make intelligent, data-driven business decisions. We operate around 20 Presto clusters spanning over 10,000 nodes across two regions. We have about 12,000 weekly active users running approximately 500,000 queries daily, which read about 100 PB from HDFS. Today, Presto is used to query various data sources like Apache Hive, Apache Pinot, AresDb, MySQL, Elasticsearch, and Apache Kafka, through its extensible data source connectors.
End Of Day 111
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
I’m finishing The Kimball Group Reader. Interesting to read articles spanning 1995 to 2015. Kimball still as relevant as it was then, despite faster hardware.
Good introduction, from the data mart, Kimball perspective. In data warehouses with which we’ve been involved, we generally look to Devlin, Inman and Imhoff as well as Kimball. Rather than top-down or bottom-up, we generally iterated our models from the middle-out. The essentials of matching organizational goals to technical architecture are even more important for the foundational knowledge as groups look towards data vaults, data fabric and [Dehghani] data mesh approaches. Your article helps a lot.