
Anyone Else Struggling to Keep Up With Data Tools
You can’t outlearn the internet, but you can learn what matters
Hi, fellow future and current Data Leaders; Ben here 👋
I was skimming through the data engineering subreddit again and I found a post that I believe we can all relate to. It was titled “Are You Guys Managing To Keep Up”. Who hasn’t felt that way in the data world. Every day there is some new technology we have to learn or design approach that is being tested. So how do you keep up?
That’s what we’ll be discussing in this article!
But before we jump in, I wanted to share a bit about Estuary, a platform I've used to help make clients' data workflows easier and am an adviser for. Estuary helps teams easily move data in real-time or on a schedule, from databases and SaaS apps to data lakes and warehouses, empowering data leaders to focus on strategy and impact rather than getting bogged down by infrastructure challenges. If you want to simplify your data workflows, check them out today.
Now let’s jump into the article!
Are you managing to keep up?
One of the truths I’ve realized about working in the data world, and really the technology world, is that you can work a lifetime and never ever touch massive swaths of technologies.
Like Sisyphus, you could spend every day pushing the boulder of new technology up the hill, only to have it roll down back to the bottom.
You could only work on Snowflake or Databricks, and in twenty years, never have touched the other. Okay, that might be unlikely, given how some companies set up their data stacks. Somehow, even smaller companies are finding a way to use both. Probably some classic vendor-driven development.
Still, if you’ve only worked in big tech, you might never see some of these solutions while working on unique tools that are developed in-house.
So how do you actually keep up?
That’s what the poster below asked the data engineering subreddit.
There are thousands of articles to read, never-ending tutorials, and you’d probably be more likely to climb every 14er in Colorado prior to learning every technology.
But as a consultant, part of my job is to do just that. After all, people often ask me what technology will be the best fit for their needs, and then, I’ll have to implement it. So I am acutely aware of various technologies and their pros and cons(past what they’d tell you in an article.
So I’ll go over how I, like you, try to keep up.
The Tools Will Change - The Fundamentals Won’t
Let’s start with the basics.
A shiny new technology might sound promising, but if it hasn’t been proven in production, it often ends up being replaced by a more established alternative.
It’s why no matter how many times people try to kill SQL, it sticks around, whether you hate or love it.
So start there.
Start with the basics that haven’t changed.
You’re going to have to use SQL, maybe it’ll be auto-generated, but it’ll still be lurking somewhere in the stack. Sooner or later, someone will need to pop the hood and look at the raw queries.
Honestly, I wouldn’t be surprised if vendors start making their systems like modern cars, closed off, opaque, and nearly impossible to diagnose without proprietary tools. You’ll open it up and have no clue what’s going on without a vendor-certified debugger(that costs $10,000 a month to have access to). And maybe even then, you’ll still be stuck waiting for support to fix it. That’ll be a sad day.
I do hope we can always go into systems and understand the basics.
Beyond understanding the basics, you need to understand your why. Why did you pick your technology? Was it because of hype or because you actually needed it?

Stop Overwhelming Yourself - Go Deep On Just A Few Technologies
Very few people can keep up with all the technology that is being developed and released.
Oh, you’ve learned Databricks, great. Now there is a new compute option and maybe a new way to run data workflows, etc. You'd better keep up.
If you try to master every new technology, the truth is, you probably won’t. It’s like trying to become an expert in jujitsu, cooking, engineering, construction, and plumbing all in 6 months.
Will you understand some surface-level concepts in each, probably. But the individuals who focus on 1-2 will go far beyond that.
Instead of trying to keep up with everything:
Pick 1-2 technologies to go deep on this year.
Learn the fundamentals behind them, not just tutorials, but how they actually work under the hood.
Understand the trade-offs. Every tool solves a problem but introduces new ones. If someone says otherwise, they're probably selling it.
Ask the hard questions:
Why was this built?
What real pain does it solve?
Does my team actually have that problem?
Yes, you can parrot the benefits that everyone else tells you. But every tool you pick has some trade-off, and any vendor that tells you otherwise is lying.
“Every shiny new tool is built on old pains and lessons. Learn those lessons, not just the surface syntax.”
Have Fun And Build Side Projects

As you’re picking your 1-2 technologies, you’ve got to do more than just read about the fascinating world of parquet files and how they are structured. You need to do something with that knowledge.
This doesn’t have to be limited to building ETL pipelines on top of yet another data warehouse solution. You could focus on creating a website to display the data you’re pulling or deploying a model.
These projects never even have to see the light of day. I don’t think you need to complete every side project you take on; the goal is to learn if you’re lucky and can turn every side project into a 250k side-hustle, great.
If it’s just a fun little project, also great.
The real challenge?
Getting started. So if you’re stuck here, here are some tips:
Start Smaller Than You Think - If you’re working a full-time job, you likely have a lot less free time than you think. So be reasonable with your side projects. You can always build on top of a small project.
Define a Clear End Goal - What do you want out of the project? Are you just trying to learn or build something useful?
Don’t Wait for the Perfect Idea - If you want to overcome writer's block, write, write a free-flowing anything. And if you can’t find the perfect project, do something simple.
Create a Public Accountability Mechanism - There are numerous ways to ensure others hold you accountable. You can find learning groups or post on LinkedIn or other social platforms to share your progress. Anything that helps you stay motivated to learn, even when you’re not feeling it.
Remember Why You’re Doing It - That’s it.
Overall, you’ve just got to start.
What Does My Employer Need
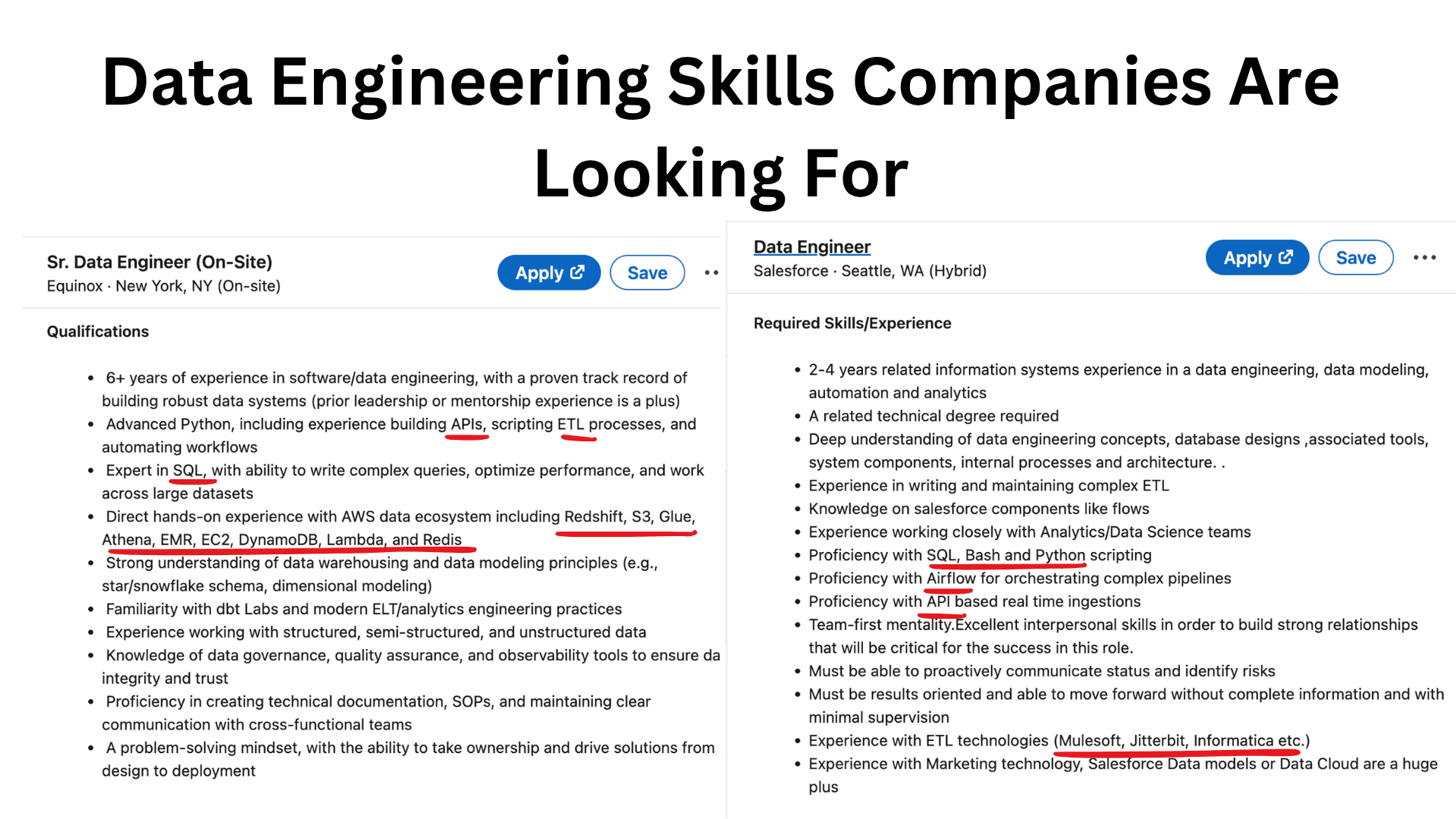
Side projects are great. But in my experience, the best way to learn any tool is to learn on a real project where there are real consequences and you have to deal with a lot more than a basic configuration set-up.
“The best way to learn is to be responsible for something that matters.”
So if you want to level up, start by looking around:
Is your team considering a migration from SQL Server to Snowflake? Volunteer to lead the initial research or proof of concept.
Is there buzz about Iceberg or Delta Lake at your company? Be the one who breaks it down and figures out if it’s actually a good fit.
Is nobody owning your Airflow deployment? Raise your hand.
These moments are everywhere, but most people avoid them because they involve uncertainty, failure, and extra effort. But that’s exactly where the growth is.
And here is something else you’ll pick up while you’re going through the process of owning those projects.
You’ll learn how to learn really fast.
Write To Solidify Your Understanding
I am biased, but writing will always be a great way to cement your knowledge. You don’t have to write a public blog, but keeping a journal or some personal notebook is a great way to realize you don’t know a topic as well as you do.
You’ll put your pen to paper or your fingers to keys and suddenly ask, huh, wait…
“Is Snowflake actually decoupled storage and compute and what does it look like under the hood?”
“Can I explain what makes Delta, Hudi, and Iceberg different without Googling it?”
“How does Airflows Kubernetes Pod Operator work?”
Writing exposes where you’re likely just hand-waving your understanding. Where you just assume you understand a topic.
When you’re sitting there, frozen, unable to dig any deeper into your own knowledge of a subject, you’ll realize how much more you still have to learn.
Read to Expand Your Perspective
And on the flip side of writing, is well read.
There are so many great technical and engineering leadership blogs that you can learn from. Will reading these blogs bestow upon you the capabilities to build data infrastructure at the level of a petabyte processing large big tech organization.
No(nor will many of you have to do that).
After all, many of those projects likely had multiple individuals involved, not to mention budgets that are rival the the market valuation of a medium sized business. The real crux of many of these projects are all in the details, details you’ll never see or experience.
But you never know where inspiration for a new project will come from.
If you’re stuck not knowing which blogs or newsletters to check out, here are a few:
- Blog
- Blog
DataExpert with
Final Thoughts
Keeping up with every new technology or feature that is released is likely a fool's errand.
You’re one person competing against an army of intelligent developers building out hundreds of open and closed source projects.
So like many things, if you view “trying to keep up” a massive task list that never ends, you’ll likely become overwhelmed and either never dive deep into any topic or never start learning at all.
Instead, I’d recommend you:
Start with the fundamentals that will be here in one form or another (SQL, Python, systems thinking).
Pick 1–2 technologies to go deep on each year, based on what you find interesting or what your company genuinely needs.
Learn by doing. Side projects and on-the-job experiments will teach you more than any tutorial ever will.
Reflect on what you learn. Write it down, explain it to others, or just journal it for yourself. That’s how you identify the gaps.
Read with intention. Not to become an expert overnight, but to get ideas, exposure, and inspiration.
Your career in data likely will have plenty of transformations and the tools you’re learning today will likely be different than the tools you’re using 10 years from now.
Pace yourself and give yourself a little grace, and as always, thanks for reading.
Upcoming Data Events
Join My Technical Consultants Community
If you’re a data consultant or considering becoming one then you should join the Technical Freelancer Community! We have over 1900 members!
You’ll find plenty of free resources you can access to expedite your journey as a technical consultant as well as be able to talk to other consultants about questions you may have!
Articles Worth Reading
There are thousands of new articles posted daily all over the web! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Bubble Wrap, Duct Tape, and the Struggle for Deep Work in ML Engineering
By
Last week,
’s post made me reflect on a lesson I learned from an E7 at Meta.He was one of the most effective ML engineers I knew—not just in terms of output, but in how he approached his work.
His secret was to plan his week in advance, ruthlessly blocking out time for the things that mattered. He knew that in ML engineering, there are always a million urgent things pulling at your attention—bugs, model drift, data inconsistencies, stakeholder requests. But he also knew that if you don't carve out space for deep work, your career turns into an endless cycle of “bubble wrap and duct tape”.
Deep Work is a term coined by Cal Newport, referring to the ability to focus intensely on cognitively demanding tasks. It’s the kind of work that moves the needle—designing a new ML model architecture, experimenting with novel approaches, reading research papers, or rethinking how data pipelines should be structured. It’s the opposite of shallow work, which is reactive, scattered, and often the default mode in fast-moving environments. Shallow work is by far the most pervasive.
MongoDB Is Great For Analytics; Until It's Not
In the last 12 months, I have dealt with three different projects that involved moving companies' analytical workloads, from MongoDB to analytical platforms like Snowflake, BigQuery. Additionally, there was one project where I had hoped to integrate a solution like Rockset or Tinybird since they can quickly be implemented without creating an entire data warehouse(in the end, they still went with Snowflake).
The point is there are many instances where a company uses an transactions database to support applications and try to generate analytics.
Truthfully, I know writing an article like this will anger MongoDB experts, fans, and engineers.
I get it.
You like MongoDB and you think everyone should learn MQL(no not Marketing-Qualified Lead) and use MongoDB for their analytics workloads.
End Of Day 189
Thanks for checking out our community. We put out 4-5 Newsletters a month discussing data, tech, and start-ups.
If you enjoyed it, consider liking, sharing and helping this newsletter grow!
Jut what I wanted to read today!
Great read, love it. And it's true, it's getting harder to keep up every year I feel. Thanks for the shout-out, too, much appreciated.