
MongoDB Is Great For Analytics; Until It's Not
In the last 12 months, I have dealt with three different projects that involved moving companies' analytical workloads, from MongoDB to analytical platforms like Snowflake, BigQuery. Additionally, there was one project where I had hoped to integrate a solution like Rockset or Tinybird since they can quickly be implemented without creating an entire data warehouse(in the end, they still went with Snowflake).
The point is there are many instances where a company uses an transactions database to support applications and try to generate analytics.
Now truthfully, I know writing an article like this will anger MongoDB experts, fans, and engineers.
I get it.
You like MongoDB and you think everyone should learn MQL(no not Marketing-Qualified Lead) and use MongoDB for their analytics workloads.
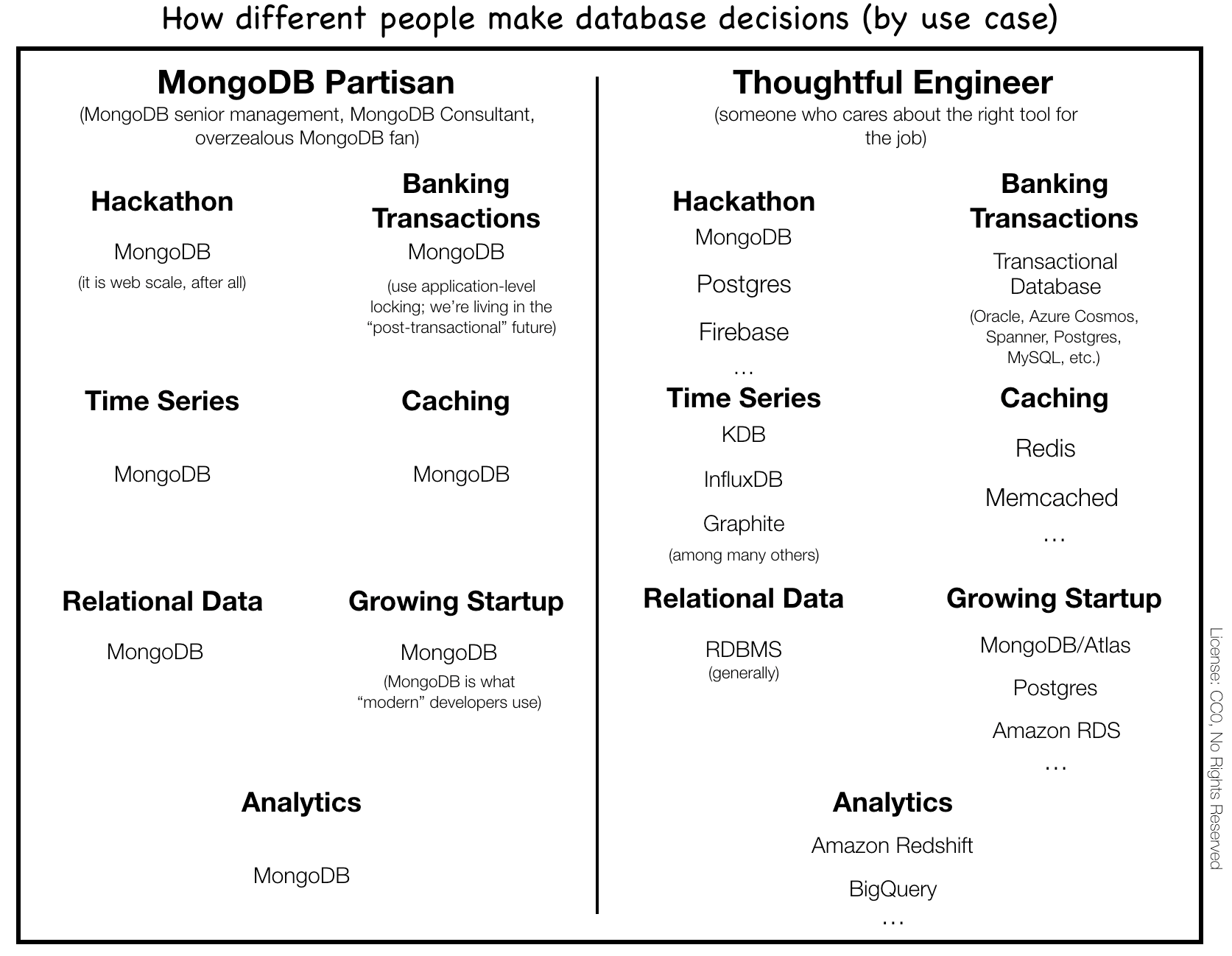
I am sure you have even, in some cases, implemented it at plenty of companies.
The problem is that MongoDB does let you get to a certain point in terms of running analytics on it.
It’ll get you to a point.
But then….
Your engineering team might be too deep once they start hitting roadblocks.
I have seen; it’ll be a very expensive rewrite in order to provide the functionality you’d like to add in.
Now perhaps I am biased. I am a consultant; one reason people reach out to me is because they feel stuck or unsure of how to move forward.
So for every three companies that reach out asking how to move their analytics workflows, there might be an X amount running analytics successfully on MongoDB.
All that aside, let’s go over the reasons why I have found MongoDB to be a poor choice to run your analytical workloads.
It’s Not Standard
I once had a friend spend all summer re-training themselves on a more efficient keyboard configuration (instead of the standard QWERTY keyboard). There are many arguments against QWERTY being the most efficient layout.
But QWERTY is standard.
Now to be clear, in no way am I suggesting that MongoDB is a more efficient analytics engine than some form of analytics platform.
I am leaning more heavily into the obsession that we technophiles have to make things work the way we believe they should for one reason or another. This could be improved performance, reduced costs, or maybe just because we think its cool
In this case, my friend was indexing on efficiency vs. easy-to-adopt/standardization.
So when I hear of sales engineers and account executives trying to convince data scientists and engineers that they should learn MQL to run their queries…it's hard not to pause for a moment( I have now heard this happen at several fortune 500 companies).
Why would someone learn a language to perform analytics when it's rarely relied upon?
It won’t benefit their career, and it likely doesn’t provide better performance, not without a lot of understanding of how to model and manage data in MongoDB.
This leads to my next point. Using MongoDB as your data analytics layer often limits who can work on data analytics.
You Limit Who Can Work On It
I am more than sure that some teams are running their analytics on MongoDB successfully. It probably required a lot of very specific knowledge and skills that limit who can work on the data.
MongoDB puts heavy reliance on the data engineering capabilities of software developers and the resultant solution is often brittle -
Andrew Bourne - CTO and Advisor
As Andrew put it, you’ve now limited who can work on your data to a select few, and you likely, once again, had to rely on a non-standard data model. This means that as you hire new individuals, they will both have to be software engineers that like working on data engineering-like problems and deal with data models that don’t have as much literature or support.

You also limit how much analysts can do in terms of analytics. Instead of being able to freely work in methods they might be accustomed to like SQL, Excel, or Pandas, which often translates into clear tables, they might have to use a more rigid tool that limits how much they can actually do.
Now you can connect directly to MongoDB with most of these technologies, and as I have discussed in prior articles, it can make sense to run your initial analytics without developing an ETL/ELT.
But, as your companies grow, you’ll quickly discover that there is a reason companies put ETLs and data governance in place.
If you don’t believe me, just read Airbnb’s 2018 article, where they initially tried to reduce the need for data engineering only to bring it back with an increased focus. I have seen and heard many companies trying to eliminate DEs. We have been essentially doing that since I started with data lakes.
They promised schema-on-read…and all that proved was that you will eventually need data engineers or some form of process that owns and manages all the complex processes that get developed to provide analytics to the business. Now we see terms like “Zero-ETL” floating around, and I feel like it’s the same promise.
Your data scientists and analysts can now access your data even faster. It’s not integrated with any other data source and it may require them to parse arrays and deal with data structures unfamiliar to them.
But hey, they can access it live.
All in all, I do want to be clear, there is always nuance and this article is not meant to hate on any transaction system being used for analytics.
There Is Always Nuance
As a consultant, the one thing I will always try to do is understand everyone’s use case. While a data warehouse might make sense for one company, a light SQL layer that sits on top of your MongoDB or Postgres instance might be better for others.
That’s why I am not opposed to solutions like Rockset or Tinybird; they can help sit on top of your transactional databases and provide analytics and allow you to integrate said analytics into your apps through APIs.
In the same way, it's not uncommon that early on, in your company's analytics journey, you build basic queries on a replica of your transactions database. Whether that’s MongoDB, Postgres or MySQL.
Again, this makes sense. More than likely, you don’t have the budget or time to think about data as a separate entity from engineering in the early development stages of a company. Thus, the software engineers must help perform any analytics requested by the business team.
Why move them out of where they are comfortable, and why waste time duplicating your data into another database? I generally lean towards keeping systems simple as long as possible. Even if it means your resume looks a little less exciting.
But as the demands of the business grow, the need for more data to enrich your analytics and the complexity of the data asks increases. Getting stuck on data models and databases unfamiliar to analysts doesn’t put you in a great spot.
In the end, your team will likely need to invest in solutions that focus on making data analytics easier.
It Works Until It Doesn’t
It’s easy to see how companies can start to rely on MongoDB for analytics. It works until it eventually limits a company either by the end-users who can actually write queries and build data infra on top of it or by making it difficult to really drill into complex questions. But this is coming from someone on the data side.
If you’d like to read a far more thoughtful piece that covers MongoDB as a whole from someone that has been in tech longer, then you should read the article Why Did So Many Startups Choose MongoDB? It’s a great look into the technology space as a whole while focusing on an individual component (MongoDB). In particular, I enjoy the section Handling Hype. I believe we can all learn a lot from this section, but here is an snippet:
“Sadly, there’s no simple empirical test that can help you divine say a Rails in the late 2000s or a Node/Express in the early 2010s (actual changes) vs. a NoSQL in the early 2010s or Hadoop in the late 2000s (primarily hype, especially for small companies).7 But calling bullshit is easier than you think.
I’ll suggest a simple three-part process (PAT) when assessing hyped technologies:
Problem: Understand your problem deeply
Assess: Critically assess claims in potential solutions
Tradeoffs: Weigh tradeoffs in the short and long term, rather than thinking about good vs. bad”
-Nemil Dalal Developer Products at Coinbase
Or perhaps the shortened version.

Overall, thanks for reading, and I will see you in the next one.
The Harsh Reality of Being a Data Engineer
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Building Real-time Machine Learning Foundations at Lyft
In early 2022, Lyft already had a comprehensive Machine Learning Platform called LyftLearn composed of model serving, training, CI/CD, feature serving, and model monitoring systems.
On the real-time front, LyftLearn supported real-time inference and input feature validation. However, streaming data was not supported as a first-class citizen across many of the platform’s systems — such as training, complex monitoring, and others.
While several teams were using streaming data in their Machine Learning (ML) workflows, doing so was a laborious process, sometimes requiring weeks or months of engineering effort. On the flip side, there was a substantial appetite to build real-time ML systems from developers at Lyft.
What is Pinecone AI? A Guide to the Craze Behind Vector Databases
Vector databases like Pinecone AI lift the limits on context and serve as the long-term memory for AI models. They specialize in handling vector embeddings through optimized storage and querying capabilities.
Alright, let’s do this one last time.
Vector embedding is a technique that allows you to take any data type and represent it as vectors.
But it’s not just turning the data into vectors. You need to be able to perform actions on this data without losing its original meaning.
To save the meaning of data, you need to understand how to produce vectors where relationships between the vectors make sense.
You need embedding models to do this. These are neural networks with the last layer removed. So, instead of getting a specific labeled value for an input, you get a vector embedding.
End Of Day 87
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
I’m fond of staying with Postgres until it starts to hurt. You can bring in data using foreign data wrappers and use material views for most things.
Makes a lot of sense. Thanks for sharing your experience.