


Vendor-Driven Design - The Role Vendors Play In Shaping Data Best Practices And Standards
What if I told you that many of the concepts you believe are best practices and standards in the data and tech world are lies?
Ok, lies is too strong of a word.
But they are heavily influenced by vendors.
Don't believe me?
Think about T-SQL and PL/SQL. For those who are new to the data world, those were Microsoft's and Oracle's proprietary extensions of SQL.
How about the Data Lakes and managed Hadoop providers.
How about the idea of NoSQL replacing traditional databases and MongoDB(amongst others)?
I am not saying these best practices, tools, and standards are bad per se. After all, every one of the above referenced examples has their place. They came about for a reason.
But I do think it's important to understand if you're coming into the industry, that many of these ideas being pushed benefit specific companies.
And to be clear, we are all likely curious about the newest hyped words. No one is safe from it. It’s part of who we are as technologists and engineers. We want to be on the cutting edge. We want to know what is going on.
It can also distract us from just delivering what the business needs.
So to all you new data engineers and analysts, always read and take in ideas with a grain of salt and ask yourself if using any best practice or design pattern fits your use case and why the best practice even exists.
With that let’s go over an example and discuss how you can approach the issue of vendor-driven design.
Digging Deeper Into A Recent Example
A recent example of a term being pitched as a future architecture is the “Composable Data Stack”. I have been seen a few posts about it(which you can see one of them below) and for all extents and purposes, the term can feel like it has come out of no where.
So where did it come from?
Likely it stems from the paper put out by Wes McKinney, Pedro Pedreira, Satya R Valluri, Mohamed Zait, Orri Erlin, Konstantinos Karanasos, Jacques Nadeau and Scott Schneider all of who worked at several different companies including Meta and Databricks to write the Composable Data Management System Manifesto.
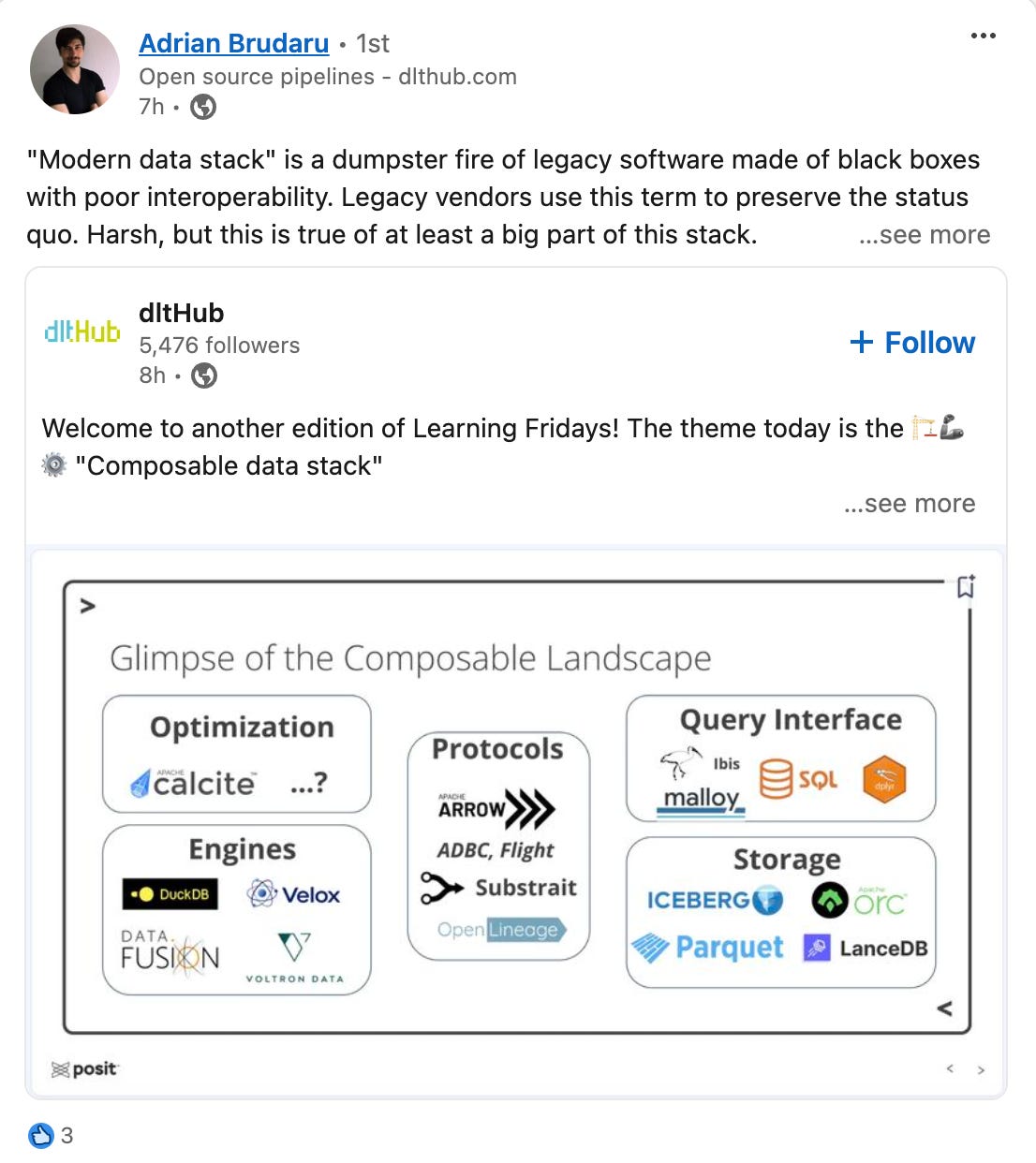
There are dozens of terms like this that are floating around the data and tech space just like it. It’s one of the many ways we test out new ideas to see if they could replace a prior methodology or approach.
I believe that one of the reasons that some of these terms and marketing take off is because they capture some zeitgeist or answer a problem that people have.
Actually, I really like how
brought this up in a video he recently put together for the TFA community where he referenced defining clear terms that encapsulate the solution you are selling.It’s part of the process. Companies, consultants, and individuals likely see a trend in how companies are solving a problem and then try to capture it.
They give it a name, and either with enough of a marketing budget, good timing, or likely a combination of forces. Suddenly everyone is using the term.
That’s a win.
The struggle occurs as the term naturally gets used more and more and starts to a lose a little bit of its meaning(if not all of it). As soon as other marketers and sales team see it, they will all try to shoehorn their product into the space.
Whether it makes sense or not and then we see the cycle below where a term goes from having meaning to meaning almost anything.

All that being said, I do think that problems can arise when you allow vendors to drive your design.
The Problem
Let’s talk about some of the issues you’ll face when designing your data infrastructure the way the vendor says you should.
Actually, let’s focus on just one example. The issue you’ll often face when you follow vendor-driven design is the vendor may be focusing specifically on the benefits their platform provides while ignoring the many lessons and actual best practices we’ve picked up over the past few decades.
An example of this was how many tools in the modern data stack were all focused on singular tasks and didn’t really talk to each other. Suddenly, many data teams had to use a similar approach to the days of old when you had to use Cron or Windows scheduler to manage jobs. You’d have one task that took 20 minutes, give a little bit of buffer, then set the next task, etc.
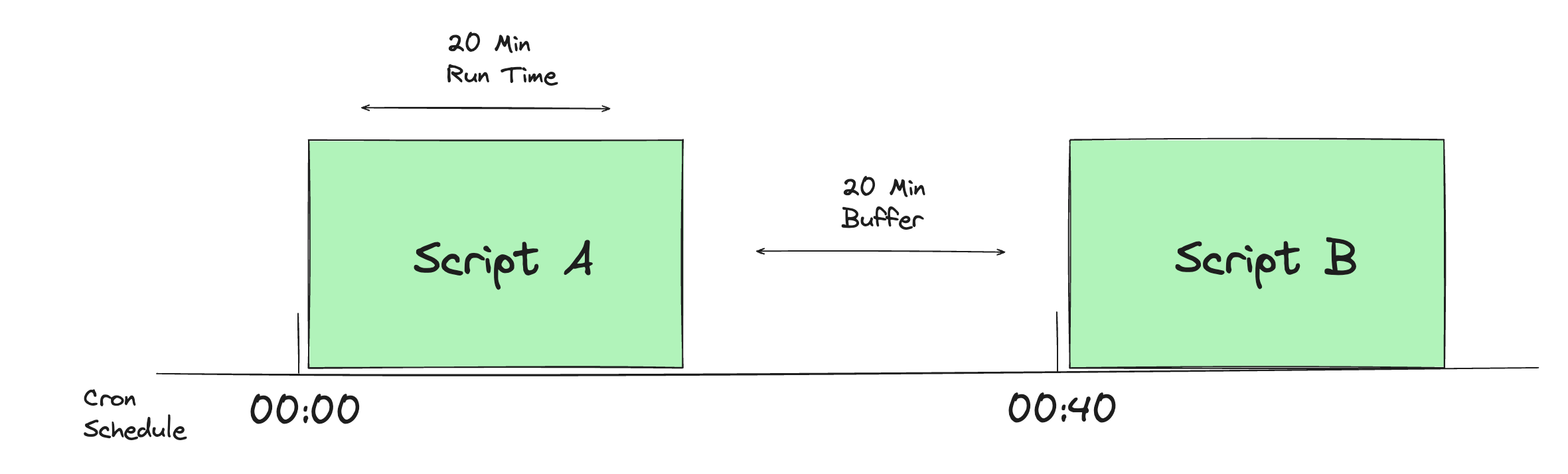
Maybe if you were really ambitious, you’d set up some sort of lite dependency management system that tracked what jobs were completed and on what day, etc.
That’s why solutions like Airflow became popular (as well as every internally developed solution that was similar).
Yet we gave up those benefits for the trade-off of having solutions that were really good at one thing (like extract or transform) but didn’t really talk to each other. So we’d have to spend time to now integrate three solutions into Airflow itself or ignore the problem and just go back to having different steps run and hope one completed before the next one started.
This eventually led to the need for tools like 5x, Mage Mozart Data, and Orchestra that all wrap around these tools to orchestrate the workflows.
Now there is an argument to be made that this is a better end state. Perhaps you like it.
Even there, that problem was essentially created by the vendor marketing push for unbundled solutions and the solution is more vendors.
It kind feels like the TV/streaming unbundling where we suddenly realize we might be going back to a cable-like solution.
Overall, as long as you understand the situation and what you’re actually trying to build in terms of data infrastructure you’ll be able to discern what patterns will be best for your use cases.
What Should You Do
As I said earlier, none of this is per se bad. But it does mean, you, as an engineer, director, or technologist, need to dig deeper. You can’t just lazily read about best practices and assume it’s what you should do.
Instead, you should build a solid base of knowledge that includes many perspectives. Some of which you should disagree with but having a broader understanding of the data space helps provide you with the tools required to build better architecture.
Here are a few resources that I believe are worth digging into.
I hope that as you read or watch them, you realize that perhaps some of the problems you’re having today have existed for years and some of the solutions you believe are new…also have existed for decades.
Research papers, articles and other written content
Talks, Podcasts and Conversations
Functional Data Engineering - A Set of Best Practices | Lyft
Data Engineering Principles - Build frameworks not pipelines - Gatis Seja
Data Serialization Formats with Doug Cutting and Julien Le Dem
Modern Data Modeling Beyond The Theory - With Veronika Durgin
Wes McKinney - DataPad: Python-powered Business Intelligence
Note: Also, if you believe you have some articles that should be added to this list, let me know!
Think Before You Design
It’s interesting when you ponder the fact that maybe a lot of what you think is good design, is just marketing well targeted at initially a specific problem you have, and eventually that solution is marketed as the only solution.
Overall, I think the important takeaway from this article should be to think for yourself.
Ask why you’re building what you’re building.
Not just in terms of “Are you building the right thing for the business” but “Are you picking and building the right data infrastructure for the problem?” Or are you letting someone else decide for you?
Honestly, the fun part, for me, is the design. So why rush through it!
Thanks for reading.
Video Of The Week: Don't Lead A Data Team Before Watching This - 5 Lessons You Need To Know As A Head of Data
Join My Data Engineering And Data Science Discord
If you’re looking to talk more about data engineering, data science, breaking into your first job, and finding other like minded data specialists. Then you should join the Seattle Data Guy discord!
We are now well over 7000 members!
Join My Technical Consultants Community
If you’re a data consultant or considering becoming one then you should join the Technical Freelancer Community! There are tons of free resources you can access to expedite your journey as a technical consultant.
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Managing up: 3 things I wish I realized sooner
By
Your relationship with your manager is the most important one to get right.
Having a solid relationship with them:
Opens you up to more opportunities to support your growth
Gives you a strong advocate when promotion time comes
Makes you feel psychological safety
But you’re rarely ever taught how to make that relationship happen. You have to figure it out yourself.
Organizational Anti-Patterns For Data Teams

As companies continue to implement data and automated processes into their workflows and strategies, they unavoidably set up processes that, in the short run, help them develop faster but often have negative impacts in the long run. You could call these organizational anti-patterns or process anti-patterns. But honestly, that's me just looking for some form of a buzzword to fit my article around(although I did find the term "
End Of Day 135
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
Thank you so much for the mention, Ben 🙏 it means a lot man
Thanks for the mention Benjamin! We very much agree!
Our LI post is a challenge of the status quo. Both terms are vendor driven and each user camp only hears their side. The 2 stacks have largely different use cases and application with some intersection. The future is not one thing, but many of the MDS vendors already belong in the past. For example on data transfer, you can use a paid tool for SQL copy, and it will be slow and expensive, or you could set up an open source pipeline that works 10x faster with 200x less cost.
example: https://dlthub.com/blog/replacing-saas-elt
So if you just follow the discussion of one side, you will miss out on the benefits of the other.
dlt is unique in that it both leverages the composable stack under the hood, enabling amazing speed gains, while fitting well into the MDS.
Check out how we get 30x speed gains using arrow under the hood, and also why we use it, and why we don't use it.
At the same time, our airflow, dagster and dbt integrations are the most popular extensions.
https://dlthub.com/blog/how-dlt-uses-apache-arrow
https://dlthub.com/blog/dlt-arrow-loading