


The State Of Data Engineering - Part 1
The Amuse-bouche
Hello readers! We are waiting for a few more days until we put out the League of Legends ML article. But for now, let’s dive into just the tip of the iceberg of the recent survey results
Over the past two months, I have been running a survey to get an understanding of what is going on in the data world.
During that time we had well over 400 respondents answer questions about what their data infrastructure looks like as well as ask about best practices and other logistical questions.
For this newsletter, we are only going to scratch the surface of this data because there are many different ways we can slice and dice the data we got.
For this part 1 of our initial breakdown we will be focusing on the following points.
Backgrounds On Who Filled Out The Survey
Vendor Selection( Data Analytics Platforms And Orchestration)
Best Practices
Frequently Dealt With Problems
In our future breakdown, we will both dig deeper in terms of demographic segmentation as well as look into other solutions such as ETL/ELT, data observability, and a whole lot more.
So make sure you’re signed up for future newsletters if you’re curious about what tools and practices data teams are implementing.
Who Filled Out the Survey?
Let’s start with a broad overview of who filled out the survey.
We had well over 400 people that filled out this survey.
One of the first questions that were asked was what industry do you work for.
Here were the top ones industries:
Finance
Software And Technology
Healthcare
Retail
E-commerce
Of course, you’re likely more interested in the actual numbers so you can see those below for the top 10 industries that the respondents worked for.
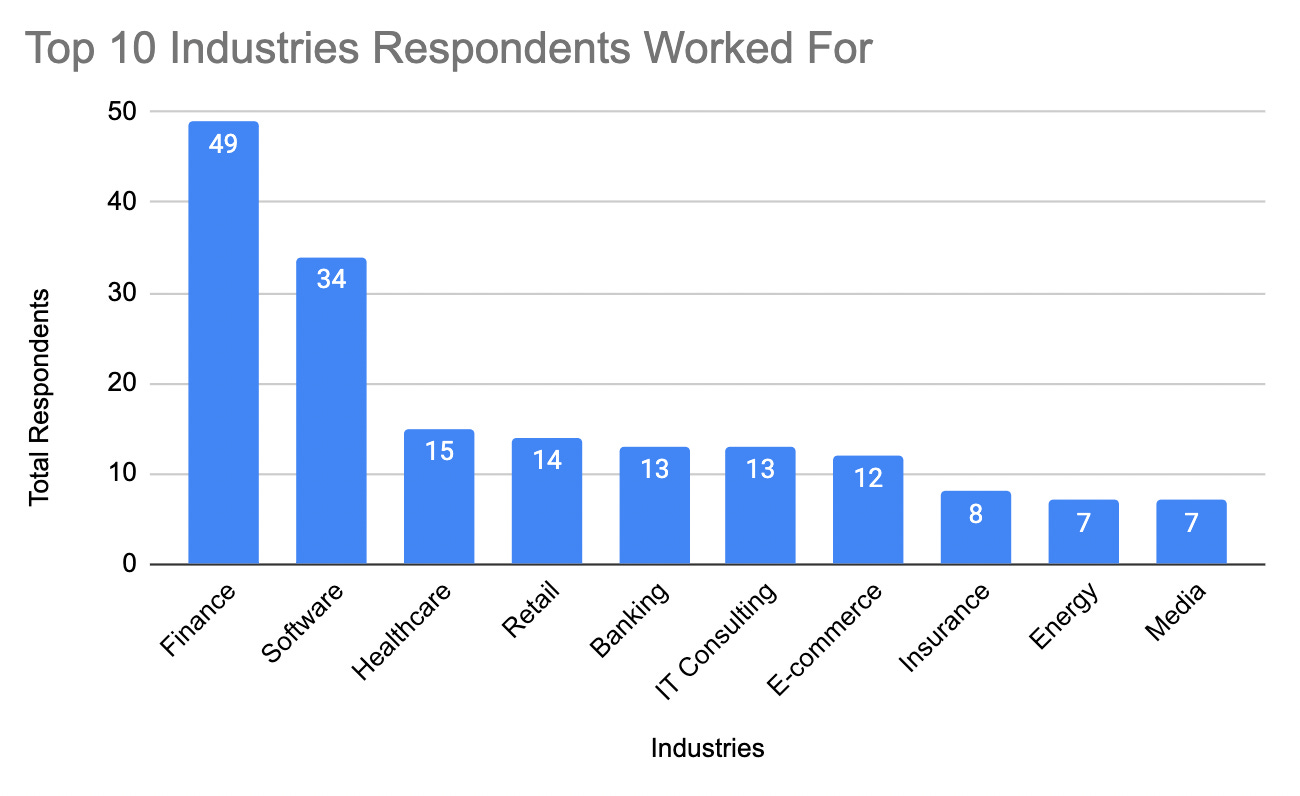
.
Company Size
In terms of the size of companies that these respondents worked for, we had a wide variety that ranged from SMB to enterprise.
The three largest demographics were companies with employees that ranged from 101-500, 1001-5000 and 25,000+.
You can see the rest of the breakdown below.

I am excited for this broad range of company sizes because this will allow use to answer questions via segments such as:
Are the problems that large companies face the same as smaller ones?
Is there a difference in the solutions used by different sized companies?
Do companies of various sizes implement different best practices?
etc
Job Types
Finally, let’s take a look at job-types. By a landslide, data engineers are the most common job type with about 41% of respondents fitting that job title. After that is VP of Analytics and so forth. I do wish there was a slightly broader range but this makes sense in terms of my audience.
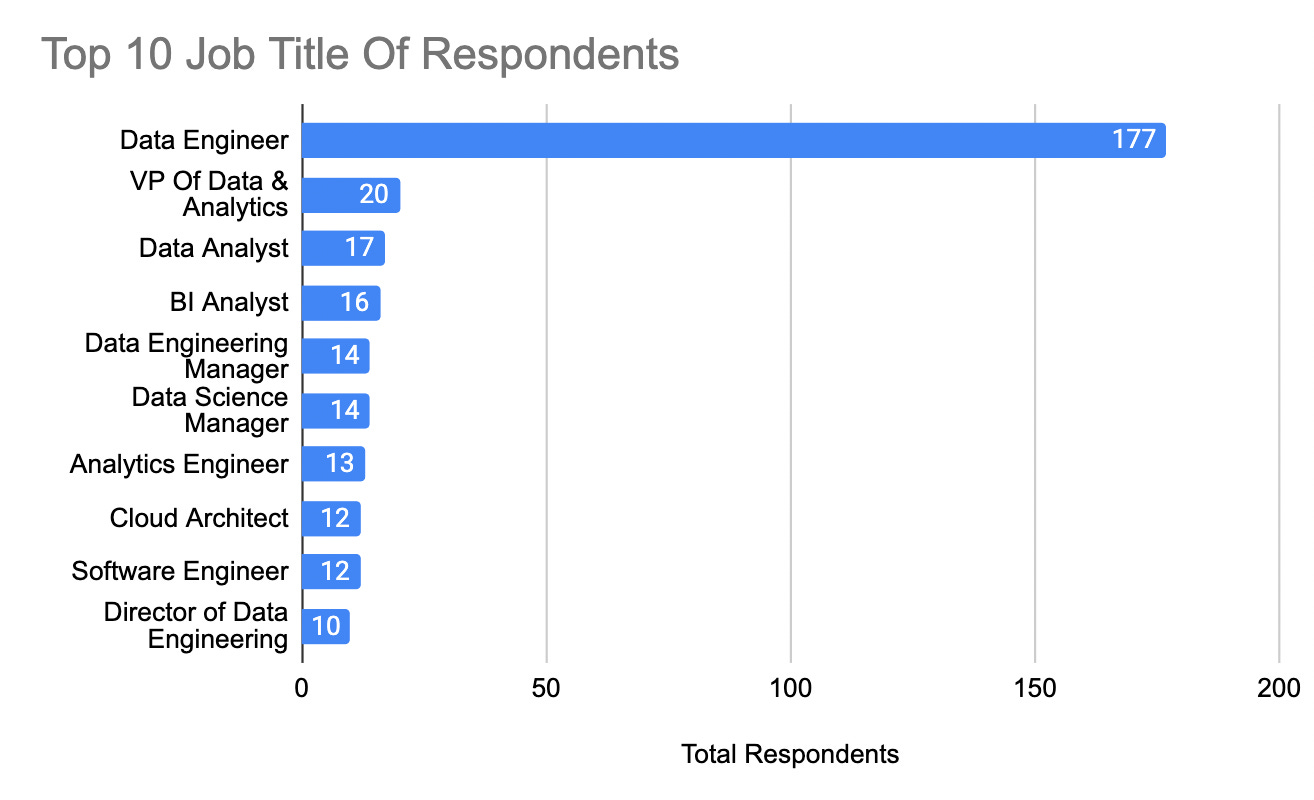
All that framing done. Let’s start to dive into the tools all of these respondents are using on a daily basis.
Vendor Selection
Companies spend a lot of time picking the right data analytics platform( whether that means a data warehouse, data lake or something else). Between all the marketing, comparison articles and videos, it can feel like a hard choice.
So what are people really using?
Data Analytics Platforms
If we were to only look at pure plays. That is to say, companies that only rely on one solution, then surprisingly ( or perhaps too many, not) BigQuery happened to be the most common selection. Followed by Snowflake and Redshift.
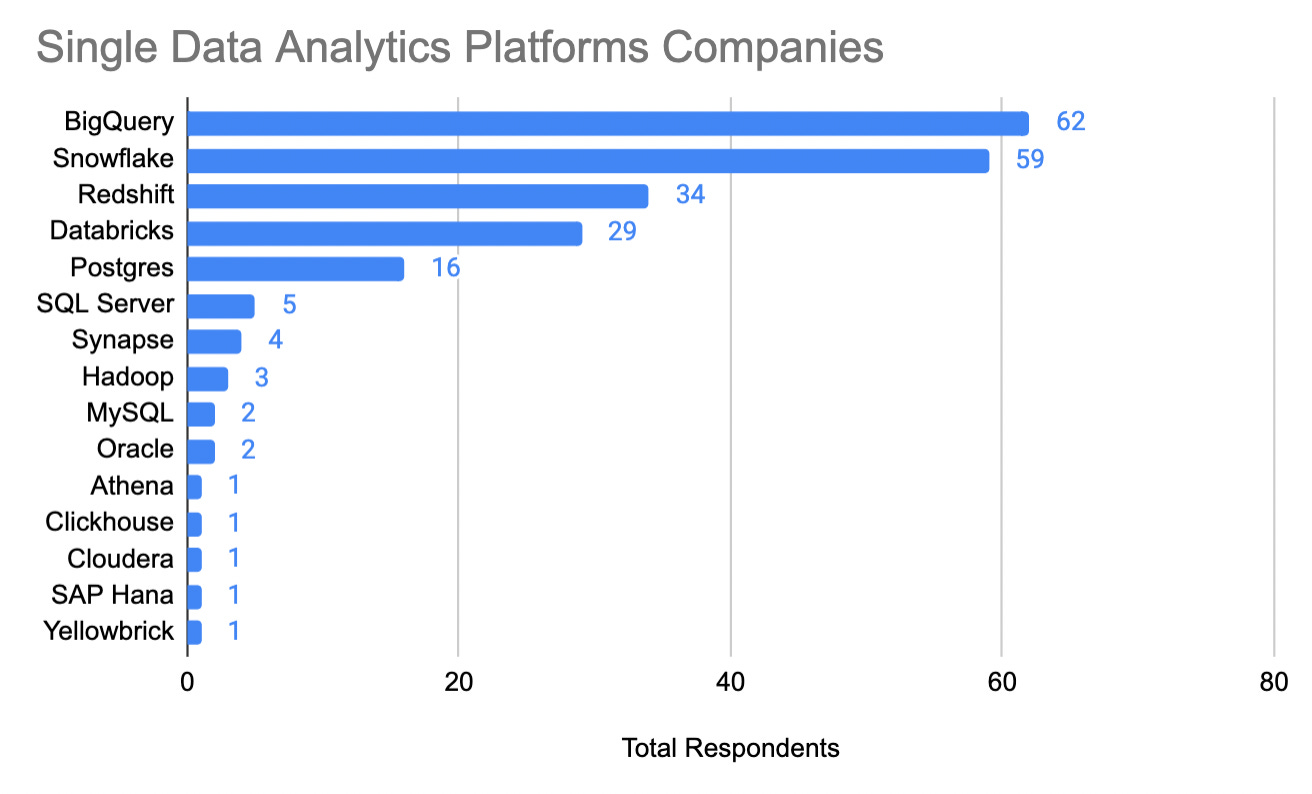
Now before anyone from Google goes cheering, many of the responses were not pure plays.
In fact 49% of respondents rely on multiple analytics platforms.
When parsing through companies that rely on multiple data analytics platforms, then Snowflake was in the lead with 20% of respondents referencing Snowflake( including in combinations).
Companies having multiple analytics platforms lines up with much of my experience as many of my clients often relied on multiple cloud analytics platforms. Sometimes this was broken down by department. That was often the cleanest. But honestly, I have even seen the same team use BigQuery, Snowflake, and Databricks ( It can get pretty chaotic out there).
This is often driven by a combination of time, failed migrations, and the personal preference of engineers. Eventually, it’s not uncommon to see 2, 3, 4, or even 5 different solutions being used for a combination of use cases all in one Jupyter notebook.
In part two we will dive deeper into this section and go into the size of companies that are using these various solutions and some of the emerging technology being referenced.
Orchestration Tools
The orchestration wars continue and I look forward to the end of 2023 when I can compare last year's data to this year.
I’d like to point out that this is purely orchestration and next week I will dive into the ELT/ETL tools like dbt, Fivetran, Rivery, etc.
Currently, the two main winners (in terms of percentage of users) in orchestration are Airflow and custom-built solutions. Airflow has 41% of the market whereas custom-built solutions have 14% (I also skipped over none which was a whopping 16%).
This resonates as 4 of the clients I worked with this year selected Airflow, mostly with Cloud Composer or MWAA. I believe some of this has to do with the fact that I have a lot of content focused around Airflow.
In fact, in a future article, I will be breaking down the attribution of where my clients come from, and 3 of them all came from a single piece of content.
In terms of the rest of the respondent's answers for what orchestration tool they use, it gets pretty hairy very fast. Let’s first look at this pie chart below, only because it is so amusing(and a great reason why not to use pie charts).
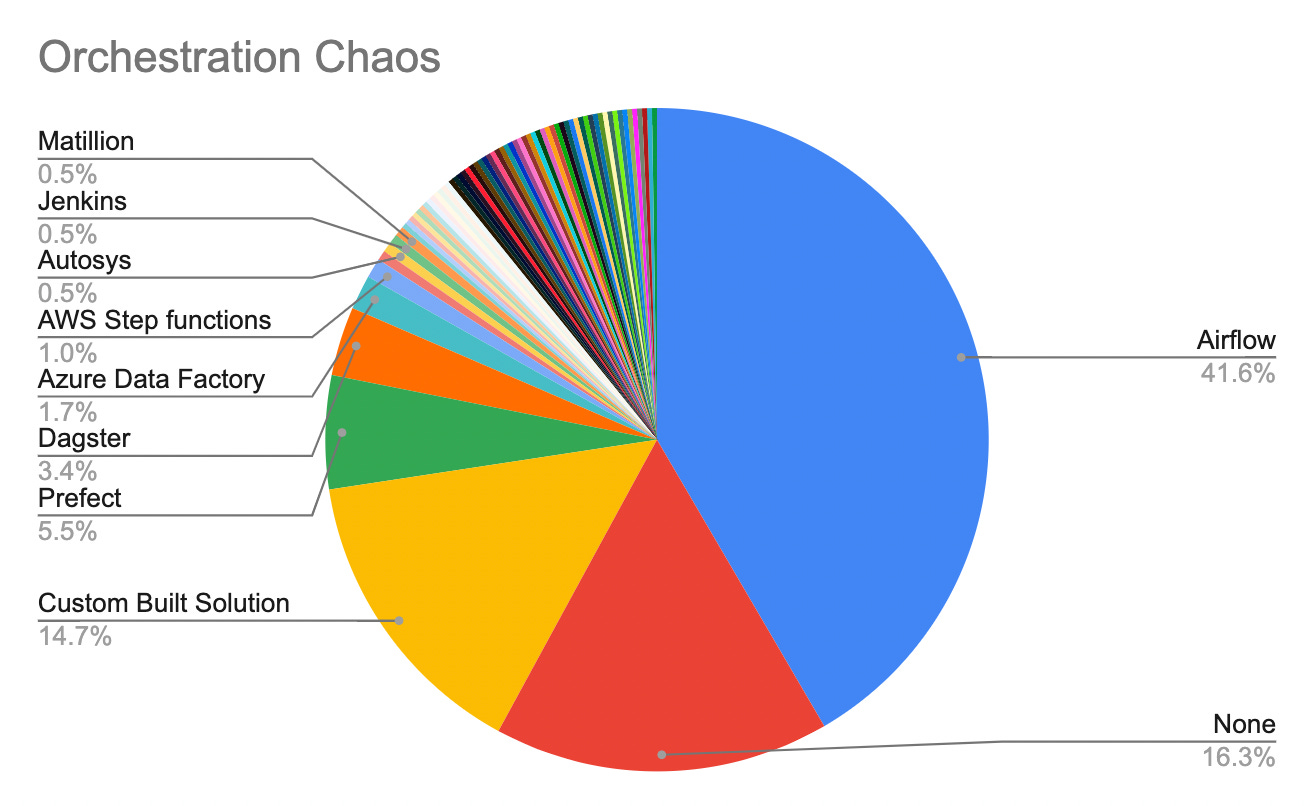
As you can see, Airflow, custom-built solutions, and none make up the majority of orchestration solutions. The rest are practically indistinguishable. However, there are a few slices that stick out. So let’s parse them out into the top options below.
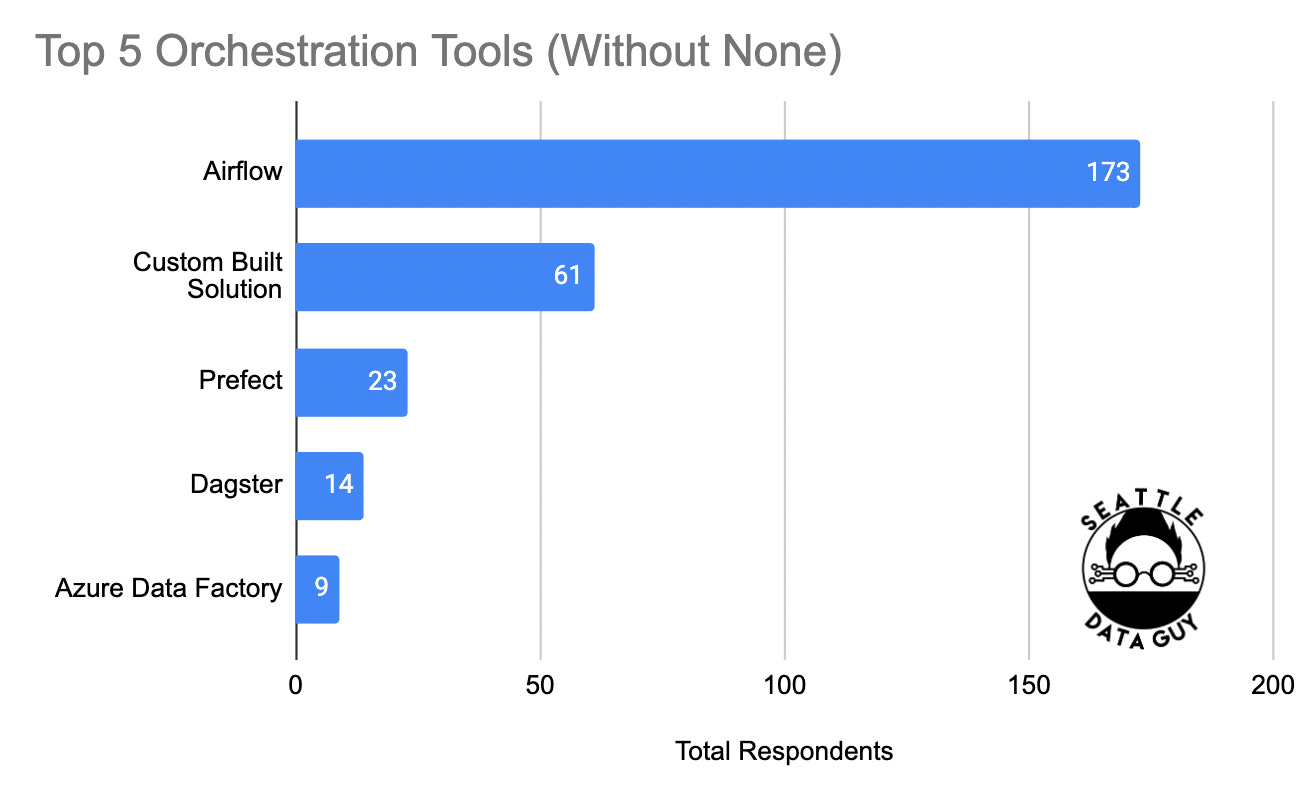
These results make sense as Prefect and Dagster have been increasingly becoming more vocal and Azure Data Factory doesn’t generally require too much in terms of procurement to approve usage.
This is all current state, and in the next year, I would imagine thanks to all the marketing that Airflow, Prefect, Dagster, and now Mage are putting out we will see some shifts. At least from the none and custom-built solution buckets. Teams will likely look to pick simpler options and possibly build less custom-solutions.
Especially if budgets continue to tighten.
What Best Practices/Standards Are Data Teams Incorporating
For this section, we asked about several best practices and standards that companies would likely be utilizing. This included style guides, design documents, linters, CI/CD, and unit-testing. We are going to go over style guides and design documents for now but we will be digging deeper in our next few articles.
Style Guides - Having a written out style guide with expected standards for what naming conventions are and the general philosophy for a team can genuinely make your engineer's lives easier. I have found this to be true across industries and team sizes. Whether this was at Facebook where we did have a style-guide for our team or at several of the start-ups I have worked with.
Once your data team passes 3-4 people, style guides and standards make it far easier to onboard new employees, make changes to code bases, and make code more readable. I discussed this last week a bit when I talked about the importance of good design.
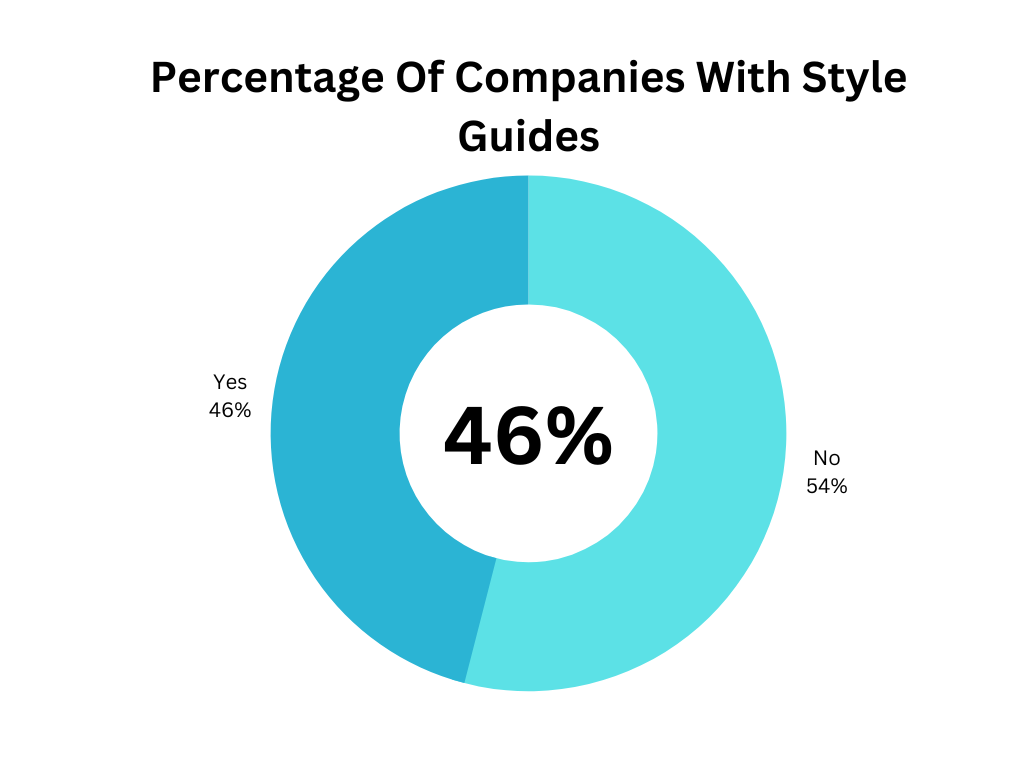
That’s why it was surprising when I only saw that 46% of teams had a style guide. This also generally got worse as companies got larger. For example, companies with over 25,000 employees only used style guys about 36% of the time.
Overall, it usually doesn’t take long for a team to set standards. You don’t even need to start from scratch. Here are a few great examples of style guides you can start from:
Design Documents - When preparing to make large changes or implement entirely new modules many teams will put together design documents. These usually cover the purpose of the new component or product feature, what considerations were made when picking it, limitations, constraints, high-level designs, etc.
I have found the process of putting these documents together useful because it helps take what is in an engineer's head and put it out for everyone else to see. It makes it easier for others to pose questions and concerns with the design as well as helps the engineer think through design choices more thoroughly.
When I worked for a very product-focused start-up, we never started even putting together a project plan before having a design document. We also happened to launch 2 new products successfully and we were able to track ROI easily because we had built all of it into the base design document.
That’s why again, I was surprised when only 45% of respondents said they incorporated design documents into their process.
Now, perhaps I should have separated this question and asked “For the last project your team took on did you have a design document” to ensure only respondents that were implementing new solutions answered but that’ll be an improvement for next year’s survey.
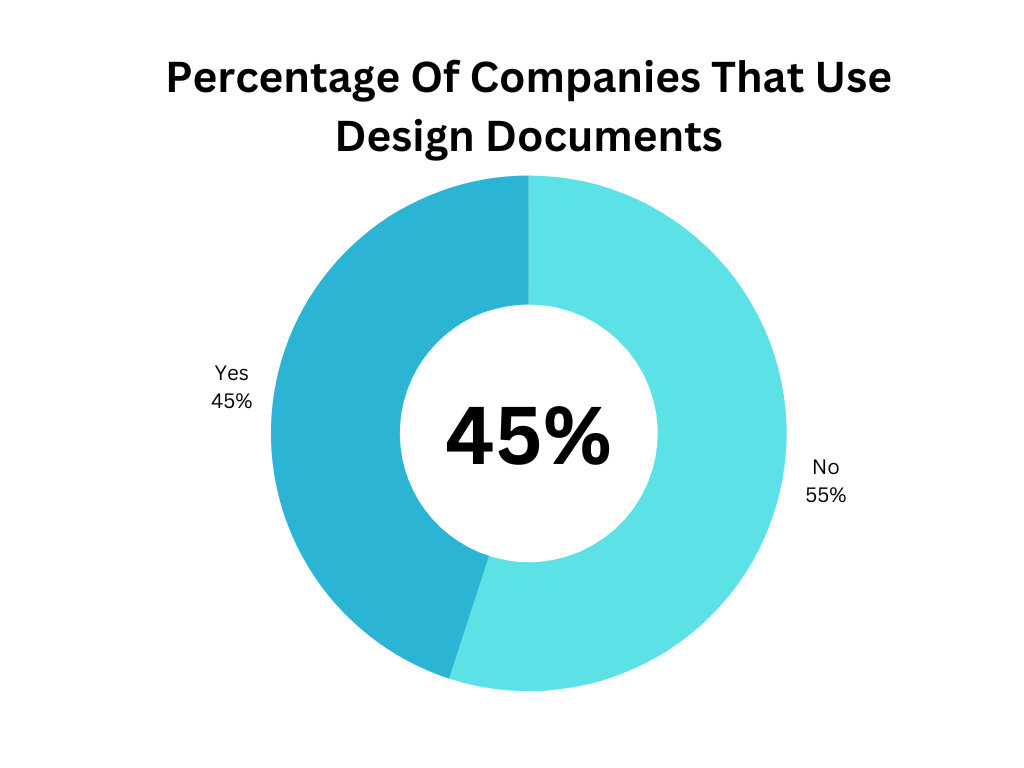
If you are starting a new project or product, then I’d say putting together a design document is a good exercise to go through.
What About The Rest?
As referenced above we also asked about several other categories which had similar responses around 50% ( I look forward to see if there are any correlations).
Setting standards and using design documentation are great practices to incorporate into your data team’s day-to-day to ensure you develop maintainable and easy to manage systems.
In turn, this helps reduce the amount of problems your data team will have.
Largest Problems Facing Data Teams in 2022
Let’s lightly touch on the problems faced by many teams. We will only be getting started becauseI believe this question poses a lot of opportunity for digging deeper ( like do teams who incorporate more best practices have less problems with data quality?).
In terms of the raw numbers, you can look at the top problems respondents provided below.
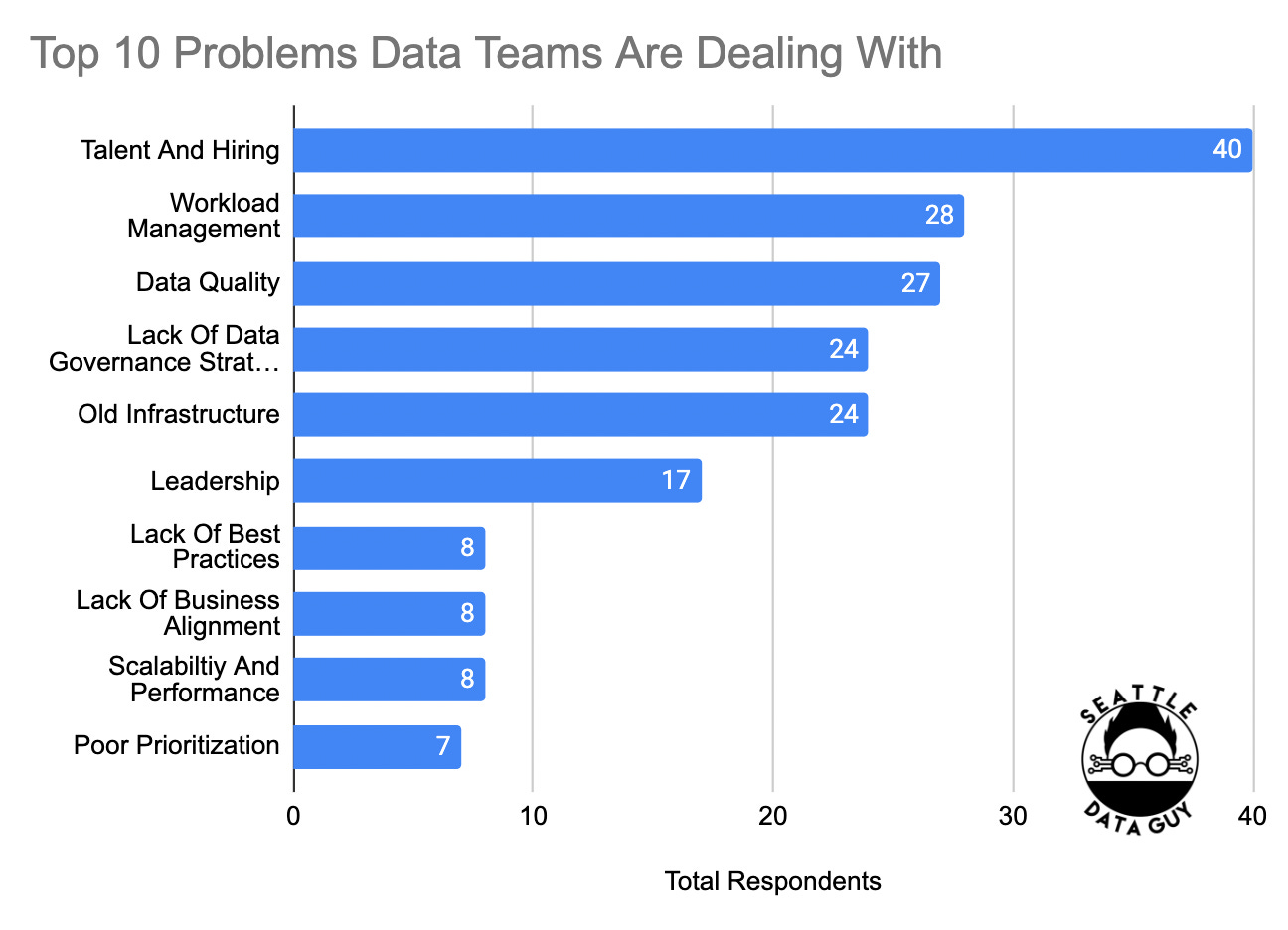
Talent And Hiring - The biggest problems many of these teams faced were talent and hiring. If you’ve broken into data engineering, this probably rings very true to you. The data infrastructure and engineering world still have limited support in terms of programs and courses that students and new entrants can take.
They exist, and of course, companies could pay for upskilling and training. But when it comes to out-of-college individuals, there remains a gap. In addition, many companies often struggle to hire junior data engineers.
There are plenty of people working to attempt to fix this such as Joe Reis and Matt Housley. But for now, I foresee this being a problem for the next few years.
Workload Management - Following that and possibly closely related is workload management or the amount of work data teams are forced to take on with often little support. This is also often due to budgets as I have seen time and time again that companies that are quite large still often rely on small data teams to try to do everything. That’s what also leads to shadow IT teams coming up to try to mitigate this issue.
Data Quality - Behind that is data quality which has been a forever problem. Yes, we are finally starting to get better tooling around this. But it’s not just about tools but also improving data governance and other cultural best practices.
You can go through the rest of the list for the top 10 issues. Of course, there are another 40 categories I didn’t include such as data discoverability and costs. But again, this question alone might warrant its own newsletter.
The End To The Amuse-bouche
Overall I am really thankful for everyone who participated in this survey. I look forward to improving it and asking better questions next year (while working to make them correlate to this year’s questions).
If you’d like to learn more, then consider signing up for the State Of Data Conference 2023 happening this Wednesday January 18th.
More below!
Seattle Data Guy Events!

Select Star gives you an automated data catalog, lineage, and usage analysis across thousands of datasets, so you & your team can find and understand data easily.
The Data Stack Show Conversations at the intersection of data engineering and business
Join My Data Engineering And Data Science Discord
Recently my Youtube channel went from 1.8k to 51k and my email newsletter has grown from 2k to well over 31k.
Hopefully we can see even more growth this year. But, until then, I have finally put together a discord server. Currently, this is mostly a soft opening.
I want to see what people end up using this server for. Based on how it is used will in turn play a role in what channels, categories and support are created in the future.
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Self-serve feature platforms: architectures and APIs
The last few years saw the maturation of a core component of the MLOps stack that has significantly improved the ML production workflows: feature platforms. A feature platform handles feature engineering, feature computation, and serving computed features for models to use to generate predictions.
LinkedIn, for example, mentioned that they’ve deployed Feathr, their feature platform, for dozens of applications at LinkedIn including Search, Feed, and Ads. Their feature platform reduced engineering time required for adding and experimenting with new features from weeks to days, while performed faster than the custom feature processing pipelines that they replaced by as much as 50%.
Using Rust to write a Data Pipeline. Thoughts. Musings.
Rust has been on my mind a lot lately, probably because of Data Engineering boredom, watching Spark clusters chug along like some medieval farm worker endlessly trudging through the muck and mire of life. Maybe Rust has breathed some life back into my stagnant soul, reminding me there is a big world out there, full of new and beautiful things to explore, just waiting for me.
I’ve written some Rust a little here and there, but I’ve been meditating on what it would look like to write an entire pipeline in Rust, one that would normally be written in Python. Would it be worthwhile? The cognitive overburden of solving problems in Rust is not anything to ignore. Rust is great for building tools like DataFusion, Polars, or delta-rs that can be the backbone of other data systems … but for everyday Data Engineering pipeline use? I have my doubts.
End Of Day 67
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
Thanks for the post. As a product leader who's led platform teams including Data teams in the past - many of the challenges shared here resonate. At the risk of over-simplifying things, it feels like many of the problems are second order effects of lack of strategy clarity & organizational commitment to Data Engineering as a first-class investment area. I say this with sadness and motivation to reflect, not as justification.