
Why Data Pipelines Exist
Beyond Moving Data From Point A To B
Hi, fellow future and current Data Leaders; Ben here 👋
Today will be getting back into my series on data pipelines. One question that I believe is important to answer is why? Why even build data pipelines?
But before we jump in, I wanted to share a bit about Estuary, a platform I’ve used to help make clients’ data workflows easier and am an adviser for. Estuary helps teams easily move data in real-time or on a schedule, from databases and SaaS apps to data lakes and warehouses, empowering data leaders to focus on strategy and impact rather than getting bogged down by infrastructure challenges. If you want to simplify your data workflows, check them out today.
Now let’s jump into the article!
When I first started in the data world, no one around me used the term data pipeline.
I heard terms like integrations, automations and ETL.
In fact, I am not even sure when I first came across the term. But if you’re a data engineer in this modern era, then much of your time is spent, building, maintaining and keeping data pipelines running smooth.
Even with AI, you’re probably still finding yourself opening up 3,000 line queries, and the occasional custom data pipeline system.
What a Data Pipeline Actually Does
When you look at data pipelines, here is likely what people might say they do.
Move data from a source to a destination
Sometimes they transform that data
And they do all of this repeatedly and reliably without human intervention
That’s the technical function of a data pipeline.
How it happens can vary.
This could be automated SQL, Python scripts, Airflow, Estuary, SSIS, Glue, and so many other tools.
But you do need to think beyond just this when it comes to data pipelines.
Pulling in a recent post from Zach Wilson.
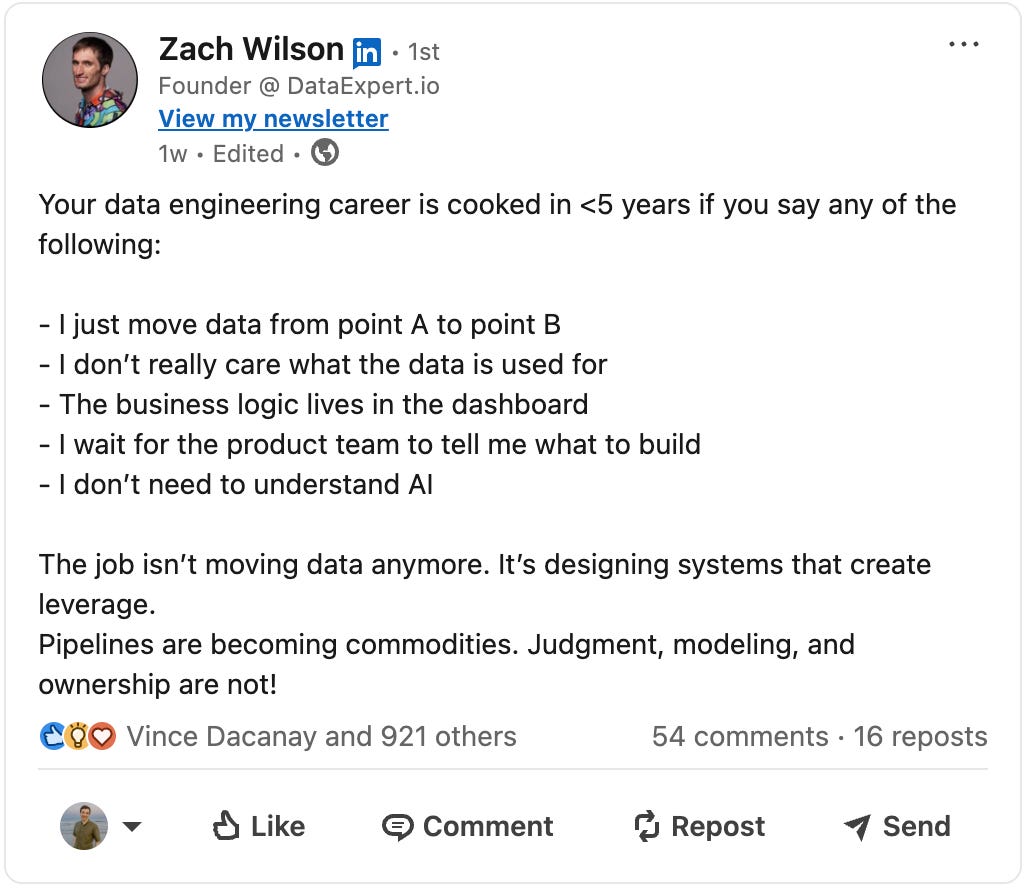
It’s important to think beyond just moving data from A to B. And start thinking in. outcomes and ownership.
What is the data pipeline actually doing?
