
The Baseline Data Stack - Going Beyond The Modern Data Stack - Part 1
Billions of dollars have been put into investing into companies that fall under the concept of “Modern Data Stack. Fivetran nearly has one billion dollars funding them, DBT has 150 million(and is looking to raise more), Starburst has 100 million(Not considered part of the MDS)…and I could really go on and on about all the companies being funded.
So that means every company has a fully decked-out data stack, RIGHT?
Yet, most companies don’t and can’t start with a completely decked-out data stack.
Instead, most companies build their data stack in stages, which is probably best the way to do it.
You don’t suddenly have a flawless source of truth with perfect serviceable data that can all be tracked through your data observability tools.
It takes time.
Teams need to develop processes, scalability, trust and the ability to actually execute on data.
In this article, I will outline the stages people go through building their baseline data stack. Of course, it can all depend on a companies priorities, goals, and funding.
The 5 Person Start-Up Data Stack
Early on, more than likely a company data stack is…Excel.
Let me explain. More than likely when your company is starting you likely have a developer, maybe an analyst if you’re lucky and that’s probably it.
The analyst requests data from the developer who will likely extract it from their production database(scary). But, hey, they haven’t had time to even set-up a duplicate database for reporting. Maybe next sprint.
In turn, that analyst or business employee does some basic slicing and dicing and creates some form of a report. When your company is only 5-6 people, this is a valid solution. Investing tons of effort into building a data warehouse or complex data transformations would likely be unwise.
Unless your company has amazing profits per employee.
But if you’re only doing a few transactions a day, don’t have a lot of data sources, and are limited on people's time, using Excel isn’t a bad choice.
It allows you to share data, do some basic analytics and create a few adhoc queries that can be utilized for future reporting.
Of course, if your company is successful, you will likely be moving off Excel very quickly.
Building Your First Baseline Data Stack

Eventually, the usage of Excel becomes unsustainable. It’s hard to maintain a manual process. Manual processes are error-prone and there are a whole host of other issues.
Especially when your company grows in terms of employees, transactions and data sources. All of this pushes your company to needing a centralized reporting system.
Now, your team is ready to consider building their first baseline data stack. At this point, this can be a daunting task. There are so many articles on how to build your modern data stack that it can be tempting to do everything all at once.
That’s not my preference.
In general, when first building a data stack you are just starting to get buy-in from management and stakeholders.
That means you probably need to return value quickly or at the very least prove that you can put out a basic report.
Meaning, trying to implement a layer of what people view as the modern data stack, will lead to failure.
Instead, I recommend you focus on 3 key areas.
1. Ingestion -> Data Pipelines
2. Storage -> Data Warehouses, Lakes, Lakehouses, etc
3. Reporting And Data Visualization -> Pretty Dashboards, Notebooks, And Unavoidably Excel Reports
These three key areas will let your team start to develop a process for getting data from sources to your data warehouse.
Building the processes and disciplines required to ensure you get reliable data from sources to your data warehouses is important. You need to not only figure out how to develop a maintainable process but a scalable one.
If your team is struggling to output a few pipelines and reports at a decent pace, how are you going to scale as your company grows?
So this is why I recommend most people focus on these three areas first.
Once you feel comfortable and well practiced in terms of data ingestion, storage and reporting, then you can start really exploding in terms of taking on new data initiatives.
Don’t Forget The Human Aspect
One thing I didn’t cover, that Danny from WhyLabs brought up was the fact of the human element. Yes, storage, ingestion, and reporting are sufficient from a technical side.
But, as Danny says,
“to deliver value to a business, there's another pillar needed which encapsulates the more human needs for data.”
The human aspect.
The truth about developing some form of a data warehouse is that the purpose is to create a place for analysts and data scientists to come and work with the data. Data analysts and scientists who are..well..human.
That means that the data you produce in this service layer needs to be understandable, easy to use, easy to track, and reliable.
If you can’t trust your data, then what ends up happening is that the users will shift to pull data from other methods. Like direct data pulls from the source. In turn, making your data warehouse useless.
If your users can’t find the data or don’t know it exists, again, they might manually pull it.
And if they don’t realize that some data transformations already exist, they might recreate them.
At this stage, I do think you can get away with a more manual process from some of these best practices. For example, for testing, you can set up some semi-automated queries to check your data or pay for a tool like Bigeye or Monte Carlo which are both pretty simple to implement.
For lineage and some form of the data dictionary, you could probably just track most of this in a combination of notion, Google Sheets, and Lucid Charts. At a certain point, this also becomes unmaintainable so it's mostly about finding the benefits trade-off point.
At the end of the day, it’s important to assess your company’s current status, needs, and priorities and add the right solutions accordingly.
But Where Is All Of This Going?
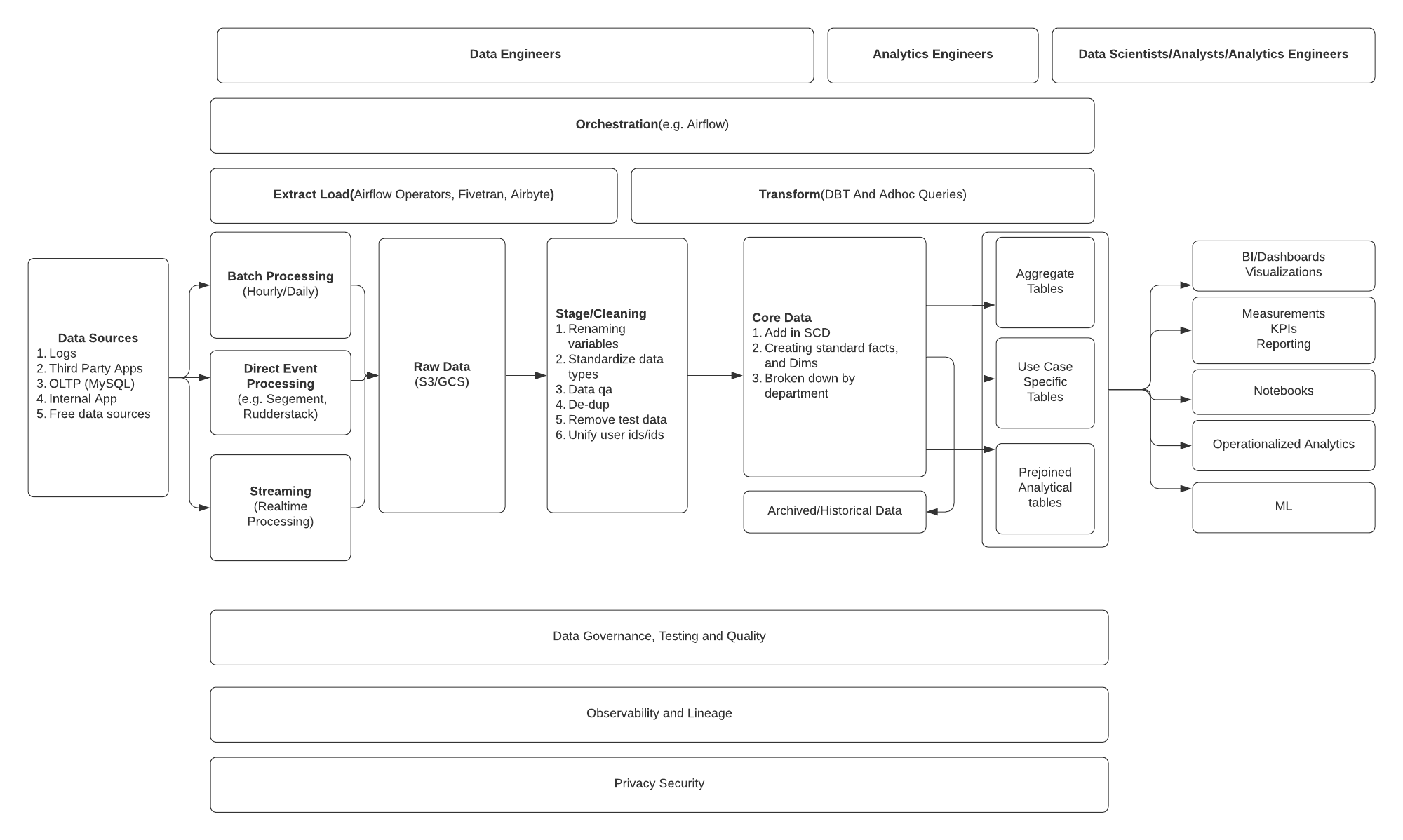
With your ingestion, storage and reporting out of the way. Now you can start to improve your data observability as well as implement tools to improve the traceability of how data gets through all the various tables amongst other sections depicted in the diagram above.
Even the above diagram doesn’t have everything.
For example, I haven’t included reverse ETLs, MLOps and a whole host of other tooling that Matt Turck does a great job of tracking.
I will continue to go through this diagram as well as improve it over the next few articles( between keeping up with all the new tools).
So if you want to learn more, then subscribe!
Jan 26 Webinar: RSVP today to hear how Seesaw used Rockset + Hightouch for Real-Time Analytics
SeattleDataGuy's subscribers who join get a free Rockset T-shirt
Seesaw provides a leading online student learning platform and saw it's usage 10x during shutdown. Their data infrastructure couldn't keep up with the growth for real-time analytics so they turned to Rockset and Hightouch.
In this webinar, learn how Seesaw:

Migrated from Elasticsearch, Amazon Athena, and custom python scripts to Rockset for real-time data analytics
Synced their DynamoDB to Rockset to power complex SQL queries that returned back in less than a second
Replaced brittle, custom built integrations to pull data from Rockset to Salesforce with Hightouch, saving valuable developer time
Sponsorship
Special thanks to Rockset. Rockset is a real-time analytics database service for serving low latency, high concurrency analytical queries at scale. It builds a Converged Index™ on structured and semi-structured data from OLTP databases, streams and lakes in real-time and exposes a RESTful SQL interface.
Video Of The Week - How I Would Become A Data Engineer in 2022
How would I become a data engineer in 2022? Back in the "old" days you would likely need to spend time working as an analyst for a few years before even considering a Data engineering role.
In 2022, I am seeing more internships and jr. data engineering positions.
So there is a chance you might be able to find a role out of college...as long as companies don't expect 2 years of experience for a jr. position.
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Trusting Metrics at Pinterest
For those who haven’t thought about metrics, this may seem like an odd problem. Something like Daily Active Users (DAU) may sound simple to measure, but here are some examples of how such a simple metric may go wrong:
An extension version of the app could decide to keep auth tokens fresh; they could auto login the users every day, regardless of if the user actually used the extension.
A user being active across midnight may count as an active user on both days for one platform, but not for another platform.
Non-qualifying activity such as using a browser extension could be counted as DAU.
Despite these cases, logging active users tends to be one of the simpler cases, so I’ll continue to use it as an example.
Experimentation is a major focus of Data Science across Netflix
Experimentation and causal inference is one of the primary focus areas within Netflix’s Data Science and Engineering organization. To directly support great decision-making throughout the company, there are a number of data science teams at Netflix that partner directly with Product Managers, engineering teams, and other business units to design, execute, and learn from experiments. To enable scale, we’ve built, and continue to invest in, an internal experimentation platform (XP for short). And we intentionally encourage collaboration between the centralized experimentation platform and the data science teams that partner directly with Netflix business units.
5 Million Users a Day From Snowflake to Iterable
When you set up your data stack with a warehouse first approach, RudderStack’s versatile nature allows you to overcome certain hurdles that were once too expensive or too difficult. This flexibility was on full display as we recently helped a customer solve one of these challenges.
The situation: bulk subscription enrollment
One of our customers has a business use-case for sending 5 million users from Snowflake to Iterable once a day for customer engagement campaigns. If you think this is an obvious case for reverse-ETL, you’re correct. Using RudderStack’s reverse-ETL tool, this customer can extract the 5 million users from the Snowflake table, and then activate them into Iterable so they can get triggered to receive emails. Simple as that!
End Of Day 32
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
If you want to learn more, then sign up today. Feel free to sign up for no cost to keep getting these newsletters.