
Normalization Vs Denormalization - Taking A Step Back
Denormalization and normalization are core ideas you should know about if you are a software or data engineer.
If you touch a database, whether it’s for analytics or it’s a document-oriented one, there are key concepts you should be aware of.
Data modeling is Dead
I recently reviewed a few different companies' databases and data warehouses and was shocked at what I saw.
So many basic concepts ignored and perhaps never understood. Now these aren’t one-off cases but they did make me want to review denormalization and normalization.
The funny thing is that many of these data modeling issues I saw could be fixed with a quick read on basic design patterns for databases.
For example, understanding concepts such as many-to-many resolutions, hierarchical data models, or other similar patterns would have helped guide some of the recent data models I have seen. But all this starts with understanding two big concepts…
Normalization and denormalization.
Normalization
Normalization, at its core, is about structuring data in a way that reduces data duplication and ensures data integrity.
Applied directly to the database, the definition below is perhaps more apt.
Normalization is the process of organizing data in a database. It includes creating tables and establishing relationships between those tables according to rules designed both to protect the data and to make the database more flexible by eliminating redundancy and inconsistent dependency. - Microsoft
That is generally the one or two liner answer most people will give when an interviewer asks about the difference between denormalization and normalization. However, it can feel like many of us have memorized but not internalized it.
Why Does Normalization Matter?
Why in the world does this even matter?
Why can’t we just shove all of our data into a single column and row and just grab everything from there? And yes, there are solutions that don’t require the same level of normalization as a standard RDBMS, but it’s good to understand the basis of a concept that continues to be utilized by companies of all sizes. It also shouldn’t be ignored just because we have infinite compute and storage.
So let’s go over the goals and then discuss some of the key normal forms.
Goals of Normalization
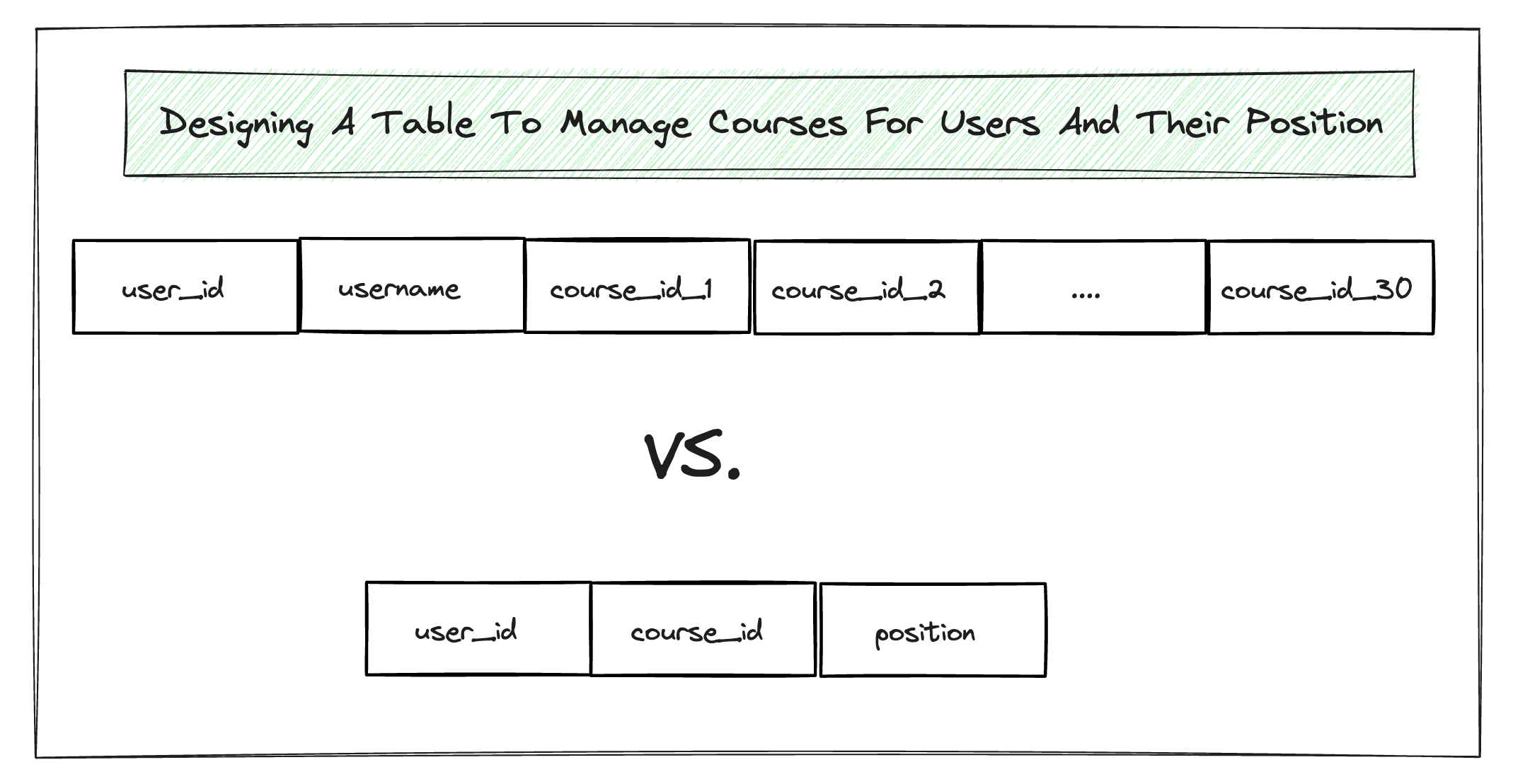
Eliminate Redundant Data: Ensure each piece of data is stored only once, reducing the storage space and improving data consistency. One reason this was done was because of limitations in terms of server space. That’s not a problem anymore, right?
Minimize Data Mutation Issues: Prevent update, insert, and delete anomalies that can lead to inconsistent data. This can still be an issue if you model your data in strange ways or have the redundant data stored in multiple locations.
Protect Data Integrity: Preserve the natural data relationships and enforce referential integrity. That is to say, a crucial part of a standard relational database is the fact that if there is an ID that relates one entity to another, it should exist. If there is a transaction ID with a customer ID, the customer needs to exist. However, it is very easy in a database with no restrictions to delete a customer ID and orphan the transactions. Thus, the database should support the ability to protect integrity.
The Normal Forms

Normalization involves several stages called "normal forms" (NF). Each form represents a level of database refinement:
First Normal Form (1NF): A table is in 1NF if it contains no repeating groups of data and each field contains only atomic values. in this case, I once had a project where the project ID field was a varchar, which lead to end-users putting multiple project IDs in a single field. This made it difficult to tie users to specific projects and work completed because this data had to be parsed out first.
Second Normal Form (2NF): Achieved when a table is in 1NF and all non-key attributes are fully functionally dependent on the primary key. An example of this is in the image above where user_id and username exist in a table that represents the relationship between course and users. The username should be in the user table and doesn’t need to exist in the user_course table.
Third Normal Form (3NF): A table is in 3NF if it is in 2NF and all the attributes are not only fully functionally dependent on the primary key but also non-transitively dependent.
These aren’t the only normal forms, but 3rd normal form tends to be where most database design ends. However, if you want to read about BCNF or 4th and 5th normal form, you can learn more about them here.
The Benefits

Normalization exists for a reason, it has/continues to provide several key benefits. It reduces redundancy, which in turn reduces the chance of various anomalies occurring when data is modified. It also consumes less space and enforces a better database structure, promoting maintenance and scalability.
An example of the opposite of ease of maintenance would be a database I saw recently where someone had dozens of columns each for an ID of the same entity(depicted in the first figure above), so it was entity_id_1, entity_id_2…entity_id_n–part of which acted as an positioning system.
Can you imagine trying to maintain this system. Both in terms of the code to update the IDs as well as having to add new columns when a user wanted to add more entities to their list.
However, normalization is not without trade-offs. As data is spread across more tables it unavoidably increases the complexity of queries. You need to now write SQL queries that join across 10 tables to get a single field. Additionally, you can venture into the world of over-normalization, where the decomposition of tables is taken to an extreme, leading to an unwieldy and inefficient structure.
It also doesn’t fit every use case well. In turn, that’s where denormalization comes into play.
Denormalization
While normalization is a core concept in relational database theory, practical considerations can lead us down the path of denormalization. This is the process of strategically introducing redundancy into a database to improve read performance, which is especially relevant in scenarios where read operations vastly outnumber write operations. The most obvious example of this for data engineers would be a data warehouse.
Use Cases for Denormalization
Reporting and Analytics: When people say data modeling, most people probably assume this is one of its main use cases. That is to say, data modeling for data warehousing. Of course, data modeling is a far broader term that covers both operational and analytical uses cases and likely could be argued to cover even more in terms of concepts.
Read-Heavy Applications: Applications where the speed of read operations is critical to user experience.
The Trade-Offs Of Denormalization
Denormalization obviously, like anything else in terms of design decisions, has it’s fair share of trade-offs.
It introduces data redundancy, leading to the risk of data anomalies and increasing storage costs.
Yet, when database systems are read-heavy, the performance gains can be significant. The cost of additional storage and the risk of data anomalies are often offset by the gains in quick data retrieval times.
Also, in terms of anomalies, most well designed data warehouses or similar data analytics storage systems have data quality checks that should be run when tables are populated.
Thus, avoiding some of the risk.
Of course, many normalized source systems don’t always have these checks and in turn sometimes cause major issues between the source, data pipeline and destination.
But that’s a different issue for a different day.
Finding the Balance
The decision to normalize or denormalize often is more of a set of guidelines vs. an absolute. There might be parts of your operations database that you knowingly design to be denormalized. Not to mention that with the popularization of the cloud and new data types, some of the issues we were trying to design for aren’t as big of an issue. However, that doesn’t mean you don’t need to spend time designing your database.
If you go into database design without thinking about what these trade-offs are or worse, not knowing what they are, you will end up like the developers at the beginning of the article–whether its because you’re using the ORM to create your database or because you’ve been pushed to work faster than you should. Regardless, building a database without any design is just asking for trouble in the future.
Thanks again for reading!
Data Events
INNER JOIN: Data, Drinks, & Connections - Gable.ai Launch Party - Las Vegas
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Streaming SQL in Data Mesh At Netflix
Data powers much of what we do at Netflix. On the Data Platform team, we build the infrastructure used across the company to process data at scale.
In our last blog post, we introduced “Data Mesh” — A Data Movement and Processing Platform. When a user wants to leverage Data Mesh to move and transform data, they start by creating a new Data Mesh pipeline. The pipeline is composed of individual “Processors” that are connected by Kafka topics. The Processors themselves are implemented as Flink jobs that use the DataStream API.
What Is Event-Driven Architecture? Comprehensive Guide 2023
Boldly challenging the status quo, event-driven architecture (EDA) is the champion of modern software systems that has disrupted the traditional ways of communication between applications. Instead of the old-fashioned request-response approach, it introduces a new and powerful concept: events. In a world that demands instant gratification, the asynchronous nature of events culminates in rapid responsiveness to real-time data.
It's no wonder that event-driven architecture is gaining immense popularity in the tech world. 72% of global businesses have already hopped on the EDA bandwagon, and the trend is only getting bigger and better. So, what's the secret behind this surge in popularity?
A Decade In Data Engineering - What Has Changed?

The concepts and skills data engineers need to know have been around for decades. However, the role itself has really only been around for a little over 10 years, with companies like Facebook, Netflix and Google leading the charge. Throughout those ten years, there were significant breakthroughs and tools through hype, and general acceptance became stand…
End Of Day 104
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
I’m reading the 2nd Edition of Chris Date’s An Introduction to Database Systems (1977) as referred to by Dr. Ralph Kimball in https://www.kimballgroup.com/1997/08/a-dimensional-modeling-manifesto/. What I find interesting is dimensional modeling is not denormalized where it matters, in the fact tables, which are in third normal form. It’s only the dimension tables that are normalized for performance and understandability reasons. It’s really more of a reorganization than a normalization. Instead of relating general entities in 1 to many relations, we are relating dimensions through the fact tables.
You have written very well! Are there any upcoming posts by SeattleDataGuy about Kimball dimensional modeling or Data Vault?