
Layer by Layer, We Built Data Systems No One Understands
How data stacks turn into fractals
Hi, fellow future and current Data Leaders; Ben here 👋
Today I want to talk about data stacks and layering on complexity…
Before we jump in to todays article. I wanted to let y’all know that today’s article is sponsored by me, the Seattle Data Guy!
Our team has helped dozens of companies turn data in to actual business outcomes. We’ve also helped companies set-up their data stack from the ground up as well as untangle their current data infrastructure. If you’re looking for an experienced data consulting team to help you set-up your data infrastructure and strategy, then set-up some time with me today!
Now let’s jump into the article!
Tech folk are like onions; we have layers.
Actually…its more like we love the idea of layers.
Network layers.
Medallion architecture.
Layer, after layer, after layer.
On one side, these layers help delineate where on process or job starts and another ends..
But on the other side, we tend to keep layering more and more layers on top of each other. Adding new roles, new tools, new platforms.
All to make things “easier”.
Think of the Modern Data Stack.
Snowflake, Databricks, and all the other tools. They did make things easier in so many ways. But also, I’ve helped companies save millions on compute costs.
Many times, because data teams kept adding layer upon layer that just needed to be removed.
Don’t worry, we’ll discuss that later. Let’s start by discussing the pros and cons of systems and tools that make development easy.
Our Solution Makes It Easy - How It Happens
Every generation of tools promises the same thing:
“We’ll make this easier.”
What they actually do?
Add another layer.
I just read an article discussing how Databricks is trying to position itself in that light.
All that made me think of was one of the first articles I wrote nearly a decade ago. I was talking about Tableau and how the fact that it was so easy made things dangerous.
And I can tell you from experience this is true and it’s helpful. You can test out new ideas, dig into data faster, etc.
Of course, simply pumping out more code, more dashboards, more artifacts..more layers…faster has never been the key problem. In fact, in many ways, it’s created its own set of new problems. You’ve got to deal with every type of sprawl under the sun.
BI sprawl
Pipeline sprawl
Model sprawl
Agent sprawl
Cost sprawl
System sprawl
The image below, doesn’t even show all of that. And it’s also starting to sprawl and in each of those boxes is it’s own complex sprawl of code, dashboard metrics, calculations, and locally optimized workflows.
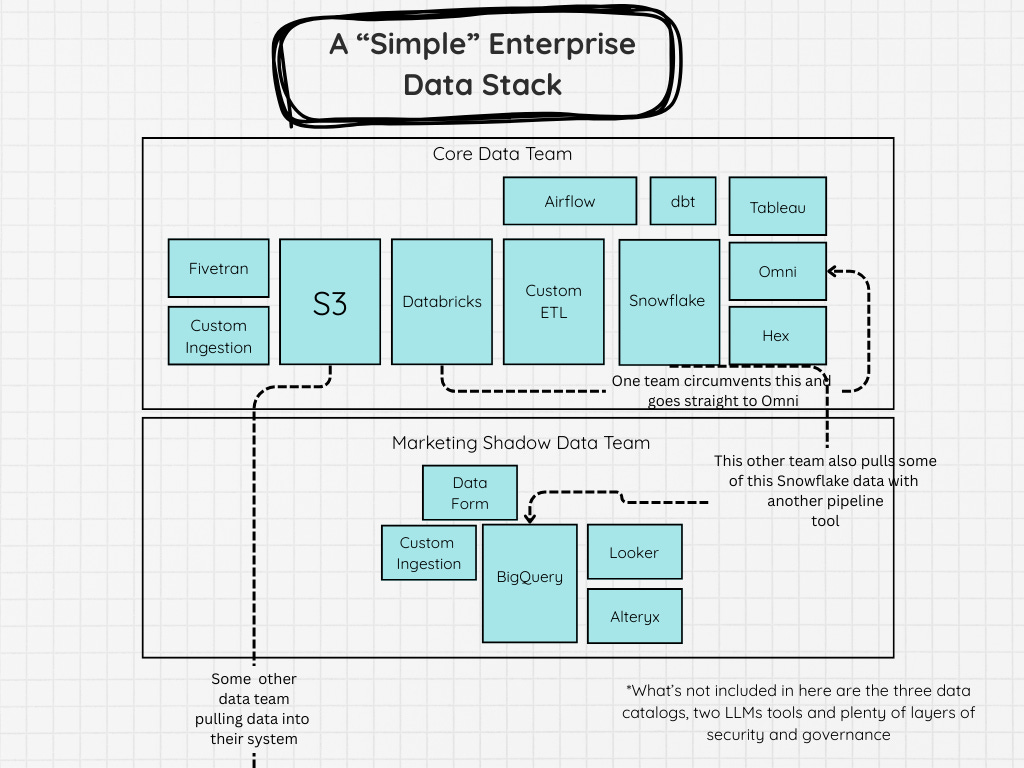
These systems end up like fractals. Every box you go into has yet another set of boxes, and arrows.
There are many reasons for this.
A department head wanted to run their own AI/Data project
The data analysts and engineers wanted to use different tools
No one wanted to actually make a decision, so you picked all the tools
Outcomes were not the key focus
This can create costs that explode and systems that become harder and harder to maintain.
And no amount of data governance lathered on top of all this will make it more sane.
You’ve got a data catalog for your data catalogs because hey, why not!
You’ve got orchestrators for your orchestrators.
And you’re ingesting data from your ingestion tool about how your ingestions are running.
We’ll likely need AI not only to develop code faster but to understand what in the world is going on inside some of these spaghetti systems we are constructing.
The Devil’s Advocate - Spending More On Tech Makes Sense No?
But let me take another side to this.
On the flipside, some companies I’ve worked with didn’t have full-time data engineering teams or had far smaller ones than in the early 2020s.
Sure, in some cases, maybe they spent an extra $125k a year on Databricks and or Snowflake….
But they saved a significant amount on hiring a DE team. Based on the average data engineer salary, if you can cut 2 from your team and spend an extra $125k on Snowflake and Databricks…thats not a bad deal.
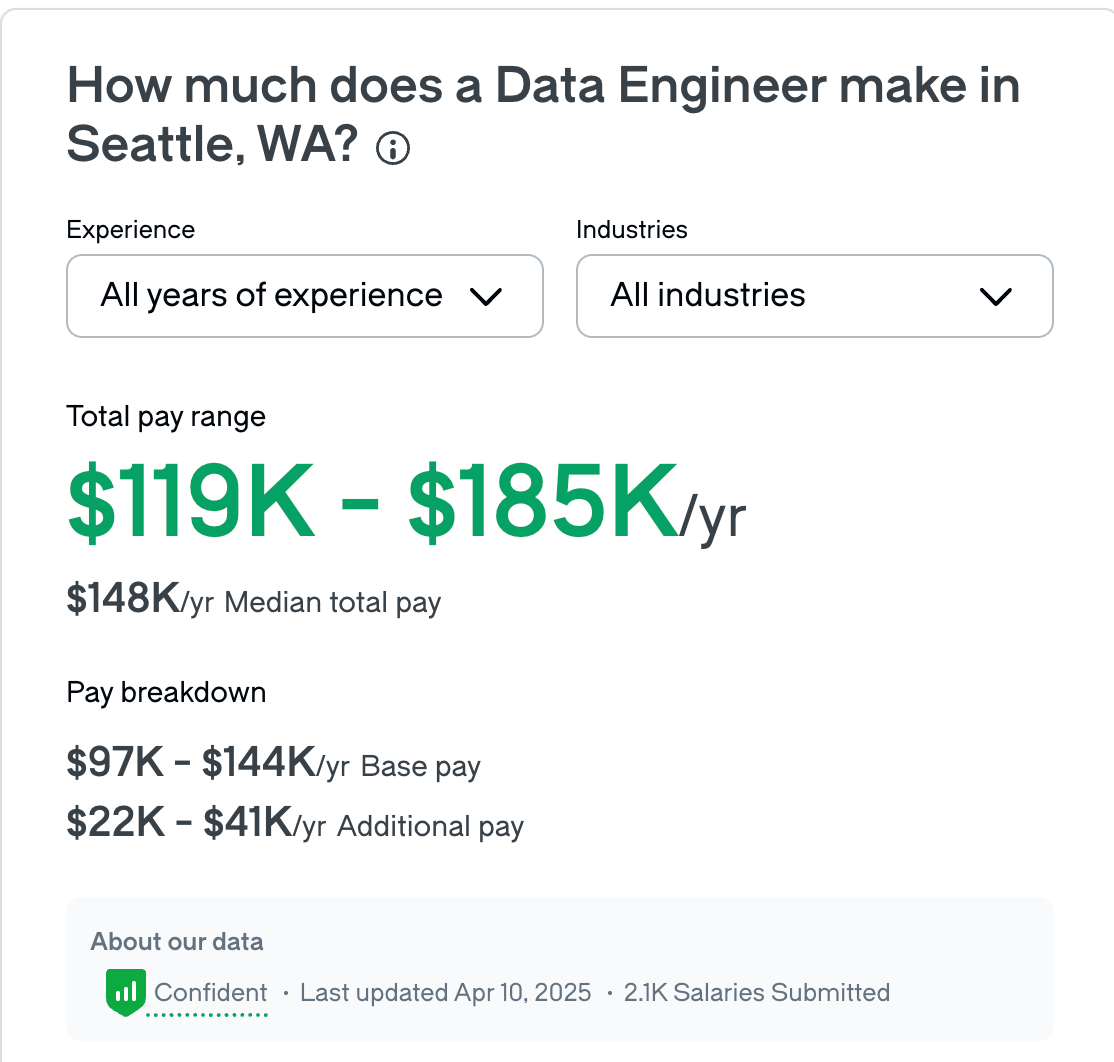
We are removing people from the layers and replacing them with technology!
Yes, there might be some random scripts calling other random scripts, but it all works right?
I actually recall one friend making a joke about this where they referenced the fact that, sure, a company could put effort into optimizing their data model, their data pipelines, etc.
Or, they could crank their Snowflake instance up a few notches, pay a little more, and fire half the data engineering team, and it would be significantly cheaper.
Some companies are essentially doing this now. Instead of paying a full-time data engineer, they hire someone to help set up their data stack and then come in every so often to simply maintain it. I know, as I’ve been that someone.
The Realities Of What This Leads To
Here are some realities I believe we will continue to see in this AI-driven data world where we seem to building yet more technical layers.
Business Logic Bloat Will Only Get Worse
When dbt became popular one thing that many data teams found is that model bloat was real. You’d keep building out more and more models now that a broader set of users that manage to obfuscate hidden business logic.
The easier it is to translate business logic into code, the more you take out of peoples brains and put it into technology. In some ways thats great. In other ways, some decisions made will be to try to get code to cover even more edge cases than we have in the past. Because, why not? Just ask your LLM to code one more, it has 0 cost to you?
People Will Still Struggle To Connect Things To The Business
I believe despite being able automate more and do more technically speaking. Teams will still run into a similar problem that we have today. At least until LLMs figure this out. That is that people will still struggle to connect business value to technical output. We gave more people access to data, yet many companies are still struggling to answer basic questions and in turn struggling to make decisions. Some of this, I believe is due team sizes and so many teams specializing in technologies vs. the business. So there is a chance, that we might be able to avoid this, but I don’t think we will(at least not for a while)
The Fractals Will Grow
In theory, I believe we should take some of this tooling, LLMs, etc and in turn start removing layers of tech to simplify tech stacks. In reality, this is not what I see. I love that Joe Reis pointed out the 37 tool data stacks from the 2020s. He might even be under counting.
Data stacks weren’t just ETL, data warehouse, data visualization and data catalog. I’ve come across, ETL → Data Lakehouse → another ETL tool and orchestration tool → dta warehouse → yet another ELT → database →semantic layer → six different BI tools. Not to mention some custom code in between!
I don’t think we’ll be getting rid of that. I think most companies will just layer AI on top of all of that.

We Are Growing The Pie Of Automated Use Cases
I do think will grow the pie in terms of how easy it is to build automated use cases. Whether the results are better is hard to say. I lean towards the side of, most people will just add complexity for complexities sake because that’s what I’ve seen in the prior few hype cycles. Some tooling expands the usage of a popular idea.
Machine learning becomes popular - Here are some Python libraries you can use to implement models without understanding them. You’ll still struggle to find good places to implement them as well as know how to properly deploy them.
Big Data becomes all the rage - Here are some tools that makes handling big data easier. Companies will still struggle to become data-driven and dashboards still take too long to load.
I am sure you could find even more examples there. Technology makes a lot of things easier but it’s still challenging to connect good ideas with outcomes.
Tactical Take Away
Before adding another layer, ask yourself three questions:
What problem does this layer actually solve? - I find many engineers become a “Snowflake” Data Engineer or “Databricks” Data Engineer, which sure, that’s great. But, you eventually get so divorced from outcomes that you can easily end up creating layers and work for the sake of it.
What happens if we don’t add it? - More often than not, the answer is “nothing breaks.” and “We actually now need to hire someone to take care of this layer”.
Who owns it six months from now? - Because every layer eventually becomes someone’s problem.
If you can’t answer all three clearly, you’re not building leverage.
You’re building liability.
The goal isn’t fewer tools for the sake of it but nor is it more for mores sake.
The goal is a system you can actually understand, maintain, and tie back to the business.
And that takes more effort than just signing another contract for a new tool or building another ten dashboards.
As always, thanks for reading! I hope to see you in the next one.
Articles Worth Reading
There are thousands of new articles posted daily all over the web! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
From “Vibe Coding” to Guided Coding
Enterprise engineering teams face a paradox: while generic AI tools increase individual speed, they often introduce unpredictability, security risks, and technical debt at scale.
This white paper details a pilot program conducted by Brainly in partnership with Codestrap. By deploying Larry AI, an agent powered by X-Reason™ technology, Brainly successfully demonstrated that guided workflows can outperform generic AI tools in reliability, cost, and safety.
The pilot focused on “LLMifying” Brainly’s complex Data Access Object (DAO) layer and building custom Larry AI workflow for this area of the codebase. The results were decisive: Larry AI achieved 90% one-shot correctness , reduced inference costs by ~96%, and-most critically-enabled mid-level engineers to safely ship code that previously required deep domain expertise.
Speed Without Understanding - One of the Biggest Risks in Data Engineering
“I just nuked all our dashboards.”
That’s the title of a heavily discussed post on the data engineering subreddit(Post and link included at the bottom of this section). When I first read it, I assumed the author was going to talk about deleting all their dashboards, no one noticing, and then wondering if their job even mattered.
That wasn’t the case.
End Of Day 212
Thanks for checking out our community. We put out 4-5 Newsletters a month discussing data, tech, and start-ups.
If you enjoyed it, consider liking, sharing and helping this newsletter grow.
so many dbt models feeding so many power bi models yet the business can’t answer simple questions without talking to an engineer, manager, and 3 analysts.
Sadly, so many of the issues that come up in the supposed paradox can be easily mitigated if the right principles / practices are in place.
For instance, sure, engineering teams will allow increased individual speed but if the team is using the same ruleset then they will all move at the increased speed, together, with very predictable failure modes.
The issue is when one person is moving at 100mph and another is at a variable speed between 60-80mph and the rest of the team is at 40mph. Imagine if everyone was running at 70mph, together. It's like how cycle teams win as a team by coasting at the same speed, even if one has intrinsically more horsepower.
It's the delta between humans, not just the models or agents they use (or refuse to use).