
Full Refresh vs Incremental Pipelines
Tradeoffs Every Data Team Should Know
Hi, fellow future and current Data Leaders; Ben here 👋
Today I wanted to get back to talking about data pipelines!
Before we jump into today’s article, I wanted to let y’all know that today’s article is sponsored by me, the Seattle Data Guy!
Our team has helped dozens of companies turn data into actual business outcomes. We’ve also helped companies set up their data stack from the ground up, as well as untangle their current data infrastructure. If you’re looking for an experienced data consulting team to help you set-up your data infrastructure and strategy, then set-up some time with me today!
Now let’s jump into the article!
The need to extract and centralize data…surprisingly…remains a challenge.
Perhaps in the future, when we can all vibe code our own apps on Snowflake or Databricks Postgres services, and the line between analytical and operational data stores blurs further, we won’t need this.
But for now, even small organizations can have dozens of data pipeline solutions pulling out data.
It’s easy: find a reliable data connector solution, build a few dbt models or some drag-and-drop solutions, and you’re done.
Of course, it’s not that simple. As part of the process, you need to consider how those pipelines will actually load data into your tables.
Which also means you need to understand your data.
Is there an update date? Can it be updated? How is it updated?
From there, you can start understanding how you want to build your data pipeline.
Bringing us to today’s topic, incremental and full table refreshes.
So let’s dive into it!
Why Does This Even Matter?
At first glance, this might seem like a small implementation detail.
After all, a pipeline is just moving data from point A to point B, right?
But the way you design your pipeline matters. It has implications for how reliable, affordable, and scalable your pipeline is, not to mention the fact that different data platforms can limit how you implement your pipeline.
The difference between these patterns affects:
Compute Costs - This is likely the most obvious. If you rebuild a 1TB table every day with a full refresh, your warehouse bill will look very different than if you only process the new 5GB of data that arrived today. Both your data team’s spending and wait times will increase. Of course, you could still be on-prem, so it might not be an actual cost and more of a performance issue.
Ease of Implementation - Using create and replace make your pipelines very simple to implement. There really isn’t much design at all to it. Just have a CREATE AND REPLACE over a SELECT statement, or if you’re using dbt, just have it recreate every time. Done. Whereas, with incremental loads, you actually have to understand the underlying data, gross…who wants to do that?
Backfilling - Both patterns have different pros and cons when backfilling. Say, for instance, you’ve got a rather large table that takes a long time to reload. If you’ve got to do a full refresh, recreating can be painful(of course that also means, everyday the pipeline is taking a long time to run). But if your table is small and you don’t need to consider past data, it’s very simple. Click rerun, and done!
Handling Updates and Deletes – Not all data sources behave the same. Some append data forever. Others constantly update rows or delete them. Your pipeline design needs to account for whether you’re dealing with append-only logs or mutable records.
Tooling Constraints - This is more of a consideration vs an impact. Your data platform also influences what’s possible. Redshift was one of the first platforms I ran into where this was a reality. Early on, MERGE wasn’t possible. Meaning the way you designed your pipelines changed. The same thing could be said about insert and overwrite tables.
Enough about considerations and impacts, let’s talk about these two common patterns.
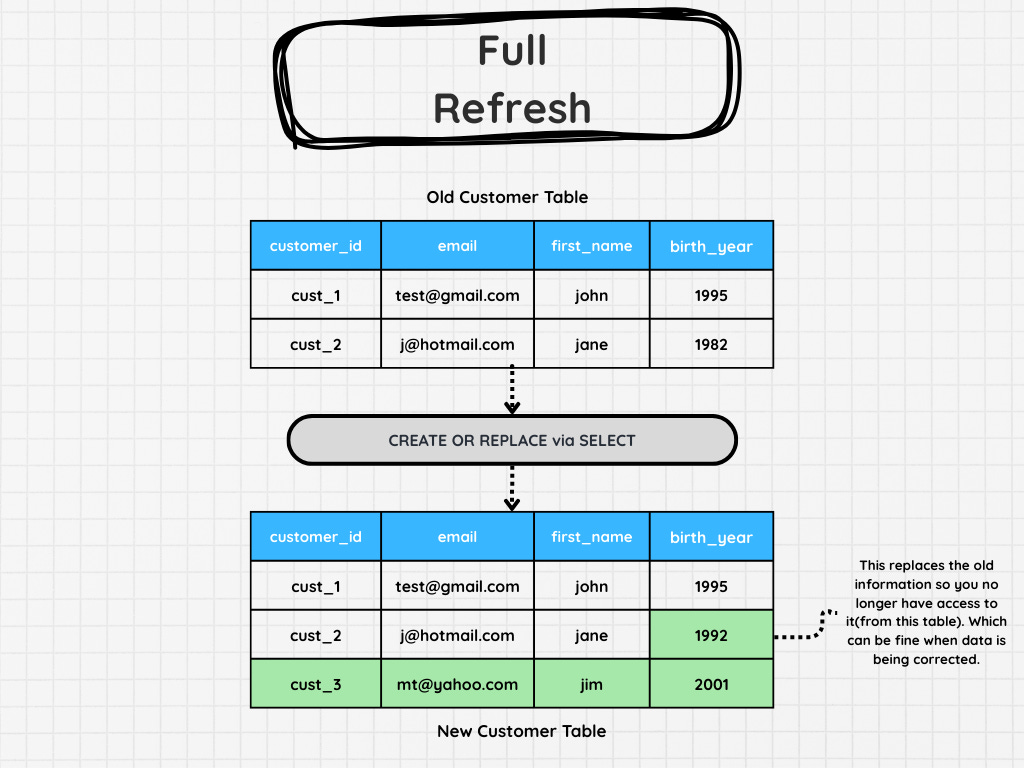
Full Refreshes
This pattern is likely the most obvious and simple pipeline to build.
You’ll probably build this type of data pipeline by default.
As the name suggests, you are just replacing all the data via a full refresh.
All you need is a create and replace. Of course, there are other steps you might put prior to the final “CREATE OR REPLACE”
For example, you might use the WAP pattern, as some people have coined it, or write-audit-publish
The flow usually looks something like this:
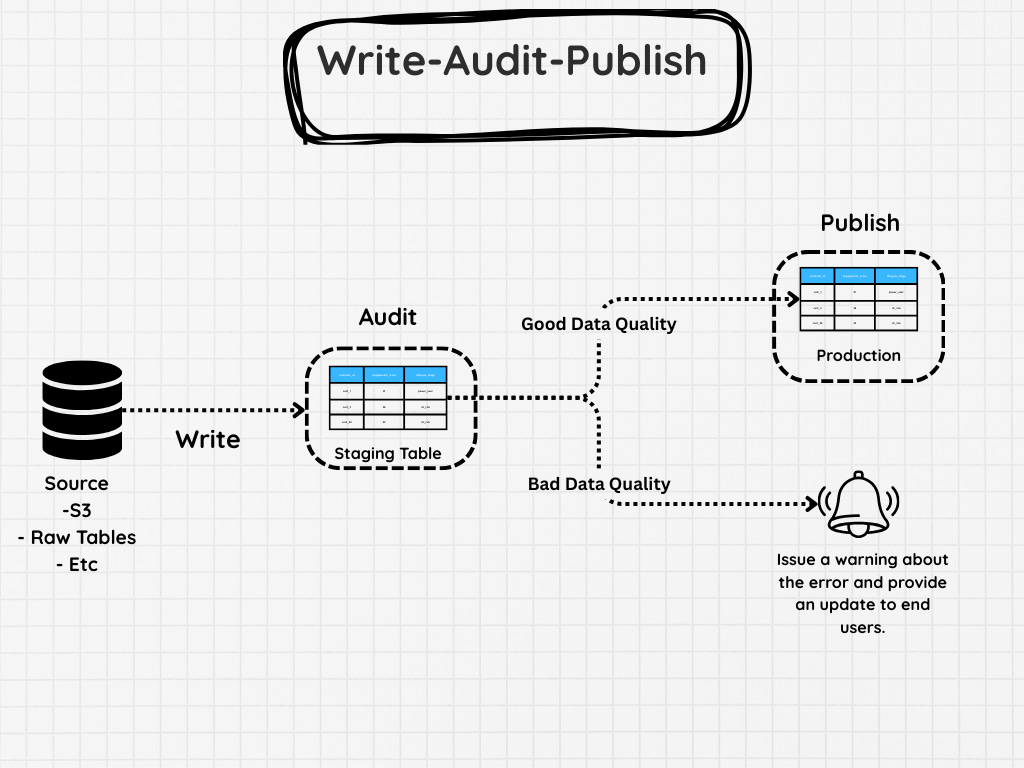
Write – First, create a staged version of the data set. This might be a full transformation from the source system or a large query that reconstructs the table.
Audit – Run data quality checks on the staged data. These might include things like:
Row count comparisons with the previous version
Null checks on required columns
Duplicate key detection
Validation that key metrics are within expected ranges
If any of these checks fail, you stop the pipeline before the production table is touched.
Publish – If everything looks good, then the data can be promoted to production.
Pairing this approach with a full refresh adds a layer of safety. Instead of modifying your production table directly, you only publish data that has already passed validation. But of course you can do something similar with incremental patterns as well.
Going back to full refreshes, let’s talk about when these work well.
Full refreshes works especially well when:
The dataset is relatively small
Rebuilding the table is inexpensive
The underlying data does not have reliable change tracking
Simplicity is more important than efficiency
However, as tables grow larger, refresh windows shrink, or stakeholders expect fresher data, full refresh pipelines start to break down.
That’s where the second major pattern comes in.
