
5 Things in Data Engineering That Still Hold True After 10 Years
Why core challenges in data engineering resist the test of time
Hi, fellow future and current Data Leaders; Ben here 👋
When I first started in the data world back in 2015, Hadoop was everywhere. Hortonworks, Cloudera, MapR, all promising to reshape the future of data. Fast forward a decade, and many newer practitioners don’t even recognize those names. And yet, for all the hype cycles and shiny new platforms, so many of the fundamental challenges in data haven’t really changed.
But before that, if you're a data leader looking to understand what is going on in the broader data world as well as elevate your leadership skills, I recently released my self-paced Data Leaders Playbook Accelerator. If you'd like to check out the program, you can sign up here.
Now let’s jump into the article!
When I started in the data world back in 2015 Hadoop was at it’s peak.
Actually I happened to be scrolling through an old instagram account and found a picture from a DAMA conference where Horton Works sponsored it(you can see it below). At the time, Hadoop and its ecosystem were everywhere, Hortonworks, Cloudera, MapR, each promising to reshape the future of data.
Fast forward just ten years and many newer practitioners don’t even recognize those names. And yet, in data engineering, a decade is barely enough time for fundamentals to change. Underneath the hype cycles and new logos, many of the same challenges remain.

1. Schema Design and Data Modeling Remain Essential
How some companies approach data modeling has changed in the past decade since I first opened up Kimball. Many now lean on date partitions and table overwrites to simplify how they track history, instead of slowly changing dimensions.
In addition, AI is beginning to influence the conversation. Tools can now help generate schema recommendations, flag inconsistencies, or even propose transformations based on usage patterns(actually this was going to be the project I took on at Facebook prior to leaving).
But while those capabilities are new, the fundamentals of data modeling haven’t really shifted. You still need to intentionally decide how to represent entities, relationships, and history in a way that the business understands and the system can scale.
In fact, many tools, even those with some level of AI capabilities require you to set-up a semantic layer or an ontology. There is still the need to be intentional with your data.
Whether you’re using a star schema or or a denormalized wide table, good models require deliberate design and trade-offs. The tools may automate pieces of the work, but they can’t replace the judgment that goes into structuring data so people can actually use it.
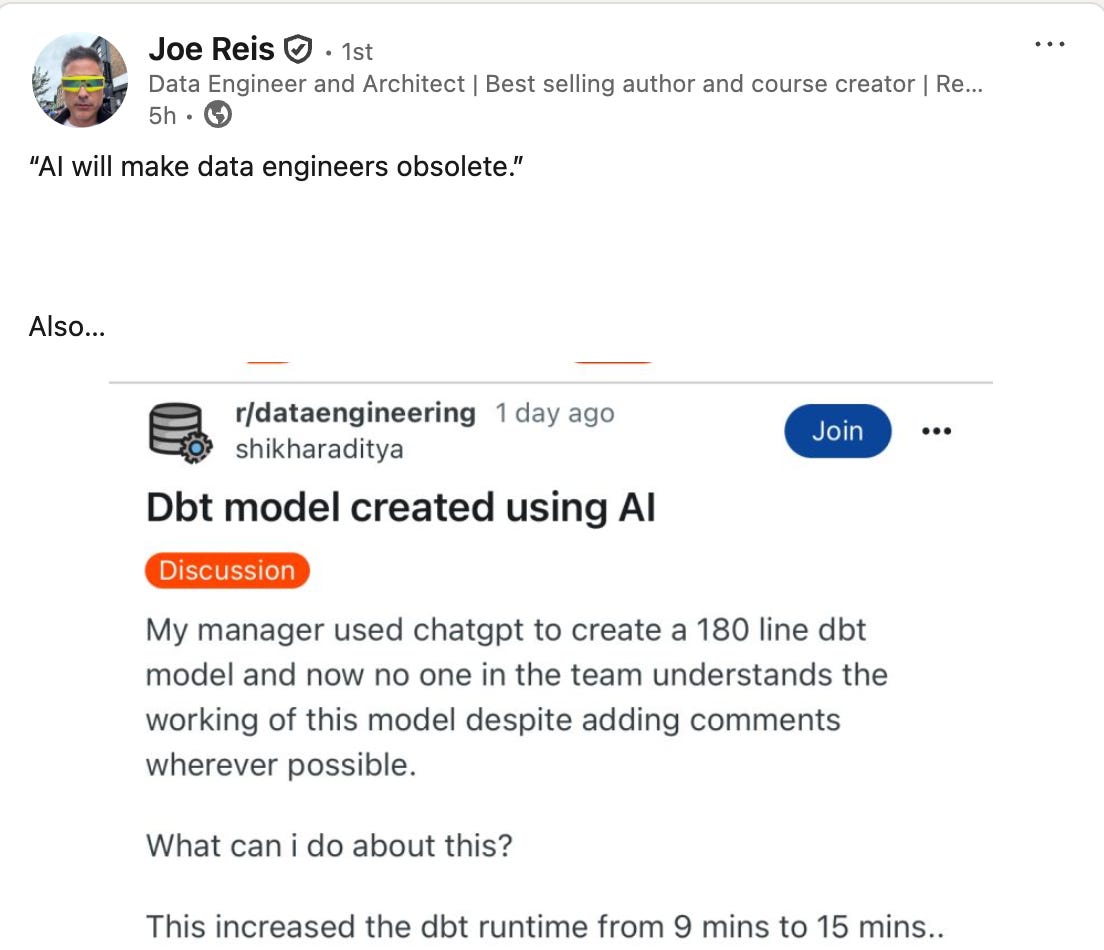
Or maybe, you’ll end up like the reddit post below, thanks Joe Reis for capturing it (although I do often wonder if some people are just trolling).
2. Data Quality and Validation (“Garbage In, Garbage Out”)
I often wonder how long the GIGO phrase has been around. Who said it first, and was it referencing data?
It still gets thrown around a lot today because, even in the age of AI it can be difficult to get quality data. In many ways, it’s only gotten harder.
Companies want more sources than ever, and that means more opportunities for errors, mismatched definitions, and conflicting values.
Even when the data itself is “accurate,” it may be incomplete or missing the context needed to make a good decision. A customer record without a region, a transaction without a timestamp, or a product without a category, all technically correct, but limiting the questions that can be answered.
This is where data engineers continue to step in. Not only in terms of creating data quality checks, but also advising what data should be added in or tracked to better answer key questions.
The business always has lofty goals, but if you don’t have the right or accurate data, you won’t be able to answer the questions or build an AI no matter how hard you try. As in the words of Sir Arthur Conan Doyle's Sherlock Holmes, Data! Data! Data! I can't make bricks without clay, and you’ve given me sand.
3. Dashboards And Queries Are Still Slow
Back in my first database course, my instructor told us about his consulting work. Time and again, clients would bring him in to fix sluggish queries. After a bit of review, he’d add an index and suddenly the performance issues would disappear.
Fast forward a decade, and I still see the same story play out. Many dashboards and queries are built and slow down over time. The dashboard that initially wasn’t so bad taking three seconds to load now takes thirty.
Often the solution is straightforward, add the right index(if you’re on a system that has indexes) or pre-aggregate the data. Neither is a silver bullet, and both should be applied thoughtfully, but the number of times I’ve seen dashboards go from minutes to sub-seconds is still remarkable.
Despite advances in hardware and cloud databases, it doesn’t mean you can always just select a larger compute instance. At least, not without your Snowflake bill growing.
4. Batch Processing Is Still The Backbone Of Most Data Platforms

Another thing that has changed over the past decade is the sheer amount of companies building some form of data pipelines.
And it’s not just the number of companies, it’s the number of pipelines within each company. When I was at Facebook, some teams managed over a thousand DAGs. The sheer volume of data workflows has exploded, and orchestration platforms like Airflow, Prefect, and Mage now exist largely because of that scale.
But despite all of this growth, the foundation hasn’t really shifted: batch is still the default.
Most data moves in scheduled chunks and nightly loads. Streaming pipelines have matured and found their place. Especially when it comes into operational analytics and workflows.
But for the majority of use cases, batch remains the default.
Ten years ago, your ETL job was a cron script running at midnight or an SSIS package being kicked off by SQL Server Agent. Today it might be a serverless job triggered by EventBridge or an Airflow DAG. But it’s probably being run on a schedule at a specific time, and moves a date window worth of data over to your data warehouse.
5. Business Alignment Trumps Tools
I am putting this last because, well, I write about this a lot and I assume it can get some what repetitive. I’ll have to get back to talking about columnar storage, data warehouses and the joy of pulling data from SFTP servers after this article.
But it deserves the final spot because in the era of AI, it’s more relevant than ever. Just because we can move faster, deploy bigger models, or automate pipelines doesn’t mean the work is actually useful. The hardest part of data engineering was never “can we do it?” but “does it matter?”
Will the business actually be able to support your new model that you’ve developed? There are always multiple initiatives that your CEO or VP is trying to drive forward, if your work is too far outside of that or doesn’t actually drive some clear value, it won’t matter what technology you used.
That was true ten years ago when Hadoop clusters were humming away, and it’s just as true today when AI copilots are writing SQL. The companies that win aren’t the ones with the flashiest tech stack, but the ones whose data teams stay tightly aligned with business priorities.
Final Thoughts
Over the past decade, a lot has changed. SQL is no longer “dying.”..wait nope just read another article apparently it’s dying again!
Snowflake, Databricks, and BigQuery have become household names in data. And an even broader range of companies now have some version of an analytics stack, on top of Excel, of course.
But for all the new tools, vendors, and buzzwords, the hardest problems remain the same. If anything, they’ve grown more complex as expectations around what data can deliver have exploded. At the core, though, most challenges still come down to two things, the quality of the inputs and the performance of the queries.
A decade from now, we’ll almost certainly be talking about another wave of platforms and paradigms, maybe beyond LLMs, maybe something none of us can imagine today. But if history is any guide, the toughest challenges will still be less about the tools and more about us, how we capture, model, and use data to answer real questions.
As always, thanks for reading.
Upcoming Data Events
Articles Worth Reading
There are thousands of new articles posted daily all over the web! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Full vs Incremental Pipelines
full, partial, or both? by Daniel Beach
This is another classic, isn't it? Some data questions have had folk spitting and fighting for nearly a few decades now. Funny, how nothing really changes, even in the age of AI.
Technology has undergone significant shifts from the days of SSIS to DBT. But, I still see the exact same topics being discussed and poked at all these years later. And I mean literally the same topics.
uReview: Scalable, Trustworthy GenAI for Code Review at Uber
Code reviews are a core component of software development that help ensure the reliability, consistency, and safety of our codebase across tens of thousands of changes each week. However, as services grow more complex, traditional peer reviews face new challenges. Reviewers are overloaded with the increasing volume of code from AI-assisted code development, and have limited time to identify subtle bugs, security issues, or consistently enforce best practices. These limitations can lead to missed errors, slower feedback loops, and other issues, ultimately resulting in production incidents, wasted resources, and slow release cycles.
End Of Day 191
Thanks for checking out our community. We put out 4-5 Newsletters a month discussing data, tech, and start-ups.
If you enjoyed it, consider liking, sharing and helping this newsletter grow!
You can post this every year and will be spot on every time 😅 I think that with new hype driven trends like databricks vs Snowflake, dbt vs SQLMesh, AI and the MDS speech we are always finding an excuse to avoid working on the right things, which are listed here and they will rock any other shinny project that involves AI or similar
I agree with all five points, and generally I’d add that if you’re an actual data leader get good at ignoring hype cycles. Not that you shouldn’t examine new tech, but most of it isn’t going to help you that much and is often just putting lipstick on the metaphorical pig of existing solutions.