
Why Low-Code/No-Code Tools Accelerate Risk
And How Your Team Can Reduce It
Creating systems and automated workflows has often been viewed as an engineering team’s responsibility. However, I continue to run into companies that have more and more teams creating integrations and workflows with low code and no code tools.
Some may act as if Low-Code/No-Code is some new invention, but it's far from it. We’ve had solutions like Excel, SSIS, and Tableau for decades. All great examples of tools that allow individuals with limited to no programming experience the ability to automate and process large sets of data.
Even integrate data into operational workflows.
And now with tools like GitHub Copilot and other similar solutions, we’ll likely continue to see a broadening in terms of who can automate and develop whether the IT team wants it or not.
But with that comes a problem
That is, these workflows are systems and ones with company-impacting effects but they are being treated as quick fixes or lightweight patches when they are so much more.
📝 Main Take Aways
Low-code solutions help you develop workflows faster and they also can help make bad decisions faster.
If you’re going to build solutions that developers generally build, then you should adopt processes that developers use.
Low-code workflows don’t often operate in a vacuum, so consider maintenance, monitoring, and the future.
How Low Code Can Turn Into Chaos
Whether you’re using a drag-and-drop solution or having ChatGPT write code, you’re starting to create new systems, and what’s worse at a far faster pace than before.
Or as I usually put it…
Low code solutions help you make bad decisions faster.
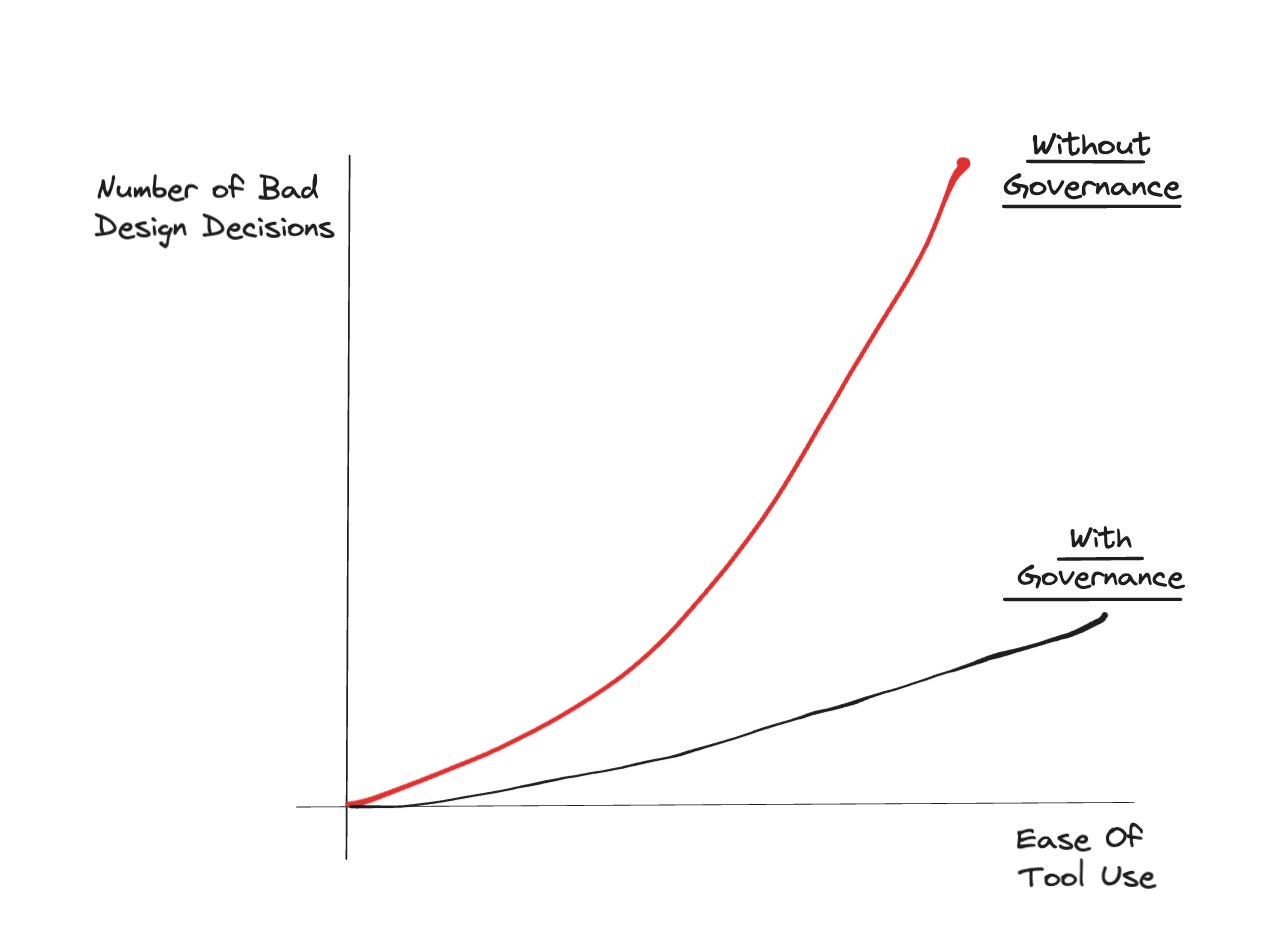
It’s one thing for an individual to create a table or Excel workbook(of course even then you could cost your company millions) that only their team relies on. However, now I am talking with PMs, marketers, and ops teams who are building crucial data flows for the business; as in, it's not just reporting but it's part of how your business operates. You’re re-ingesting, reintegrating, reverse ETLing(what ever you want to call it) data that hasn’t been tested back sometimes to customer facing systems.
That’s fine, but many build it and assume it’ll now function as expected forever.
I find data sets are the easiest way to think about the impact that can occur without proper testing(probably because I am a data engineer). But often you’ll have what happens in the image below be your reality. One person uses a low-code solution to build something for themselves, it's got limited testing, no one knows who owns it (because the original creator quit), and now everyone relies on it and it’s going into HubSpot to be sent out in some email update.

I don’t think there is any putting the genie back in the bottle at this point but hopefully we can try to put some level of governance around these newly developed systems.
Some data engineering teams for example are trying to discover these one-off builds so they can better manage them. In fact, I recall one director telling me they’d analyze query patterns to search for these behaviors to find tables that the data engineering team didn’t own and were at risk so they could bring it into DE’s ownership (and it was something I was going to work on at FB before leaving)
The point here is that as you build out automated integrations and workflows, even if it’s just drag and drop, there are implications.
What you build has second and third-order effects.
Someone will build on top of what you've built and eventually something will break.
How Your Team Can Reduce The Risks Of Rouge Workflows
As I referenced earlier, there really isn’t anyway to close pandora’s box at this point. In turn, that means we should both encourage business teams using these solutions to adapt some of the process below as well as try and place governance and guardrails on what can be impacted.
Create a Clear Process For Defining And Building
Define Your Tasks Goal - One of the first mistakes you’ll make, whether you’re an engineer or a marketer (and perhaps this is me projecting), is not clearly defining your goals or your end-users’ goals. The problem here is you can quickly go from “Hey we need a dashboard” to eight months down the line still polishing and changing the dashboard because you never clearly defined the goal or scope of the project. This ensures you don’t spend too much time as well as reduces the constant re-working of formula’s and patches you’ll put in to place to make your metrics work.
Map Out The Process - Part of what puts both engineers and semi-technical business folks at risk of failing is not mapping out the business process. What is it that you’re exactly trying to accomplish? How does your end-user or customer experience the flow? Are there different paths they might take? You need to map it out so you can emulate it via your new automated drag-and-drop process. Truthfully, this is part of the reason I have been writing about data modeling so much. It’s a process that forces you to review your business and how it operates.
Develop And Iterate - Whatever you build, you don’t need it to be perfect on day one in terms of what functionality you give it (you should aim for as few errors or bugs as possible). But functionality can always be added. So build out your initial system, see how it is used, and then, based on how users rely on the systems, build it out more. Otherwise, you’ll do what I’ve done in the past which is never really release your system until its far too big and doesn’t really meet your end-users needs.
Go Through Engineering Review and Testing Processes
If you’re going to perform work that an software engineer, data engineer or enterprise engineer usually takes on, you should go through similar processes.
Design Reviews - As you build out new systems, a good step in your process is to review your design and implementation plan. Allowing more people to review and comment on your design can bring out new issues you may have not considered. Perhaps you didn’t realize something about the business in terms of business logic that another coworker calls out. It also is just a good gut check to make sure your team doesn’t commit to a large project that might be going in the wrong direction.
Code Reviews - Now, when you implement a no-code drag-and-drop solution, you likely don’t have code to review(by
). But you can still have someone go through and make sure you’re following some set of standards. For example, let's say you’re creating a new table; are you using all the correct standards for naming? Are you being consistent on how you use terms like cost, amount, sale price, etc?Are there obvious issues or bugs you're implementing? Sure you should catch many of these yourself, but you likely won’t In turn having someone else go through and review your new automated process helps reduce future issues.
Unit Test - Similar to code reviews, you’ll likely have to implement these in a slightly different process. A unit test(by
) is a type of software testing where individual components or functions of a program are tested to ensure they work as intended. So perhaps you create some set of data inputs with a clear set of outputs and make sure to run them through every time you make a change to your no-code process. It’ll help ensure that you avoid any unexpected behaviors. Trust me, even a small name change can cause entire workflows to fail, so maybe you should also consider integration tests.
If you want to work on problems that engineers do, then you need to go through our processes.
Don’t Forget About Future Maintenance
Once you’ve built a dashboard or an integration, it doesn’t live in isolation. Changes will come. The ERP that you’re integrating will be replaced. the version of a software updates or a name of a data field changes. Who will own and fix these issues?
Ownership and Maintenance
Define Who Will Own and Maintain - One of the issues I see pop up on multiple projects is not that integrations and data workflows don’t exist, it's that no one really owns them. Perhaps this seems like a non-issue. If the workflows operate, why does it matter?
Well, in general, the workflows and systems eventually need to be updated or fixed and who should do that? This became such an issue for Airbnb that they eventually had to start hiring more data engineers to manage their data pipelines. They had SWEs and data scientists building data pipelines but no one really maintained them.
In turn, ownership is crucial.
Monitoring - Alongside ownership goes monitoring. You shouldn’t just build a system or workflow and assume it continues operating. There needs to be some level of monitoring, even if it's a simple Slack message that yells at you when bad data is processed. You need to ensure that you know all the processes that are occurring, occur as expected.
Document
Ink is better than the best memory.
User Guides and Run Books - Personally, if you build out a solution that occasionally requires manually running or fixing, then creating a run book of possible known issues can be very helpful. For example, I once created a guide to help users know how they could manually kick off a reporting process for a company just in case they needed a report outside of the normal cadence. This not only supports the use case I just referenced, but can also help end-users understand how the system works as a whole.
Record Changes and Why They Were Made - As your team goes through and makes various design changes or decisions, you’ll want to track why. Was there some logic you implemented or exclusions of users? Why? What is the impact? Who made that decision?
All of this is useful to know because, in the future, you’ll likely have another team member go through and possibly not know the reference to Chesterton's Fence.

General Documentation - One of the most common projects I get called into is key person dependency projects. This means someone used to work at the company, they quit, and now no one knows how things work. I am not saying we need to go back to the days where there were 200 pages of documentation, but a few light design pages can help save weeks of work.

Final Thoughts
Just because it’s gotten easier and easier to automate certain processes doesn’t take away the impact and possible chaos one of these systems can cause.
Thus, they need to be built with care. If you’re integrating two or three systems that help support operations, you better be sure that the data going in between points A and B is right. Otherwise, you might be creating a ticking time bomb. Perhaps not today, perhaps not tomorrow, but as more and more individuals build dependencies on your simple data flow, the more likely something will go wrong and cause a far more drastic outcome than you expect.
Developing more pipelines or dashboards doesn’t necessarily mean driving more value for your company. I think this comes out in tweets like the one below.
With that, I’d like to say thanks for reading.

Register now to secure your spot for Subsurface LIVE, the data and analytics industry’s first dedicated data lakehouse event.This year, in addition to delivering the event virtually we will be hosting the first day of Subsurface LIVE in-person in New York City. Best of all, attendance for both virtual and onsite experiences is completely FREE. We are excited to have over 46+ sessions, 4,000 + attendees, and 1,000 + companies participate. We look forward to seeing you there!
Thank you so much Dremio for sponsoring this newsletter!
Best AWS Services You Need To Know As A Data Engineer - How To Become A Data Engineer
Join My Data Engineering And Data Science Discord
If you’re looking to talk more about data engineering, data science, breaking into your first job, and finding other like minded data specialists. Then you should join the Seattle Data Guy discord! We recently passed 5000 members!
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
The Role of a Technical Program Manager
By
If projects were too large, you could add one or more Project Managers, but most of the time, these three units alone were sufficient to deliver in mid-sized contexts.
Today, the situation isn't much different; we still rely on these three main units and on project managers when it comes to building tech projects.
However, one thing has changed: complexity.
A couple of decades ago, the majority of tech projects were focused around web apps. Today, there's much more technology involved, such as cloud computing, containers, microservice architectures, mobile platforms, and AI, just to name a few.
Navigating the Pitfalls of Data Projects

Perhaps you’ve been on one of those data or software projects that just seems to be circling. It's been three weeks and somehow you’ve come to work every day, you’re tired, and you’ve solved problems but the project hasn’t really budged. What gives?
End Of Day 117
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
Ben I'm a big fan of all you do but this is a bit binary and short-sighted. Many low-code tools also offer Git-control like Coalesce or Orchestra. So Broad-brushing all low-code tools as being without Governance is just ridiculous
Faster often goes hand in hand with riskier. It's part of the game. As most of the things in business, low-code / no-code solutions shall be paired with good governance.