
Why Your Data Pipeline Probably Isn’t Production-Ready
And How To Fix It
You’ve done it!
You’ve built your first data pipeline. Maybe you’re a junior data engineer. Maybe you’re a data analyst shipping your first pipeline into the wild. Either way, you push it to the repo, cross your fingers, and hope for a quick “LGTM” from the senior data engineer.
Thirty seconds later: 10 comments. And a slightly horrified senior asking if this thing is even “production-ready.”
Production-ready? What does that even mean?
Your data pipeline gets data from Point A to Point B, isn’t that the whole point?
Well… not exactly.
In this article, I’ll walk through what production-ready actually looks like when it comes to data pipelines, and how you can design yours to survive review (and future you) with a little less pain.
What Happens When You Need To Re-Run The Pipeline - Backfilling

One term you’ll hear from a lot of data engineers is backfilling.
"Backfilling a data pipeline" basically means retroactively loading historical data into an existing table. This usually happens when:
A new data source is added
A system error occurs
Data quality issues are discovered
New columns need to be added and we aren’t able to use an update statement
At Facebook, backfilling sometimes meant re-running dozens (and I’m sure for some people, hundreds) of tables, which could translate to hundreds of partitions. And guess what? It was generally pretty easy to do.
You didn’t have to stress too much about duplicate data or where you might have issues with a pipeline, because those pipelines were designed to be backfilled.
But many aren’t.
A lot of pipelines are built to push new data in, with zero thought about what happens if they ever need to be re-run. And that’s where things get risky:
Duplicate Data: If the pipeline isn’t idempotent, re-running it can insert duplicate records, skewing analytics and reports.
Data Inconsistency: Merging reprocessed historical data with existing data can lead to conflicting or inconsistent results.
Pipeline Failures: Edge cases or errors might pop up when re-running data the pipeline wasn’t designed to handle.
Downstream Impact: Inaccurate or duplicated data can disrupt downstream applications, business intelligence tools, and data consumers relying on the integrity of your data.
So how do you avoid this?
You need to pause and actually design your pipeline to handle backfills gracefully, by deleting or replacing old data, versioning datasets properly, and handling pipeline failures intentionally.
A few common approaches to avoid duplicate data:
Deleting prior data by date: Very common with API ingests. If you’re loading data day by day, just delete the data for that day and reload it since many APIs ask for a start end end date to limit how much information you pull.
Using merge statements with a unique ID: Common when loading data via slowly changing dimensions since you can insert new records and update existing ones at the same time.
Store data with the file name: When loading files, store metadata like file names so you can easily delete and reload the exact same file without issues. Most common when using SFTP.
Partition data by date and overwrite: One of the simplest and most common strategies, especially at larger tech companies. There are a few ways I’ve seen it implemented. But essentially, every day, you load all the data for an entity into the table with a date stamp. You can read more about it here.
Deleting And Replacing The Old Table - By far the simplest approach is just to delete the old table and completely recreate it. This works when you don’t have a lot of data and you don’t need the prior data to calculate future fields. It does pose some issues such as if you need that table to always be available, then deleting it can pose a risk.
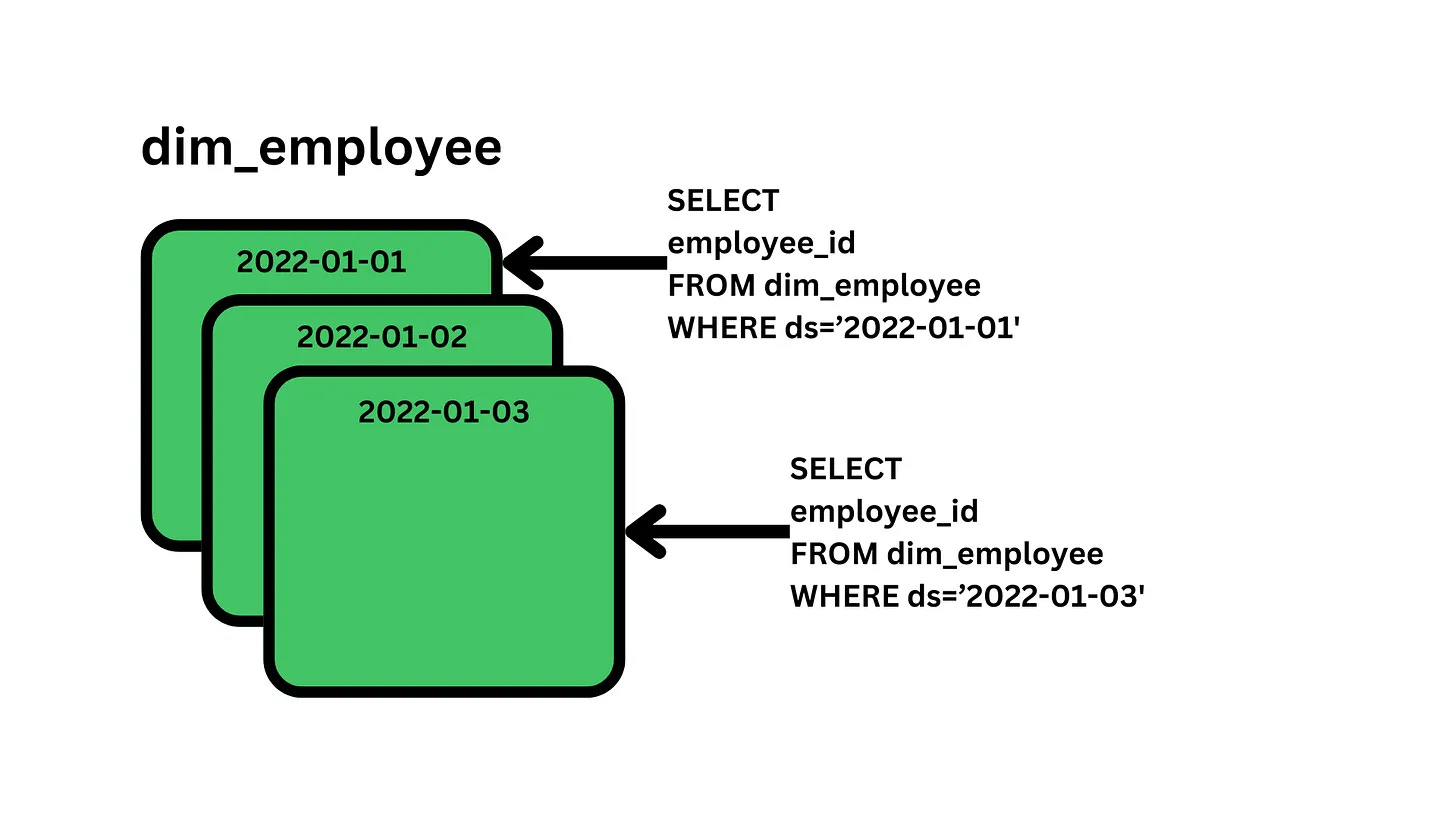
Each of these methods has its tradeoffs. The point is that you need to think through what would happen if someone were to re-run this pipeline. Whether the data comes from a file, an API, or prior tables, will it create duplicate data? Will it fail because the data doesn’t exist anymore?
How will you avoid that?
Because at some point, someone will re-run in, probably without thinking through all the edge cases.
That’s why it’s your job to think through it now (or, at the very least, leave them a run book).
Breaking Down Your Steps Into Logical Units

Have you ever opened up a SQL file and found… thousands of lines staring back at you?
It usually happens when a developer tries to do too much in a single step, subqueries stacked on subqueries, CTEs, endless case logic, etc. It works until it doesn’t.
This is one of the first big differences between a pipeline built for quick, one-off analysis and one that’s actually ready for production. It makes sense, cramming all your logic, data cleanup, and maybe even a little EDA into one massive SQL file or Python notebook can be tempting.
But that quick-and-dirty workflow becomes a nightmare when it’s time to productionize.
Refactoring a 3,000-line SQL script (that’s grown organically over months or years) is brutal. Every line, field, and logic was added for some reason, usually to meet a specific use case, and now untangling that logic is like defusing a bomb.
The fix? Modularize your pipeline.
Break your workflow into smaller, logical steps. Here’s what that usually looks like in practice:
Usually, there are some natural steps that can (and should) be broken down into their own temporary tables, views, or staging layers. Exactly how you do this will depend on your data size, query complexity, and your team’s standards.
Avoid duplicate logic. Having the same logic scattered in multiple places is a recipe for mistakes. If something changes, odds are you’ll forget to update every location, and that’s how bugs creep in.
Breaking down your workflow also comes with other benefits. It makes your pipeline easier to test, debug, and update over time (although it can be more difficult to track).
Unit Tests And Data Quality Checks
You’ve probably heard plenty of people talk about the importance of testing and building in data quality checks. Maybe you’ve even written a few yourself, anomaly checks or category checks to see if something looks off.
But that’s usually where it stops.
The reality is, across companies, people write SQL scripts… and never really test them.
Many people run into trouble when it comes to writing unit tests for SQL, either because they don’t do it at all or because writing tests purely in SQL isn’t exactly straightforward. There’s often no easy, built-in library to lean on.
(There are a few options as some tools offer data diffs, and some method of unit tests so you can ensure the logic changes impact your data set as expected)
Even at Facebook, at the time, all you really got was a box showing what scripts you did run, not a setup for SQL unit tests that automatically triggered every time you made a code change.
This is a key distinction I want to call out, the difference between data quality checks that run inside your pipeline while it’s running vs. testing the data pipeline after changing the logic.
There are tools out there that help with SQL testing, but if you don’t have one, here’s the general idea of how to approach it:
Create a test set of data.
Know the expected output of key columns, things like the number of account categories or the total revenue for an accounting report.
Write scripts that test one thing at a time. Keep simple SQL scripts that don’t have loads of complex logic.
The goal is to avoid hiding your logic inside another 200 lines of SQL, because that’s where mistakes love to hide.
In a perfect world, someone else on your team would write these scripts for your code. But in reality? It’s probably going to be you.
(Honestly, this feels like a great feature for Snowflake or Databricks to tackle one day. I’ve seen way too many teams manage this process manually, and I haven’t seen an amazing solution yet. Happy to be proven wrong).
And, of course, the other types of checks still matter, too, in-pipeline validations, post processing data quality checks, etc. These checks help ensure that if bad data sneaks into your pipeline, you’ll at least know about it, and, in some cases, stop the pipelines from pushing that bad data any further.
What About Monitoring and Logging?
Now, I’m putting monitoring, logging, and altering in here, but honestly, this should really be handled by whatever data platform you’re using.
If you don’t have this built-in, that’s more of a data engineering or platform problem, not necessarily something you should be rebuilding from scratch in every pipeline.
That said, there are still a couple of things you should absolutely be doing:
Log any key information while your pipeline runs, stuff that’s useful for debugging and maintenance purposes.
Set up alerts for failure or situations where you need to take manual action.
I can’t tell you the number of times a good log or clear error message has saved me hours of debugging.
Seriously, future you (or someone else on your team) is going to have to troubleshoot this someday. Don’t make them dig through a 3,000-line SQL script hunting for clues. Give them logs. Give them context. Give them a chance.
Building For Production
Writing a script that pulls data from point A and pushes it to point B isn’t where your job ends if you’re trying to build a reliable, production-ready pipeline.
A good pipeline should also be:
Easy to backfill
Built with quality checks, both before the code goes live and while the pipeline runs
Properly monitored and logged
Broken down into clean, manageable steps
Just shipping a 5,000-line query might technically “work”, but maintaining, debugging, or scaling is a nightmare.
So, before you hit push on your next pipeline, take a minute and really assess it.
Is this built for today’s use case, or is it built for the long haul?
As always, thanks for reading.
Upcoming Member Events
I have been working to add more and more value to the Seattle Data Guy Newsletter. As part of that, I’ve been running member webinars!
Here are the next three I have planned!
Breaking Into Data Consulting - From Marketing To Positioning - April 23rd, 9 AM MT
Dimensional Data Modeling Fundamentals - April 24th, 9 AM MT
If you’d like to be invited, then consider supporting the newsletter below!
Join My Data Engineering And Data Science Discord
If you’re looking to talk more about data engineering, data science, breaking into your first job, and finding other like minded data specialists. Then you should join the Seattle Data Guy discord!
We are now over 8000 members!
Join My Technical Consultants Community
If you’re a data consultant or considering becoming one then you should join the Technical Freelancer Community! We have over 1500 members!
You’ll find plenty of free resources you can access to expedite your journey as a technical consultant as well as be able to talk to other consultants about questions you may have!
Articles Worth Reading
There are thousands of new articles posted daily all over the web! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Enhancing Personalized CRM Communication with Contextual Bandit Strategies
In the competitive landscape of CRM (Customer Relationship Management), the effectiveness of communications like emails and push notifications is pivotal. Optimizing these communications can significantly enhance user engagement, which is crucial for maintaining customer relationships and driving business growth. At Uber, these communications typically begin with creating content using an email template, which often includes several components: a subject line, pre-header, header, banner, body, and more. Among these, the subject line and pre-header are especially crucial to email open rates. They’re often the first elements a customer interacts with and can significantly influence the open rate of an email. To overcome the challenges of static optimization methods like A/B testing, we use a multi-armed bandit approach called contextual bandits.
7 Real-World Lessons from Data Leaders at LinkedIn, Dropbox & More

Over the past few years, I’ve spoken with dozens of data leaders who were recently promoted.
Many had to spend time honing an entirely new set of skills while juggling some level of delivering on technical projects.
Others were suddenly being asked to make decisions on technologies that would impact their companies for years to come, often without being able to ask anyone else for help. That’s why, over the past few weeks, I have been hosting webinars asking data leaders from companies like LinkedIn, Dropbox, Carhartt, and several consultants to share their experiences.
These webinars focused on frameworks for better communication and on understanding the business better. They also explored several technologies so you can make better decisions about what to use for your team.
So, let’s explore these seven webinars, which you should watch if you want to take your data team to the next level.
End Of Day 173
Thanks for checking out our community. We put out 4-5 Newsletters a month discussing data, tech, and start-ups.
Thank you for sharing this.
Light has come, no more darkness(ignorance).