
What I Don't Want To See In The Data World In 5 Years
If you were in Austin this past week, perhaps you saw my talk about “things I don’t want to see in the data world in the next five years.”
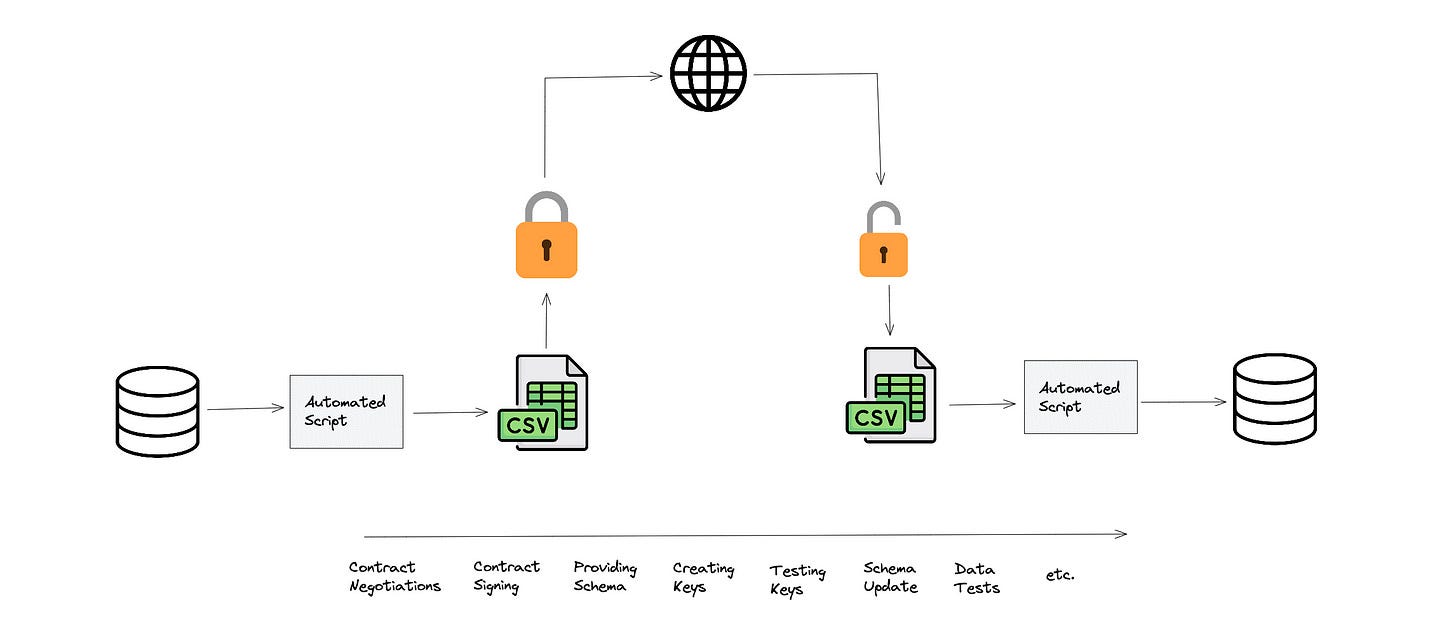
Maybe you’ve been lucky and never had to write an SFTP job.
You’ve never had to generate a ssh key pair (ok, you should probably know how to do this), and you’ve never had to spend several weeks just to get the schema from an external partner that will change by the time both businesses sign an agreement to work together.
I was not. Actually, in my very first role, where I had the official title of data engineer, our team would get datasets from 40-50 insurance providers that all came in via SFTP. Some of these files would be XML, CSV, TSV, and pipe-delimited, while others were positional files.
Additionally, each SFTP process could be slightly different, and you have to deal with many possible combinations.
SFTP was a reliable method of transferring data when other options were unavailable. But now, with the cloud, several future options are becoming available for companies to share data without ever having to write scripts.
In this article, we’ll discuss some of those options as well as how they can improve the current patterns.
Why Relying On SFTP Is Not Great
Many of you might not be familiar with SFTP; it stands for Secure File Transfer Protocol. You can use this protocol to send files from one server to another. Thus, many companies relied on it because it was a straightforward method to pass CSVs, TSVs, and every other file type.
However, now companies can have hundreds, sometimes even thousands of these jobs blasting data in every direction. They might not even realize some of these jobs are still even occurring.
Besides all the possible combinations of ways you can create keys or secure files, many other issues arise when you’re sharing data via SFTP. This includes:
Duplicate Data - You end up having to pull data that already exists into a CSV that you then send to another company that often takes a copy of this CSV and loads into another table.
Schema Changes - I have been on many projects where at the beginning of the discussion the schema file was sent over and by the time everything is signed, its drastically different/
Slow to Value - Because there are so many individuals involved, often what should be a simple SFTP job set-up can take a month or more.
Increased Maintenance - Adding more SFTP jobs and data pipelines just means more maintenance and future tech debt.
But we are no longer limited to just performing SFTP jobs.
Where Are Things Going
Ok, but how can we get to a Zero SFTP world?
Unlike Zero ETL, this is actually possible.
It’ll be difficult and it’ll require a lot of coordination. But there is a simple answer:
Data sharing.
Data Sharing
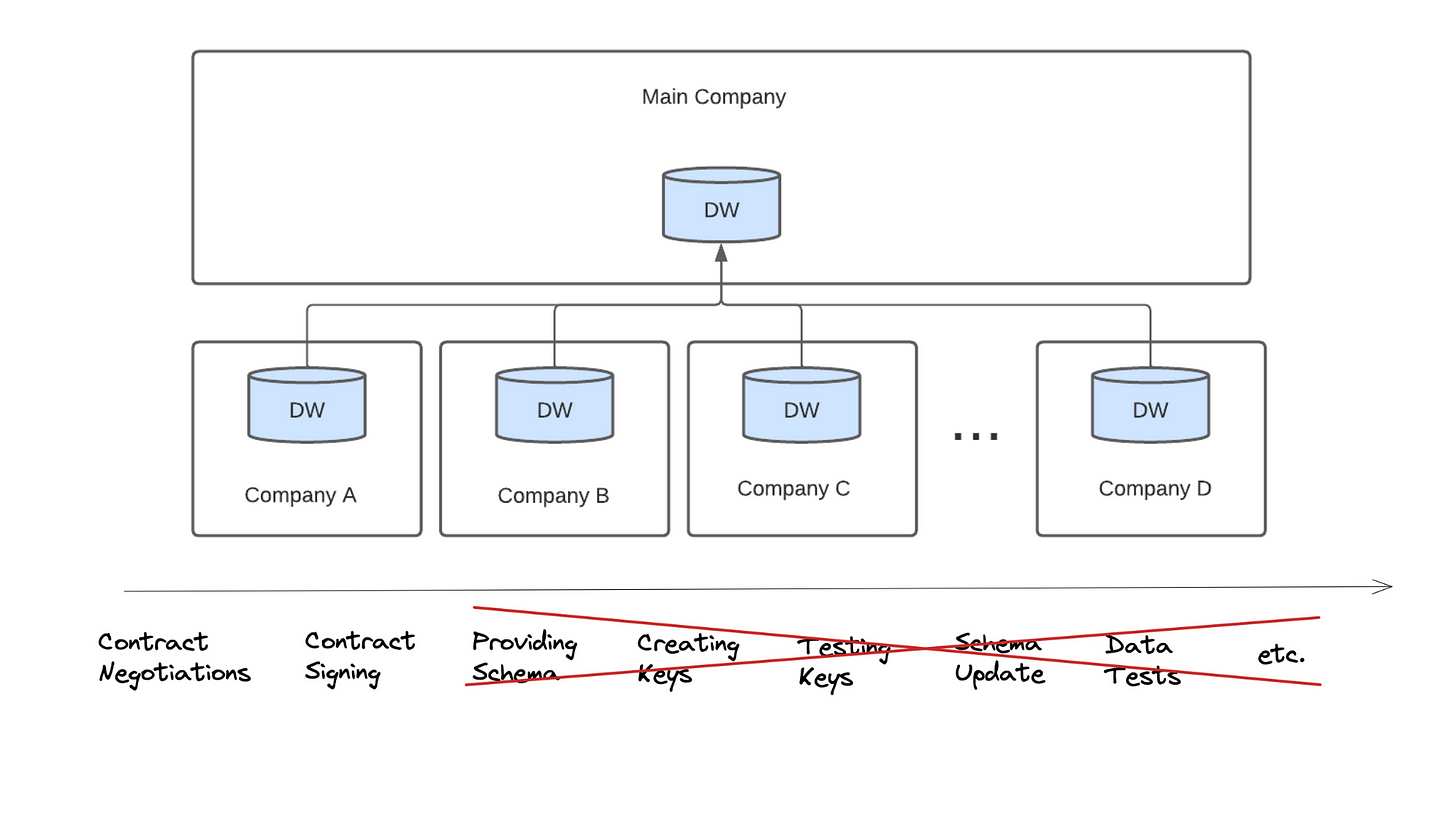
Companies like Snowflake and Databricks allow you to share data across their services. So if one company uses Snowflake, then they can share tables with you. In fact, this is already happening.
I have clients who have been selling data sets and analytics back to their customers this way. It keeps their engineering costs lower while providing new value they may have never had time to provide in the past.
I have other clients who are setting up their Snowflake instance as the central data warehouse where all of their portfolio companies and partners send them metrics and data that help create better synergies.
Data sharing can provide many benefits by simplifying the overall process of getting data from point A to point B (maybe we can finally eliminate data engineers).
Of course, this is far from perfect.
The Obvious Problem
One of the main issues with how Snowflake and other providers are sharing data is that generally they only allow you to share data that is on their platform.
That is to say, if you’re on Snowflake, you can only have other Snowflake accounts shared with you. This makes sense from multiple perspectives.
There is likely not a huge financial benefit and it could put a lot of risk on all companies involved with opening up their VPCs to external competitors.
With this problem comes solutions(There is start-up for every problem, no matter the TAM).
In fact, there are two different companies that I know of that are providing the ability to share data across various clouds and platforms. That would be Prequel.co and Bobseld.co.
Both of these solutions provide different ways for you to share data across your various platforms.
Looking at Bobseld's UI reminded me a lot of Uhaul from my Facebook days. We used Uhaul to share data across different namespaces since the “ads” namespace didn’t share tables with the “hr” or “infrastructure” namespaces.
We’d select the table, the namespace we wanted to move to, and how often it was supposed to be synced and then hit go.
And that’s how easy it should be.
No back and forth meetings (outside of what is required to set up the business agreements)
No need to set up an SFTP job
No need to wonder why the schema didn’t match what they sent you earlier
No need to set up a parsing script for all the possible file formats.
Instead, the tables are just synced on some cadence. This likely makes it easier for companies to do daily or multi-day pulls from external partners.
Many companies these days often only pull/push data to their external partners via a weekly or monthly cadence to avoid even more overhead.
But with either direct data sharing or using a solution like the ones listed above, companies can reduce their time-to-value, shrink sales cycles, and reduce the overall technical costs (amongst other technical benefits).
It’ll Never Go Down To Zero
It’ll be difficult to get rid of every SFTP job that exists, and maybe for some companies, it’ll never be practical, especially those who have hundreds of SFTP jobs already going. Migrating will likely never happen.
But I do foresee companies that will have to manage dozens or hundreds of these jobs in the future and will want to avoid the tedium that is creating SFTP jobs.
This isn’t about getting rid of data engineers. It’s not about getting rid of ETLs. It’s about removing the need to constantly move data around, making duplicates and causing unnecessary overhead.
At some point, this made sense. But with the cloud, many companies may be able to reconsider.
Thanks for reading!
Data Engineering Video You May Have Missed
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
5 Hidden Apache Spark Facts That Fewer People Talk About
Developing Apache Spark can sometimes be frustrating when you hit the hidden facts on it. Those facts that fewer people talk about should be addressed in online courses or books. Until one day, you found the unexpected result and dug into the Apache Spark source code.
I want to share 5 hidden facts about Apache Spark that I learned throughout my career. Those can be helpful to you to save you some time reading the Apache Spark source code.
Building Airbnb Categories with ML & Human in the Loop
Airbnb 2022 release introduced Categories, a browse focused product that allows the user to seek inspiration by browsing collections of homes revolving around a common theme, such as Lakefront, Countryside, Golf, Desert, National Parks, Surfing, etc. In Part I of our Categories Blog Series we covered the high level approach to creating Categories and showcasing them in the product. In this Part II we will describe the ML Categorization work in more detail.
Throughout the post we use the Lakefront category as a running example to showcase the ML-powered category development process. Similar process was applied for other categories, with category specific nuances. For example, some categories rely more on points of interests, while others more on structured listing signals, image data, etc.
End Of Day 77
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
🙌🙌🙌