


Walking Through Data Warehouse Design
Facts, Dimensions And Trying To Walk Through A Data Engineering Interview

Photo by CHUTTERSNAP on Unsplash
Data warehouses (in all their forms and iterations) have become the backbone of almost every organizations analytics, data science and BI departments.
Over the years they have evolved and taken on new shapes as modern infrastructure has been developed to better manage analytical queries and workloads.
In our last few articles and videos we discussed why data warehouses are used as well as a high level for what they are used for.
Now we wanted to provide more depth to a data warehouse.
Beyond just talking about the high level reasons why you might want to incorporate a data warehouse into your infrastructure. We wanted to discuss the key design components.
In the article below we will discuss some of the key design schemas as well as the main tables that make up these schemas. In addition, we have created a video of us walking through an example of designing a data warehouse star schema.
Star And Snowflake Diagram
There are lots of ways developers can approach developing and designing a data warehouse. However, arguably the most popular is to implement either a star or snowflake schema. These have been popularized because they are easy to understand both from a data engineer stand point as well as an analyst.
This is because it takes a very straightforward approach where there is a central table that represents key business workflows. This is compared to application databases that are normalized and often have very complex structures.
Let’s look at the example below where we see an accounting data warehouse where the core table is based on the actual entries in the general ledger. We will call that central table f_actuals.
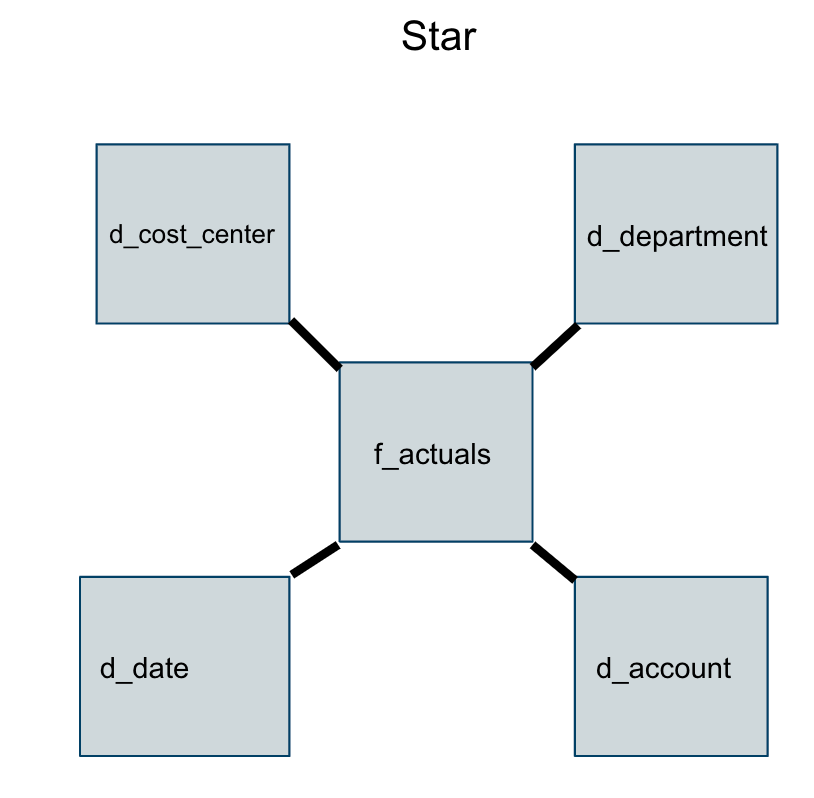
This means that the actual thing we are measuring is the account entries in the general ledger. Whereas what we call dimension tables that are external to that central business process.
Like dates, accounts, department, cost center and pillar (these could be in one table depending on how your company is organized). These are just a few examples of dimension tables that could be involved in an accounting data warehouse.
A Snowflake schema data warehouse is not that different. The main difference is that the dimension tables will often be more normalized. This means we will likely further breakout dimension data. For example, hierarchical data might need to be normalized into multiple tables to remove duplicate data. It will start to take the shape of a snowflake with more and more dimension tables branching off.
Like the example below.
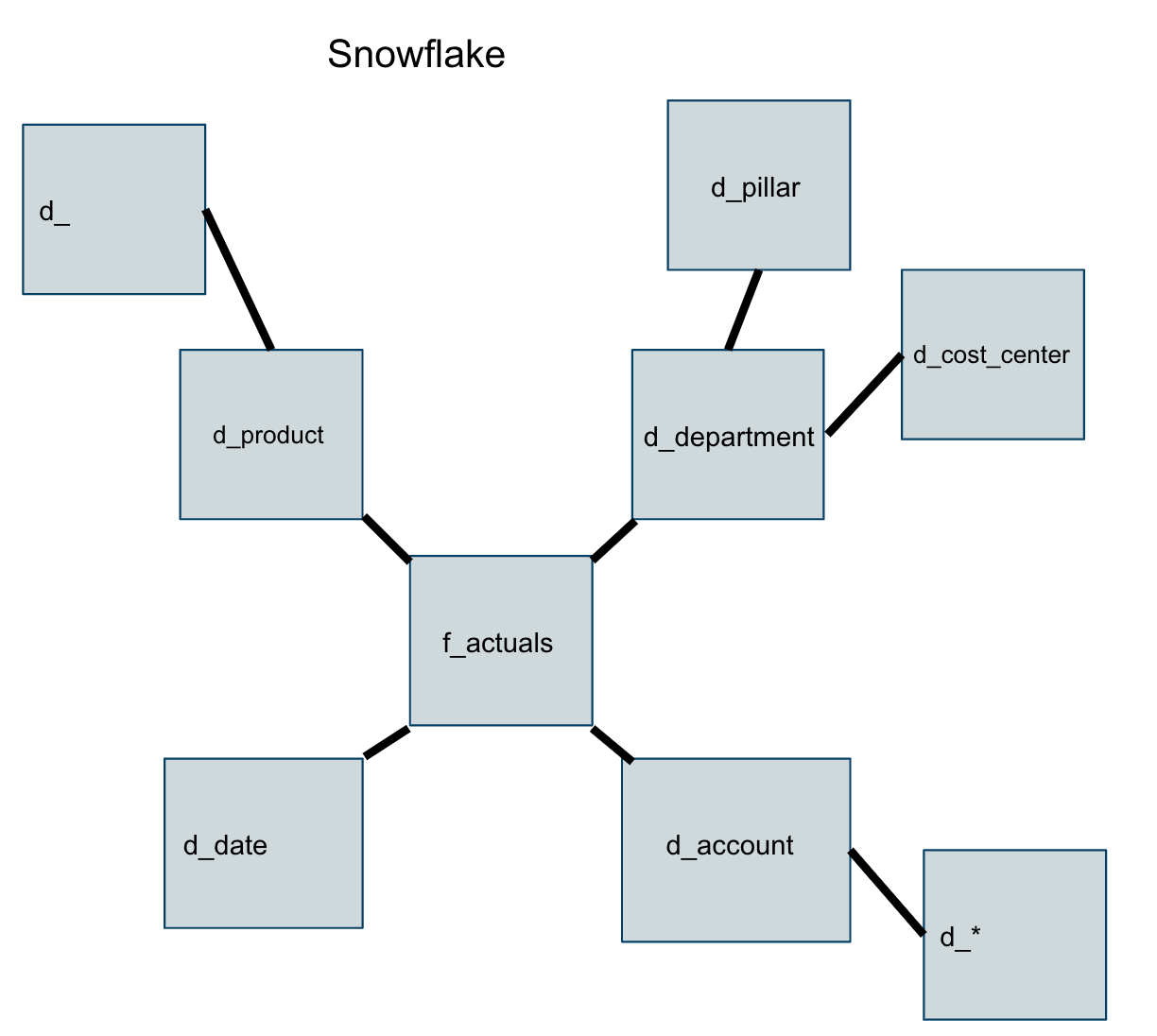
Overall, you can see that these designs, compared to typical normalized databases, is actually quite simple. The focus on a central fact table with dimension tables around it makes it easy for analyst to use.
But what do these tables mean?
Tables
When building a data warehouse, specifically using the star schema design, there are two core tables you will utilize and a handful of less common but still useful tables that often act more as an analytical layer of data.
Dimension Tables
Dimension tables contain data that help provide context to the core fact table. For example, if your director asks for a report that provides a quarterly breakdown of sales by department, then the dimensions would be time and department. In this case time is broken down into quarters.
Dimension tables contain descriptive data that encircle a fact. So we can look at the example above where we had a star schema where the dimensions were all focused around the actuals table.
If we look at the department table, it would probably be made up of at least a department key, department name, pillar name and a few other common fields that help deeper describe the dimension of department.
This is shown in the table below.

Another way you can think about dimensions is that dimensions are usually the fields you end up using to pivot your data in Excel or Tableau.
Fact Tables
Fact tables generally contain information that is transnational. Data like sales, costs and quantity of a product sold or moved. In turn these tables often contain millions/billions of rows as each transaction represents a new row.
These tables are the core of what you will be reporting on and often what a data analysts or BI Developer will use for their metrics. Data is generally just appended to the end of this table and contains a time stamp to denote when the event occurred.

These are the main two tables that exist in a data warehouse. Now there are some other slight variations on these tables.
For example, some teams might find it useful to create a snapshot or summary fact table. An example of a summary table would be a table that aggregates the accounting actuals on a monthly and account based granularity.
This could look like the table below.

As you can see the values are already summarized by department, month and year. This can be used to improve report speed.
Walking Through Data Warehouse Design
So we have all these examples of tables and what the general design of a data warehouse is.
Let’s take it for a spin.
A common interview question for data engineers and BI developers is to develop a data warehouse. Personally, I have been asked to design a parking lot data warehouse, a college courses data warehouse and several others for interviews.
I suggest that most people watch a few videos on the topic of data modeling as well as read up on Kimball’s data warehouse design book. After that, then you should think about a few workflows you might enjoy and practice modeling them.
For example, let’s walk through designing a data warehouse for a food delivery app.
How would you approach this design?
Generally, a good way to start is to list out the entities you would consider being part of a food delivery app.
For example here is a list:
Menu Items(And possibly add-ons)
Restaurants
Drop Off Locations
Cars
Persons(Customers and drivers, since a driver in the future might be a customer and visa versa)
Orders
This would be a good high level set of entities to start with. Especially in an interview. You don’t want to focus on every possible issue and detail.
I would list these out and prod the interviewer to see if this is all the entities they were concerned with. Often times interviewers have a specific set of questions they want to ask. So if you don’t include all the entities, they may ask about different parts of the workflow you might have forgotten.
From here, the dimensions it may be obvious. You have menu items, restaurants, drop off locations, cars and persons.
These are all dimensional items because they represent entities that don’t change often, don’t contain measurable data and can be used to pivot and break down your future reports.
There are a few possible gotchas. We will talk through a few of them below.
For example, let’s say you propose the model below.

This might be where you mind first takes you when you model your data warehouse.
There is a problem with this model. Let’s say we want to figure out the average number of menu items sold per restaurant.
With this model, you would not be able to capture all the menu items per restaurant.
Since the only way you can tell which restaurant has which menu item is through the order table. Meaning if a menu item wasn’t ordered, you won’t know what restaurant it belongs to.
You can see this in the data example below.
In this case it might make more sense to have restaurants be attached to menu items. This way you can always tell which menu items belong to what restaurant.
Like in the example below.

Now this will cover the very basic level of what menu items belong to which restaurant.
There are still a couple other points that might be worth discussing. For example, think about add-ons.
You will probably want to be able to answer questions like, “What menu items make the most from add-ons” like guacamole and chips.
Currently, there is nothing in the model to manage this. Now, this would be a point I would avoid if you’re in an interview unless the interviewer brings it up. Dealing with nested facts like add-ons can be tricky and that’s why I would avoid it.
This could take a few different data modeling routes and honestly we can foresee a lot of debate on this point.
So we will leave that up to you.
Data modeling can be very tricky and there are a lots of gotchas. So even here, you may be trading off some negatives for creating a secondary add ons fact table that connects to the main order tables. This is advised against by Kimball. However, this doesn’t mean you shouldn’t do it.
What are your thoughts?
Data Warehouse Designs And Where Are They Going
Star-schema data warehouses are still very popular. They are very simplistic in terms of conceptualizing the central fact design. Making the data warehouse is an easy solution to implement when you need to create a central data storage system for analysts to use that is intuitive.
Now, there are a lot of changes to data warehousing due to improvements and design changes in modern cloud data warehouses. Everything from Redshift, Snowflake and Hive have changed how we design data warehouses. Although many of these designs are based on the traditional data warehouses, there are a lot improvements you can take advantage of.
Read More About Data Science And Data Engineering Below
4 SQL Tips For Data Scientists
How To Analyze Data Without Complicated ETLs For Data Scientists
What Is A Data Warehouse And Why Use It
I always assumed that the star schema would be the only way and didn’t think of 2 dim tables connected to each other . Thank you