
Translating Data Buzzwords Into Real Requirements
Bridging the Communication Gap Between Data and the Business
One of the challenges many data teams and leaders face is helping the business understand what they are asking for.
It might be that a business executive just came from a conference or read an article and now they are suddenly requesting your team to build an AI-powered, virtual 3-D pie chart that allows for self-service, dynamic drill-downs “like that demo they saw on stage.”
Or maybe someone from finance forwards you a Gartner report and asks why you still don’t have a Data Mesh, a Lakehouse, and whatever the latest marketing term is this month.
None of this is malicious...ok, perhaps a little from the marketing and sales from vendors…
It’s a symptom of a bigger problem:
Most of the vocabulary we use in data has escaped into the business without the underlying meaning.
People hear terms, “real-time,” “semantic layer,” “self-service,” “data quality”, and either don’t clarify their understanding or are waiting for someone else to properly define them.
This gap creates:
Mismatched expectations
Projects that sound good but don’t solve real problems
And a lot of unnecessary fire drills
So in this article, I want to break down a handful of terms that data teams constantly find themselves explaining, not because the business isn’t smart, but because these concepts are overloaded, over-marketed, and often misused.
Batch And Real-Time - What Do You Really Need?
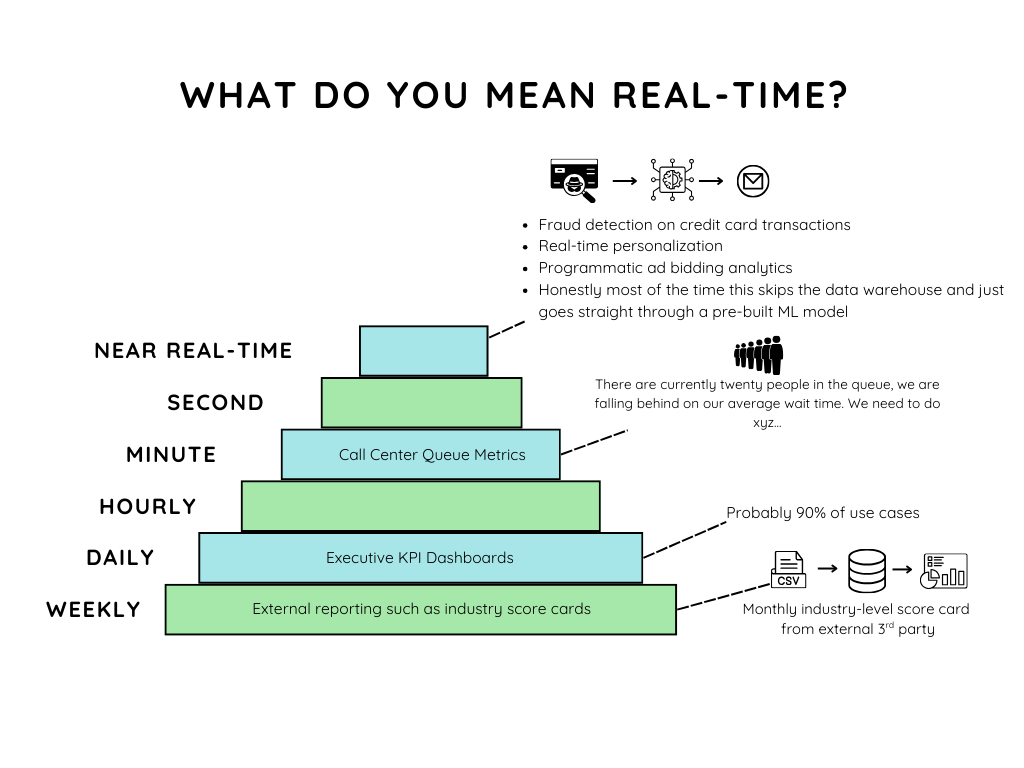
It’s perhaps not shocking how often I get asked to build real-time data products and pipelines. It’s almost the first request from many business teams’ mouths.
“We want this data to be real-time.”
I recall one call with a prospect where I kept re-asking about the real-time requirement in different ways.
“You said you need the data in real-time, what does that mean to you?” - This question is pretty broad, but it starts the conversation.
From there, you can start asking:
“So, for this dashboard, how often do you want to look at it?”
“Is there a specific use case for this dashboard?”
“What decision will change if this data shows up in 5 seconds instead of 5 minutes?”
You can’t always ask, What do you mean by real-time or Do you really need it because the answer will be yes.
You often have to ask questions about the topic. And eventually it’ll become clear.
(Here are a few more questions you can ask)
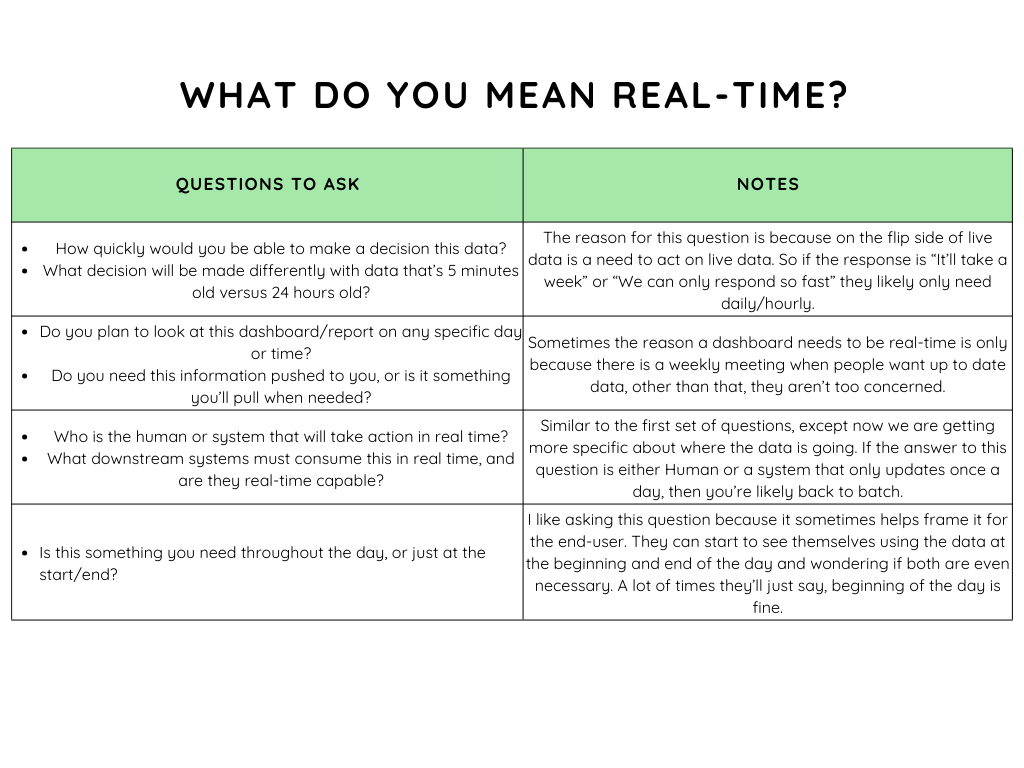
Actually one quote I really liked to explain why there can sometimes be confusion was:
“Real-time is exactly when the executive needs the dashboard for their weekly meeting”
Meaning, if they need it for a monthly meeting at 8 AM on the 2nd every month, they want it real time, then and often only then.
Other times, all it means is updated daily. But you need to be able to have them realize that.
Data Quality And Clean Data
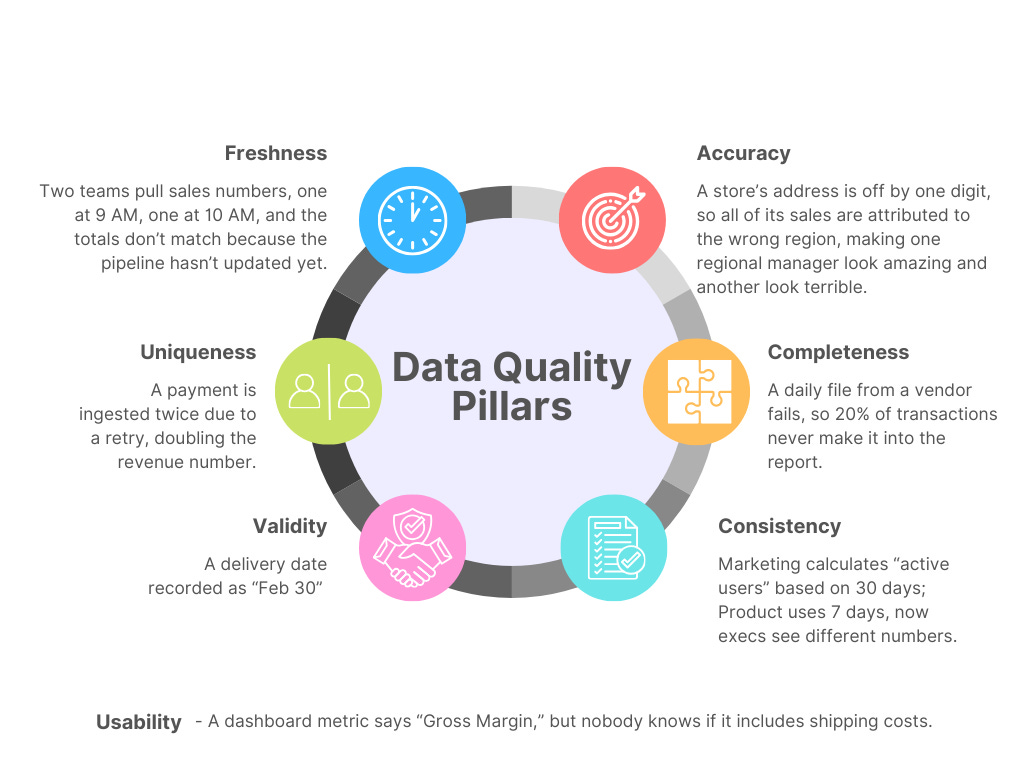
One of the big challenges I see with the term data quality is that when we say “data quality” to the business, they only think that means the data is right or wrong in terms of how accurate it is.
But if you’ve ever been in a meeting where two different teams bring metrics, but one was pulled an hour before the other, so they are no longer matching, you know there are a lot of ways data can be wrong.
I will say that we, the data team, don’t always help either.
When someone from the data team says something like, “Our data is bad,” they then say GIGO(garbage in, garbage out). That is not helpful.
Be clear on why the data is bad and what your plan is to fix it.
The image below denotes the different pillars of data quality.
Data Modeling vs. Medallion Architecture
Another common source of confusion I see is when the business hears “Medallion Architecture” and assumes it’s just another word for “data modeling.”
I’ve had multiple conversations where the term medallion architecture is used as the end-state data model itself. Add to that that dbt also references their SELECT statement scripts as models, and a lot of this can get really confusing.
If you really want to get even further confused you can consider dbts layers dbt like “staging,” “intermediate,” and “mart”, which map loosely to Bronze, Silver, and Gold.
When you’re new to the data world or just on the business side, I think it’s fair to get confused on all this talk of layers, models, lakehouses, and warehouses.

The reason confusing these two actually impacts data teams is that it’s easy to skip over the actual data modeling and go straight into building your data layers(medallion architecture).
Just pull in the raw data, process it a bit, use the terms Dim and Fact, and boom, you have your “data model,” right? Except that you never actually went through the trouble of data modeling, you’ve only built a set of data pipelines.
Medallion architecture is a process your data goes through, from raw to cleaned and refined to business-ready.
It’s a pattern.
Using it does generally get your data into said data model. But it in itself is not the process that decided what the data model should look like.
A data model “organizes and standardizes data in a precise, structured representation, enabling and guiding human and machine behavior, informing decision-making, and facilitating actions.” - Medallion Architecture is NOT a Data Model by
I see where the confusion comes up. Again, dbt models, the naming of tables with dim and fact. It all feels like data modeling.
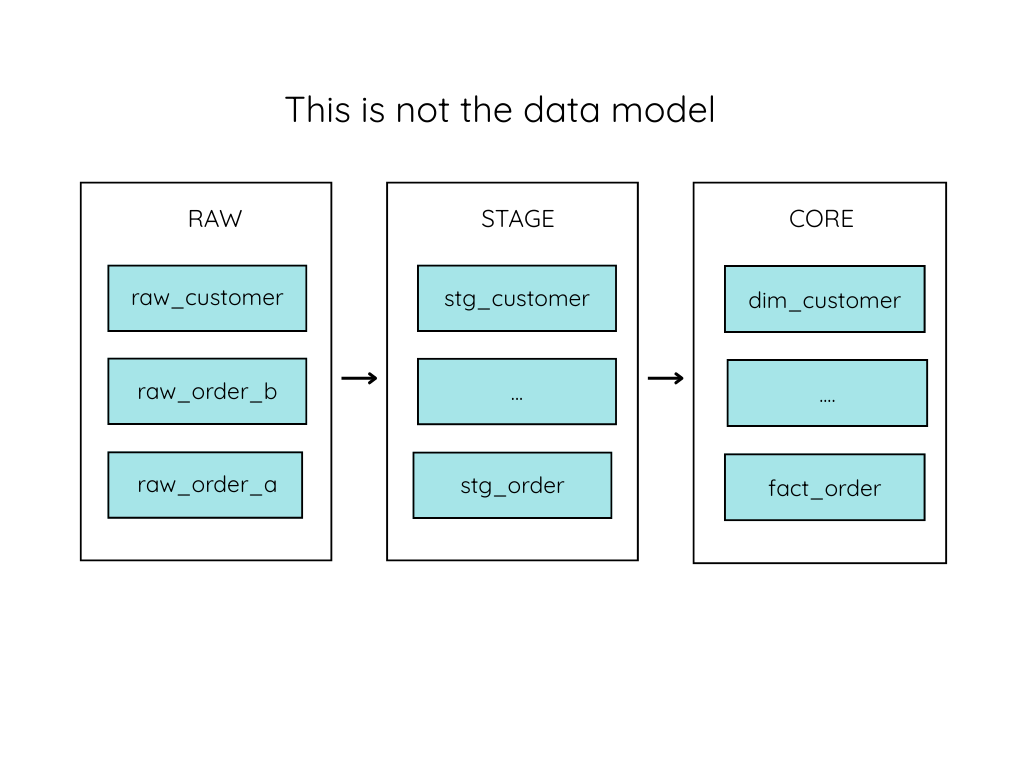
Without ever going through the process of considering what you are building and how you are organizing it.
Final Thoughts
The more you can understand what the business is asking and how to communicate back, the better you can align and build what is needed.
Don’t even get me started on LLMs and AI, that’s a whole series in itself.
I hope the pictures help you explain it to the business, and if not, let me know and I’ll take another crack at it!
Thanks as always for reading!
Events
Articles Worth Reading
There are thousands of new articles posted daily all over the web! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Review of Data Orchestration Landscape
By
Sometimes, I force my old caveman self to do things I do not want. Believe it or not, reviewing the landscape as it relates to data orchestration frameworks is not something on the top of my list. People, including me, have their own pet favorites when it comes to orchestration platforms, and it’s hard to be unbiased.
Does it matter what tool you choose? If it works, it works; if it doesn’t, it doesn’t; it’s not like we don’t have a plethora to choose from.
Either way, I suppose something like this could be helpful for those new to the Data Engineering world or those looking to build greenfield projects or migrations.
Data Engineering 100-Day Crash Course
It can be challenging to break into data engineering directly. There seems to be a need to learn a whole plethora of skills that range from programming to data modeling. Perhaps that’s why I often see a lot of individuals moving laterally into data engineering; many people go from data analyst to data engineer.
Both roles likely have exposure to the data warehouse and work with some similar tools including SQL and perhaps some Python or scripting, making the transition easier. Regardless of your background, I wanted to help those who are looking to switch from a data analyst role or non-technical role to data engineering.
To do so I created a 100-day plan that you can use to get up to speed quickly on what data engineering generally covers. But before diving into that, let’s talk about some of the limitations.
End Of Day 204
Thanks for checking out our community. We put out 4-5 Newsletters a month discussing data, tech, and start-ups.
If you enjoyed it, consider liking, sharing and helping this newsletter grow.
Several solid points! Just shared on my LinkedIn!
Good read!