


The Evolution Of Data Companies
In evolutionary biology, convergent evolution is defined as the process whereby distantly related organisms independently evolve similar traits to adapt to similar necessities.
In comparison, divergent evolution represents the evolutionary pattern in which species sharing a common ancestry become more distinct due to differential selection pressure which gradually leads to speciation over an evolutionary period.
But this is not limited to animals fighting for limited resources in their ecosystems.
Companies and products are driven by similar forces to survive and thrive.
Similar pressures that act on biological beings and force them to adapt, similarly act on companies and force them to change or die.
There are limited resources in terms of talent and money. As well as market trends and changes in customer needs that can cause a once successful survival strategy to push a company to extinction.
This in turn drives companies to commit to decisions on where they will and won’t focus that could either lead them to success or non-existence.
Divergent Evolution - One Pain Point Three Companies
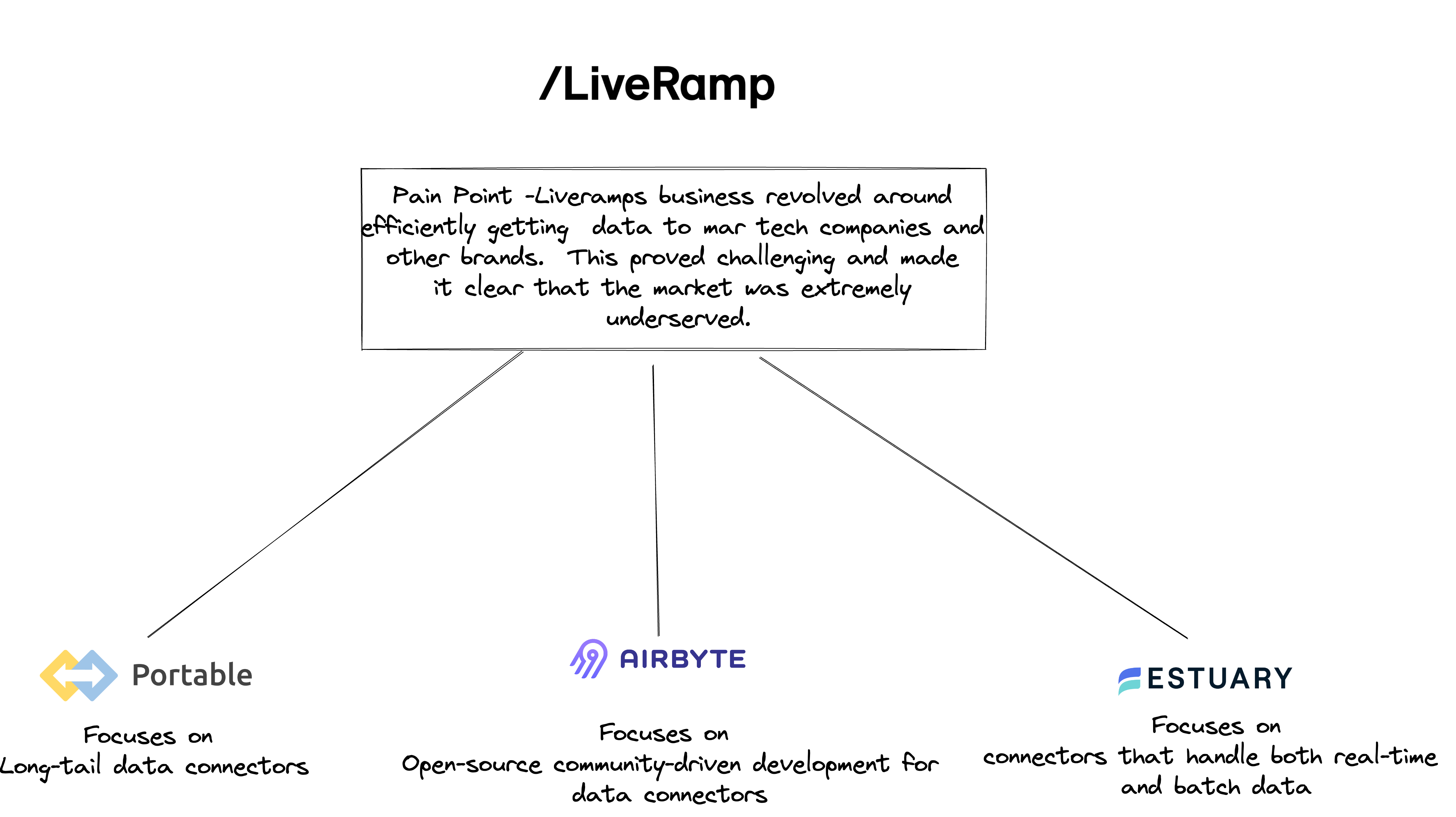
The same pain point can drive different responses from different individuals. Data connectors are not a new category in the data space. Precog, Fivetran, and Matillion(of course they are more than a data connector) are just three of many examples of companies whose focus has mainly been EL.
However, three separate data connector companies were all co-founded by ex-LiveRamp employees.
Airbyte, Portable, and Estuary are all data companies whose founders must have felt the pain of pulling data from different data sources. Here is a list of the founders that were all Ex-Liveramp.
Ethan Aaron and Azim Sonawalla - Portable
Michel Tricot - Airbyte
David Yaffe - Estuary
Add to this the fact that Airbyte’s staff is currently made up of about 20 (out of around 100) or so ex-LiveRamp employees and this is more than just a coincidence.
The question becomes why? What about working at LiveRamp exposed each of these individuals to a similar set of pain points?
As explained by David Yaffe of Estuary, he believes one of the driving factors was that:
LiveRamps business revolved around efficiently getting data to MarTech companies and other brands. Doing so was a perpetual problem due to a variety of issues which made it clear that the market was extremely underserved
Despite feeling similar pain points each of these companies have taken on a different strategy on how to approach this very crowded market.
Portable - Focuses on long tail connectors. This helps them avoid directly competing with larger companies that support mainstream connectors as their main competitive advantage. It also allows Portable the ability to complement some of these larger solutions with their one-off connectors.
Airbyte - Focuses on an open source and community driven development strategy.
Their belief is that their community approach will allow them to provide:
A wider array of data integration connectors. If an integration is missing, it is simpler to add it for an engineer than to build it on the side. Plus, you don’t need to wait for someone else's engineering team to prioritize it. - Airbyte Differentiation
Estuary - Focuses on streaming data connectors. Their differentiation is that they allow their end-users to leverage hundreds of connectors that handle both real-time and batch data, ensuring that all your integrations are optimized for speed, cost, and efficiency.
Each of these approaches to data connectors are unique and could allow for all three of these companies to rarely bump into each other in terms of competition. In fact, in some cases they may work well together.
Yet, at some point, if any of them want to grow bigger in the future they will likely need to converge on each others territory.
Convergent Evolution - Two Companies One New Market
As some companies push away from each other and find their niches, others are starting to push into each other’s territory. The most notable case of this is probably Snowflake vs Databricks.
Two companies started from different sides of the data spectrum.
Databricks has its roots in academy and data science whereas Snowflake was developed by ex-data management professionals. These foundations are apparent in the products, their focus, and their UI.
But now they are starting to look at each other like the apex predators in a vast plain and they’re starting to wonder if they will need to start to take market share from each other(the joke being that both are just reselling AWS, GCP, and Azure).
With this comes a need for new features and a new end goal. Neither product wants to just be your data store any more. They want to be your data OS your data platform. The layer companies rely on to build any form of data application.
The same goal means a similar set of features needs to exist in both solutions. Of course, each will need to build based on its original foundation and principles which continue to constrain and alter the approaches both companies are forced to take.
In addition, in many of the points made above, I have spoken as if the market is mostly a vacuum where no new competitors or old incumbents ever attempt to gain a greater share of the pie.
External Forces - Market Factors And Other Competitors
Like any ecosystem. Databricks, Snowflake, Portable, Airbyte, and Estuary aren’t alone. Many other competitors are enacting different strategies for survival. Many other solutions are attempting to either grow or grab market share.
As pointed out by CEO of dbt, BigQuery is also gaining steam based on their data.


Add in the rising popularity of DuckDB as well as market incumbents like Teradata continuing to push into the cloud space.
And the sprinkling of market zeitgeist that perhaps Snowflake is getting too expensive (whether that is reality or not isn’t as important as perception).
No company can truly focus on one competitor or one problem. The market isn’t that forgiving.
Nor can they lose sight of other market forces and trends such as rising interest rates and tighter budgets which are putting pressure on the entire ecosystem that we know as the market. Even large institutions in the tech space are signaling that these external factors may impact them as well.
Overall these companies have made decisions based on what challenges they foresee in the future.
We will see if they made the right ones in the next few years.
Dashboards are everywhere: how to fix it

Visit workstream.io for a free account. Add dashboards or reports from almost any tool to our central repository. Surface critical information and training on top of live data assets. See how data is used and impacts business decisions. Celebrate the beginning of data democratization.
Rein in the dashboard sprawl with Workstream.io, and you get to:
✔️ Sharpen your storytelling skills with decision-makers
✔️ Stay abreast of who is using what data, and how often
✔️ Build trust and facilitate meaningful change in your company
Thanks to Workstream.io for sponsoring this Newsletter!
Video Of The Week: Why Data Engineers LOVE/HATE Airflow
Join My Data Engineering And Data Science Discord
Recently my Youtube channel went from 1.8k to 40k and my email newsletter has grown from 2k to well over 18k.
Hopefully we can see even more growth this year. But, until then, I have finally put together a discord server. Currently, this is mostly a soft opening.
I want to see what people end up using this server for. Based on how it is used will in turn play a role in what channels, categories and support are created in the future.
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
The Difference Between Micro-Partitioning vs. Indexing and a Better Way
When optimizing your analytics database performance, one of the most important decisions is to choose how data is stored and accessed. There are two approaches that are optimized for efficient, high performance analytics: micro-partitioning and indexing.
Micro-partitioning uses the values of a predefined (small) subset of columns to divide a table into blocks of tens to hundreds of megabytes in size each.
In contrast, indexing expands beyond this predefined subset and separates out how data is stored (typically in similar blocks to the micro-partition architecture) with how selected column values are accessed, allowing users to optimize access to any subset of columns.
The system that you choose has a significant impact on cost and performance.
Online Data Migration from HBase to TiDB with Zero Downtime
At Pinterest, HBase is one of the most critical storage backends, powering many online storage services like Zen (graph database), UMS (wide column datastore), and Ixia (near real time secondary indexing service). The HBase Ecosystem, though having various advantages like strong consistency at row level in high volume requests, flexible schema, low latency access to data, Hadoop integration, etc. cannot serve the needs of our clients for the next 3–5 years. This is due to high operational cost, excessive complexity, and missing functionalities like secondary indexes, support for transactions, etc.
After evaluating 10+ different storage backends and benchmarking three shortlisted backends with shadow traffic (asynchronously copying production traffic to non production environment) and in-depth performance evaluation, we have decided to use TiDB as the final candidate for Unified Storage Service.
End Of Day 52
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
If you want to learn more, then sign up today. Feel free to sign up for no cost to keep getting these newsletters.