
State Of Data Engineering Part 2.5
What Drives Vendor Selection
In the past few articles titled the “State Of Data Engineering”, I analyzed the survey data collected in the last few months of 2022. I had over 400 respondents fill out the survey from companies that ranged from 2-5 people to 25000+.
We actually had a good spread overall in terms of company size, industry, and region. You can read about the breakdown here.
Now one chart in particular from the previous article on the topic brought out several discussions.
That’s this one.

dbt was the most referenced ELT/ETL tool, which in itself had some people ready to fight because we all know dbt is just the T.
Which, perhaps as brought up by
, maybe just putting the umbrella term data workflows as the term would have been less controversial.
But that was only one of several discussions.
Another issue that also was around dbt was the fact that it was so frequently referenced. Of course, I did later go over that the usage of dbt seemed to be heavily weighted in companies that ranged from 50-1000 employees, whereas tools such as Informatica, Qlik, and Azure Data Factory were more heavily utilized at the enterprise level.
Perhaps I could have shown charts like the two below that might have appeased a few people as it would have more clearly shown the trends in terms of size of company to tool selected.
For example this first chart below shows that much of the usage of dbt is centered around the 50-5000 employee sized companies.

Whereas when looking at Azure Data Factory and Informatica, we will find that these tended to lean more heavily towards larger organizations.

Overall, this did make me want to take a step back to talk about weights, biases and trends and how they impact what tools we select.
So in this article, I will continue to analyze the data we collected, but I also wanted to point out some of the more nuanced points.
Weight - What Does A Respondent Represent?
A weight in statistical terms is defined as a coefficient assigned to a number in a computation, for example when determining an average, to make the number's effect on the computation reflect its importance. - Source
If you’ve built a basic model, you may have used manual or computer-generated weights to determine the importance of each feature.
But another way to consider weights is how much a certain entity represents. This is why we often say you shouldn’t average averages because you risk having a strange weighting where one entity that averaged fewer values has an equal representation compared to another.
I had some similar thoughts on the concept of what a respondent represents.
In theory, at the lowest level, each representative represents a team, and at the highest level could be the entire company (I say this because some companies allow each team to pick its own data stack).
Assuming it’s likely a mix, each respondent could likely represent 3-100 people. When you consider the size of the company, each respondent really means a lot more than just one person.
Many employees at companies far larger than that relied on solutions like Qlik, Azure Data Factory, and Informatica.
This makes me think about that question, "What would you pick to plow a field, 100 chickens or 1 horse?" If a single 25,000-person company uses Azure Data Factory versus 20 companies of 500 employees using dbt, which is more impactful?
Ultimately, how companies select products isn’t always about the best product but several other key data points.
What Drives Tool Selection Anyway?
One of the patterns I continue to see is that the tools selected by companies tend to be influenced by several factors.
This includes:
Company Size/Budget
Region
Marketing
Trends
Relationships(consultants, account executives, etc)
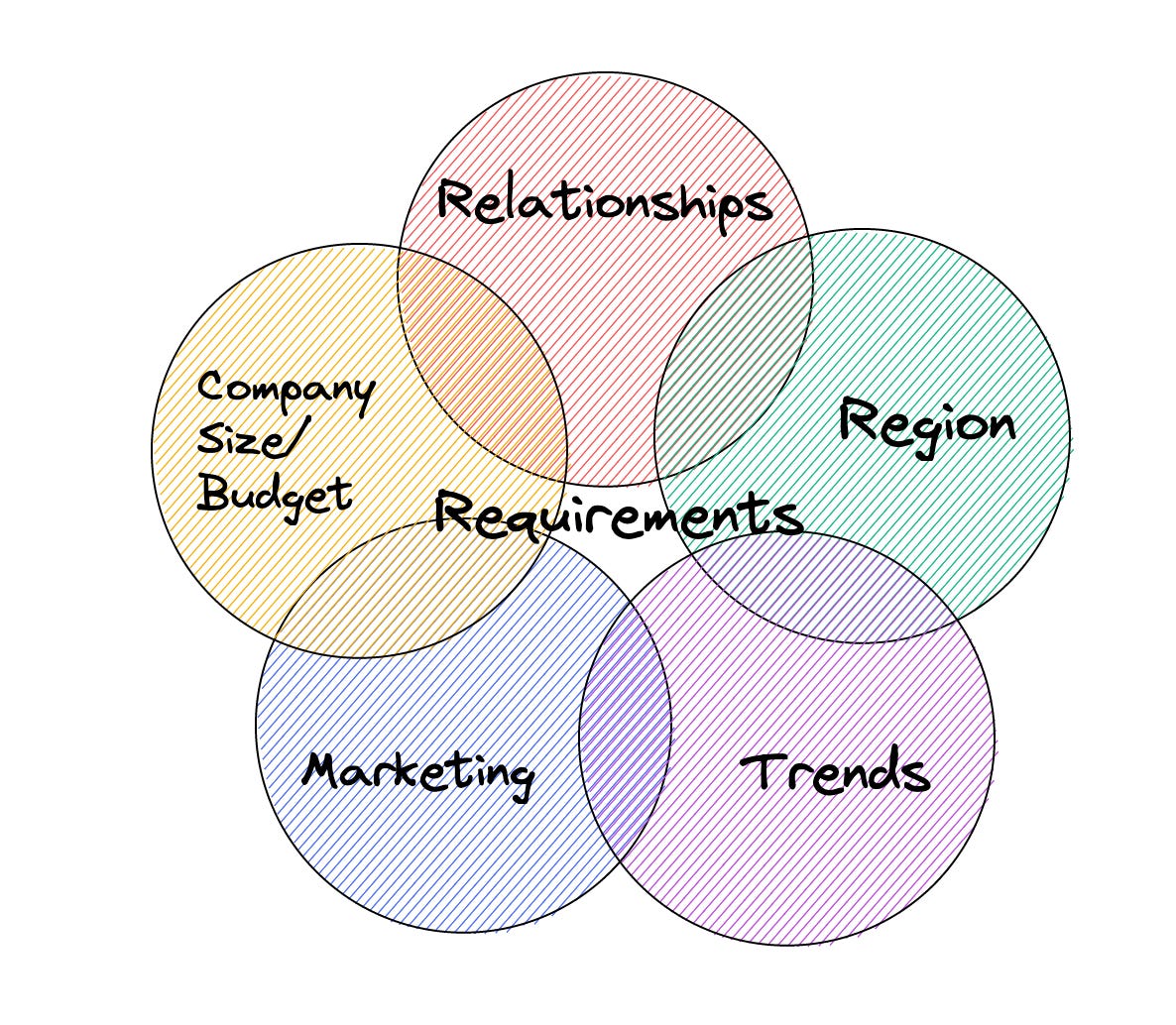
The tools many companies select aren’t always chosen based on what is “best” in terms of engineering or product. Instead, it may be that a director is friends with a VP at one vendor, or maybe Gartner has released a new list of “Cool Vendors.” Finally, just the very region in which a company is located can heavily impact the tools they use.
One great example I come across constantly is if I am working with a decently large Mid-market or Enterprise with an HQ in Europe, they, at least from an anecdotal stand-point, likely have an SAP component somewhere in their eco-system.
Whereas in the US, many of these same companies were on some Oracle or Microsoft product.
And the data world is no different. If we dig into various enterprises, you’d likely find that there was some common thread.
Perhaps the same consulting company setup their data stack, or the account executive happens to live down the street from a CFO.
Going one level even deeper than that. Perhaps the consulting company or CEO is somehow financially invested in the product selected. Once you’ve spent a few years in the data world, you realize most other data practitioners are pretty heavily ingrained.
Or as Benn Stancil once put it.
there’s another, less visible network of elite entanglements that crisscross the industry: shared investors. - Disclose your angel investments
So when it comes to tool selection, many other factors come into play once the baseline functionality is met.
Sometimes not even that is met. I have seen companies constantly play around with various tools and never make any progress. Instead, they spend tens, if not hundreds, of thousands of dollars on people just playing around.
Trends - What Drove That Trend Anyway?
Like many other tech-centric industries, the data world runs on trends.
This has its pros and cons. As discussed in my article on Resume Driven Development, yes, RDD can cause companies to be slowed or sometimes just at a complete standstill because they constantly have to rebuild their data infrastructure.
But trends can also help push innovation and change in the tech world for better or worse. Perhaps a specific paradigm takes over the mind share, and suddenly everyone wants to try Hadoop. For some it works, for others, it doesn’t; but it also drove the development of many other solutions such as Trino and Hive.
So although it can feel as if trends can push things in the wrong direction, I believe there is a pushback to the mean, so to speak. If a solution or paradigm proves too difficult to implement, eventually, due to cost restraints or poor delivery, another solution will come and take its place.
In the end, we can hate on trends, but they really are just part of the tech world (honestly, like many other professions).
Seriously though, if I see one more barn door in a house where it doesn’t make sense I am going to lose it.
So Why Did You Really Pick That Tool?
There are a lot of reasons why the data world looks like it currently does today. Some of it was driven by marketing, and some were just the natural needs that data engineering and data science teams found they had.
Even with dbt, one reason it was adopted was likely because it filled the need of providing a parameterized SQL template that integrated with some form of version control…and probably some of it was also great marketing on their point. Does this mean you always need to use dbt.
No.
In fact, in some cases Snowflake Tasks or a similar solution might be good enough depending on what phase your company is in on their data journey.
I do hope we keep having discussions about where the data world should go in the next few years, even if most of our opinions will likely be incorrect.
Make your data actually useful. (It isn’t always).
Data teams are sick of people not using data. They hate answering the same annoying questions. That’s because data is only valuable when people in your organization actually know how to use it.
Set up a free account at workstream.io to consolidate your data knowledge, assets, and workflows in our analytics hub.

✔️ Socialize documentation, training videos, and upstream data quality to end users.
✔️ Allow users to discover critical dashboards, reports, and self-service assets in a single place.
✔️ Kill your service desk by streamlining business-facing questions and workflows.
Data Events You’re Not Going To Want To Miss!

Data Pipeline Automation Labs+ Happy Hour by Ascend.io in Chicago, Columbus, NYC, Seattle, & London.
Portable's Low-Key Data Conference
What Is It Like To Be A DE At Netflix, Target And Confluent with Xinran Waibel
Join My Data Engineering And Data Science Discord
Recently my Youtube channel went from 1.8k to 55k and my email newsletter has grown from 2k to well over 36k.
Hopefully we can see even more growth this year. But, until then, I have finally put together a discord server.
I want to see what people end up using this server for. Based on how it is used will in turn play a role in what channels, categories and support are created in the future.
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
What should you use ChatGPT for?
I work in machine learning and read about it a lot, but ChatGPT still feels like it came out of nowhere.
So I’ve been trying to understand the hype. I’m interested in what its impact is on the ML systems I’ll be building over the next ten years. And, as a writer and Extremely Online Person, I’m thinking about how it could change how I create and navigate content online.
From the outset, it’s clear that both ChatGPT and other generative AI tools like Copilot and Stable Diffusion are already having short-term impact. First, generative AI is already being used to spam reams of trash fictional content into magazine submissions systems. and artist platforms are reacting in turn.
Code Mysteries: Because Who Does not Love a Good Puzzle?
When starting a new puzzle, how do you know what the puzzle will look like when it's completed? You look at the box, right? Well, in code, that's exactly what documentation is. Documentation provides an understanding of the pieces and the bigger picture. However, we often forget its importance.
Consider this: if you are the engineer on-call and need to figure out what went wrong with a program, or if you are a data engineer trying to decipher someone else's code after they've left the company, or if you simply want to remember what you did a few months down the road, good documentation is essential.
End Of Day 74
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
I'm surprised Snowflake and Databricks aren't on here for ETL
Really interesting!