
How To Start Your Next Data Engineering Project
Many programmers who are just starting out struggle with starting new data engineering projects. In our recent poll on YouTube, most viewers admitted that they have the most difficulty with even starting a data engineering project. The most common reasons noted in the poll were:
Finding the right data sets for my project
Which tools should you use?
What do I do with the data once I have it?
Let’s talk about each of these points, starting with the array of tools you have at your disposal.
Picking the Right Tools and Skills
For the first part of this project I am going to borrow from Thu Vu’s advice for starting a data analytics project.
Why not look at a data engineering job description on a head-hunting site and figure out what tools people are asking for? Nothing could be easier. We pulled up a job description from Smart Sheets Data Engineering. It is easy to see the exact tools and skills they are looking for and match them to the skills you can offer.
Below are several key tools that you will want to include.
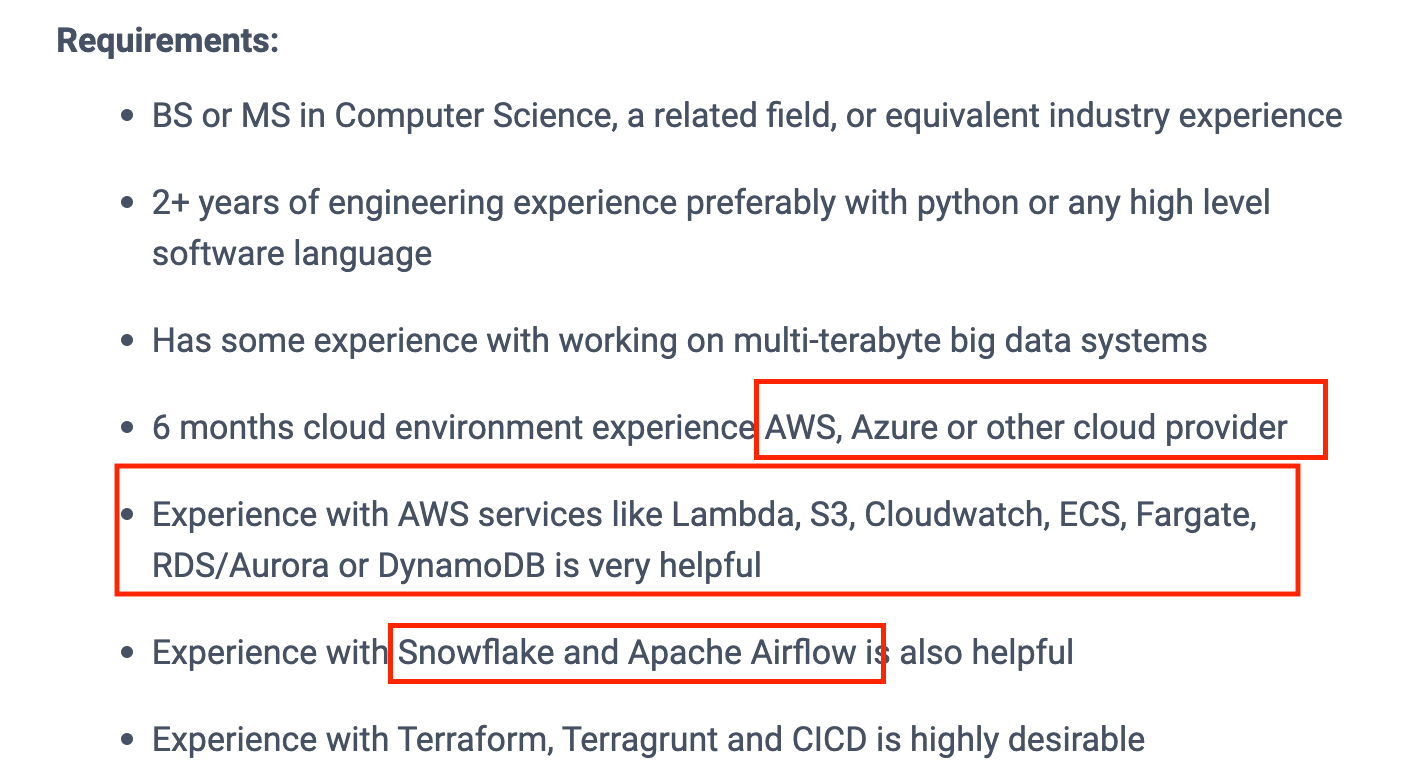
Cloud Platforms
One of the first things you’ll need for your data engineering project a cloud platform like Amazon Web Services (AWS). We always recommend that beginning programmers learn cloud platforms early. A lot of a data engineer’s work is not completed on-premise(anymore). We do almost all work in the cloud.
So, pick a platform you prefer: Google Cloud Platform (GCP), AWS, or Microsoft Azure. It’s not that important what platform you pick out of these three; it’s important that you pick one of these three because people understand that if you have used one, it is likely you can easily pick up another.
Workflow Management Platforms And Data Storage Analytic Systems
In addition to picking a cloud provider, you will want to pick a tool to manage your automated workflows and a tool to manage the data itself. From the job description Airflow and Snowflake were both referenced.
These are not the only choices, by any stretch of the imagination. Other popular options for orchestration are Dagster, and Prefect. We actually recommend starting with Airflow and then looking to others as you get more familiar with the processes.
Don’t be concerned with learning all these tools at first; keep it simple. Just concentrate on one or two, since this is not our primary focus.
Picking Data Sets
Data sets come in every color of the rainbow. Your focus shouldn’t be to work with already processed data; your attention should center on developing a data pipeline and finding raw data sources. As the data engineer, you will need to know how to set up a data pipeline and pull the data you need from a raw source. Some great sources of raw data sets are:
OpenSky: provides information on where flights currently are and where they are going, and much, much more.
Spacetrack: is a tracking system that will track, identify, and catalog all artificial satellites orbiting the Earth.
Other data sets: New York Times Annotated Corpus, The Library of Congress Dataset Repository, the U.S. government data sets, and these free public data sets at Tableau.
Pulling data involves a lot of work, so when you are picking your data sets, you will probably find an API to help you extract the data into a comma-separated value (CSV) or parquet file to load into your data warehouse.
Now you know how to find your data sets and manipulate them. So, what do you do with all this raw data that you’ve got?

Visualize Your Data
An easy way to display your data engineering work is to create dashboards with metrics. Even if you won’t be building too many dashboards in the future, you will want to create some type of final project.
Dashboards are an easy way to do so.
Here are a few tools you can look into:
With your data visualization tool selected you can now start to pick some metrics and questions you would like to track.
Maybe you would like to know how many flights occur in a single day. To build on that, you may want to know destinations by flight, time, or length and distance of travel. Discern some basic metrics and compile a graph.
Anything basic like this will help you get comfortable figuring out your question of “why?” This question needs to be answered before you begin your real project. Consider it a warm-up to get the juices flowing.
Now let’s go over a fe w project ideas that you could try out.
3 Data Engineering Projects: Ideas
Beginning Data Engineering Projects Example: Consider using tools like Cloud Composer or Amazon Managed Workflows for Apache Airflow (MWAA). These tools let you circumvent setting up Airflow from scratch, which allows you more time to learn the functions of Airflow without the hassle of figuring out how to set it up. From there, use an API such as PredictIt to scrape the data and return it in eXtensible markup language (XML).
Maybe you are looking for data on massive swings in trading over a day. You could create a model where you identify certain patterns or swings over the day. If you created a Twitter bot and posted about these swings day after day, some traders would definitely see the value in your posts and data.
If you wanted to upgrade that idea, track down articles relating to that swing for discussion and post those. There is definite value in that data, and it is a pretty simple thing to do. You are just using a Cloud Composer to ingest the data and storing it in a data warehouse like BigQuery or Snowflake, creating a Twitter bot to post outputs to Twitter using something like Airflow.
It is a fun and simple project because you do not have to reinvent the wheel or invest time in setting up infrastructure.
Intermediate Example: This data engineering project is brought to us by Start Data Engineering(SDE). While they seem to reference just a basic CSV file about movie reviews, a better option might be to go to the New York Times Developers Portal and use their API to pull live movie reviews. Use SDE’s framework and customize it for your own needs.
SDE has done a superior job of breaking this project down like a recipe. They tell you exactly what tools you need and when they are going to be required for your project. They list out the prerequisites you need:
In this example, SDE shows you how to set up Apache Airflow from scratch rather than using the presets. You will also be exposed to tools such as:
There are many components offered, so when you are out there catching the attention of potential future employers, this project will help you detail the in-demand skills employers are looking for.
Advanced Example: For our advanced example, we will use mostly open-source tools. Sspaeti’s website gives a lot of inspiration for fantastic projects. For this project, they use a kitchen-sink variety of every open-source tool imaginable, such as:
In this project, you will scrape real estate data from the actual site, so it’s going to be a marriage between an API and a website. You will scrape the website for data and clean up the HTML. You will implement a change-data-capture (CDC), data science, and visualizations with supersets.
This can be a basic framework from which you can expand your idea. These are challenges to make you push and stretch yourself and your boundaries. But, if you decide to build this, just pick a few tools and try it. Your project doesn’t have to be exactly the same.
P.S. If you need a template to help you track this, you can use this one!
Now It’s Your Turn
If you are struggling to begin a project, hopefully, we’ve inspired you and given you the tools and direction in which to take that first step.
Don’t let hesitation or a lack of a clear premise keep you from starting. The first step is to commit to an idea, then execute it without delay, even if it is something as simple as a Twitter bot. That Twitter bot could be the inspiration for bigger and better ideas!
Low-Code Data Engineering On Databricks For Dummies

Modern data architectures like the lakehouse still pose challenges in Spark and SQL coding, data quality, and intricate data transformations. However, there's a solution. Our latest ebook, "Low-Code Data Engineering on Databricks For Dummies," offers an insight into the potential of low-code data engineering. Learn how both technical and business users can efficiently create top-notch data products with swift ROI.
How the lakehouse architecture has transformed the modern data stack
Why Spark and SQL expertise does not have to be a blocker to data engineering success
How Prophecy’s visual, low-code data solution democratizes data engineering
Real word use cases where Prophecy has unlocked the potential of the lakehouse
And much, much more
Video Of The Week: The One Word On My Resume That Got Me My First Data Analyst Job Out Of College
Join My Data Engineering And Data Science Discord
Recently my Youtube channel went from 1.8k to 24k and my email newsletter has grown from 2k to well over 6k.
Hopefully we can see even more growth this year. But, until then, I have finally put together a discord server. Currently, this is mostly a soft opening.
I want to see what people end up using this server for. Based on how it is used will in turn play a role in what channels, categories and support are created in the future.
Adopting CI/CD with dbt Cloud
There’s a shift happening in the data industry. Those who write SQL models want to be the ones who ship and productionize that code. Why? Because relying on another team to do it is too damn broken. Too often a data analyst is not empowered to create clean data tables in the company data warehouse herself, despite the fact that it is a necessary first step to any analysis. As a wise man once wrote, “an analytics engineer is really just a pissed off data analyst”.
The DevOps movement was born out of that frustration. Tired of the organizational disconnect between developers and IT operations, software teams decided to change how they worked to have more continuous ownership of the code. Developers got really good at not only building features, but also integrating new code, testing, shipping, and supporting it. Companies that embraced this agile way of working, shipped more frequently and benefited greatly.
Rebuilding Payment Orchestration at Airbnb
Airbnb’s payment orchestration system is responsible for ensuring reliable money movement between hosts, guests, and Airbnb. In short, guests should be charged the right amount at the right time using their selected payment methods; hosts should be paid the right amount at the right time to their desired payout methods.
For historical reasons, Airbnb’s billing data, payment APIs, payment orchestration, and user experiences were tightly coupled with the concept of a reservation for a stay. Unfortunately, this meant that a payment-related feature for stays had to be rebuilt for other products — for example, Airbnb Experiences — and each implementation may have its own product-specific quirks. As you can imagine, this approach is neither scalable nor easy to maintain.
Data Discovery Tools: Should You Build or Buy?
Every data team has data discovery on their mind, even more so as they begin to scale. Whether they already have a data discovery solution, or are considering taking the first step in implementing one— the growing pains of a scaling data organization means looking for ways to empower both you and your team to search, find, and derive conclusions from data with minimal hand holding.
This is where data discovery comes in, and the time that finding the optimal data discovery service or solution is important. After all, it’s a big transition to implement one, and an even bigger transition to move from one tool to another should your first solution not be sufficient. Based on our experience with the dozens of data organizations we work with, we’ve put together a guide on finding the best data discovery solution for your organization. We’ll be covering:
End Of Day 40
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, the modern data stack, tech, and start-ups.
If you want to learn more, then sign up today. Feel free to sign up for no cost to keep getting these newsletters.