
From Raw Data To Deploying Machine Learning Models – Dealing With Raw Data
MANAGING THE DATA LIFE CYCLE

Photo by Hunter Harritt on Unsplash
Before you can develop a machine learning model, your team will need to deal with the raw data.
The cliche about data being the new oil has some merit.
Data, like oil, when pulled from an application.
It can often be unrefined, dirty and unusable.
Similar to trying to put raw oil into a car, putting raw data into a machine learning model won’t work.
Instead, you will need to process the data to a usable state.
There is a reason data experts say, “Garbage In Garbage Out.” It’s because at the end of the day, regardless of how fancy the machine learning model develops, if you put bad data in, then only bad data can come out.
There are lots of issues with data that make it difficult to work with. Data might not be well integrated across your company's various third-party tools, there might be duplicate data and there is the process of managing changes in data over time.
These are the more apparent issues that you will need to deal with as you start refining your data. This isn’t even taking into consideration the ways data can be wrong or bad.
In this article we will discuss some of these data issues as well as talk about some places you can find raw data.
Examples Of Raw Data Issues
When you are processing data there are several basic areas you will need to take care of regardless of the type of data you are working with. It could be healthcare, transportations, finance or e-commerce. Most data still requires standardization, de-duplication and tracking data amendments and data updates.
Data Consistency And Standardization
One of the major issues you run into when refining data, is not that the data is bad it might just be inconsistent. For example, you might have a date with 8 different formats, inconsistent IDs across your various applications data, and .
Like joining HR, Sales, Operations and Finance data.
A lack of consistency and standards, even if the data is “clean” doesn’t make it useful.
As much as data governance can be boring and mundane. It’s what makes gaining insights across organizations possible.
Data standards allow teams to build actual analysis off of data because they know what to expect.
This does require a decent amount of upfront investment. However, when done well, it allows your teams to take advantage of multiple data sets and the insights they can provide.
Inaccurate Data
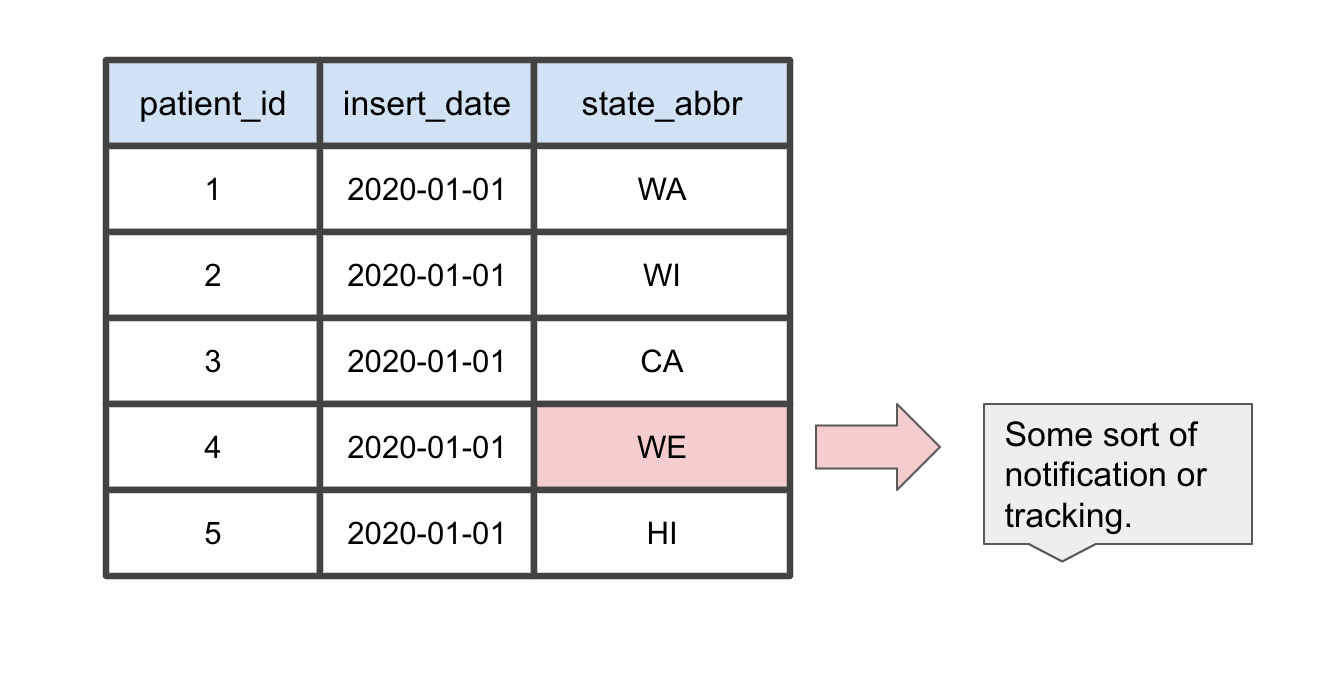
Another common issue that can occur is the data you are working with is inaccurate. The data might have been entered wrong or your application might have a bug. There are lots of ways bad and inaccurate data can come in and it’s always where you don’t expect it.
For example our team has seen US state abbreviations that were input incorrectly. Like the state abbreviation “WE” instead of “WA” and “WI. We had assumed that the application layer would double check if the state abbreviations were valid. That was not the case.
These data problems happen all the time and assuming the application will catch the data problems.
So as you are pulling data from third party and internal applications you will need to create systems to check data. This can be done by creating QA scripts that ensure the data is valid.
Data Completeness

When you are learning how to use machine learning models with tutorials, you will often have perfectly complete data sets. Every person’s age will be filled out, every location of where a survey was taken, etc.
This isn’t always realistic. Sadly much of the data is often incomplete. Depending on how the data is sourced, there can be lots of null values. In turn, this can break machine learning models.
Duplicate data
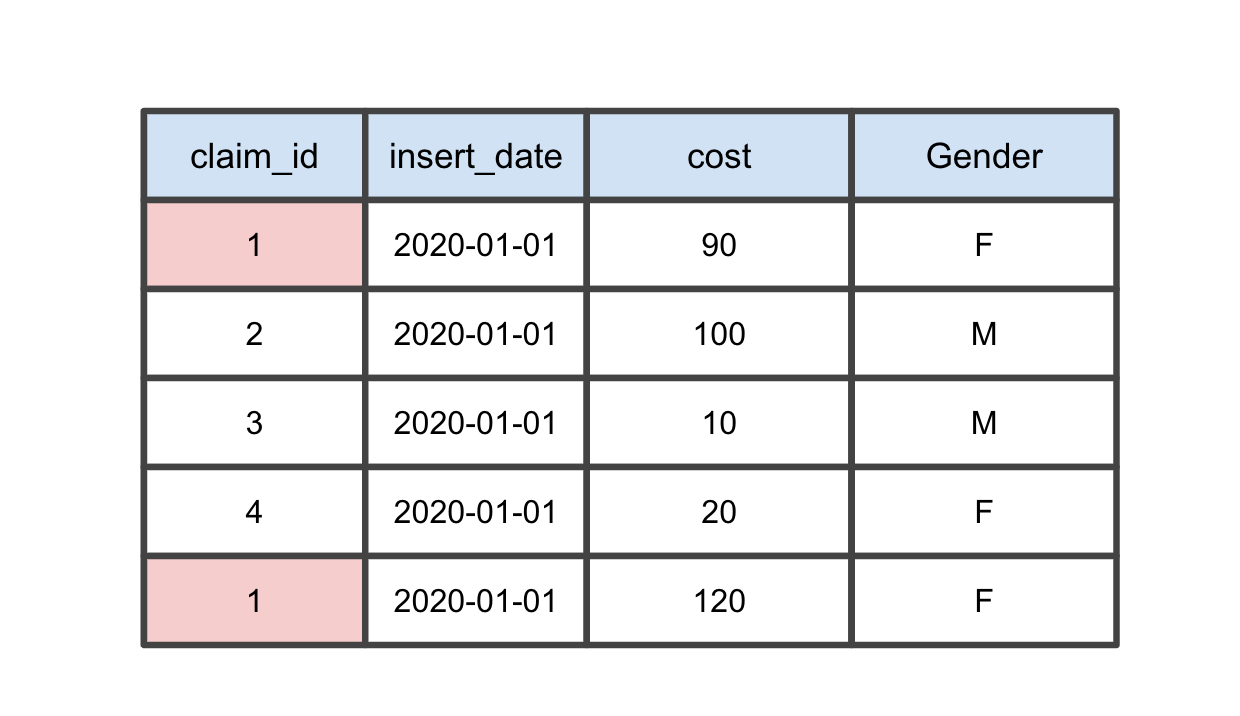
Duplicate data is quite common in the data world. There are many different causes. Perhaps a user clicked the submit button twice and both clicks got logged, or a user booked a flight, cancelled it and booked it again. Depending on how the application manages these interactions determines whether or not you have duplicate data.
This could lead to accidental double counting or incorrect insights. A company’s KPIs(Key Performance Indicators) can be drastically thrown off due to duplicate data. One of many reasons why you will need to ensure that the data your team is reporting on represents one action, as just that, one action.
Examples Of Data Sources
Data is far more prevalent than it’s ever been. Third-parties often have some sort of API or data extraction method that can easily be accessed, data.gov and other government websites. As we go through the process of pulling, processing and designing data systems, you might want to apply some of the skills we are talking about.
So if you need some data sets, here are some data sets that you should be able to use.
Public Data Sets
There are a lot of great options for public data. Some of these data sets are just downloadable csvs other are APIs. Overall, these should all be free options.
1. Google Public Data Explorer
4. DBpedia
5. Kaggle
6. National Archive of Criminal Justice Data
7. Bureau of Justice Statistics
8. National Center for Environmental Health
9. National Climatic Data Center
APIs
Most large third party tools will offer some form of an API that allows you to pull data from. Some popular examples of this include Salesforce, QuickBooks and Workday. These tools manage a wide range of daily business workflows. In turn these tools track a lot of your team's data. By using this data your team can gain a lot of insight into your business.
Quality Data Matters
It can be tempting to start working on a machine learning or data science project without considering the underlying data. However, if you don’t spend time ensure that your data is accurate and reliable. Then regardless of what model your team develops, the outputs won’t be correct.
Data quality, and sourcing matters. Your team needs to ensure that whatever data your team is relying on to make decisions is valid. Otherwise, your team might as well guess.
What To Expect For This Week
This will be our first week for learning how to take data from raw data to machine learning. For this week we will be talking about raw data, databases and data warehouses. These are some of the base layers of data you will work with at large companies as a data scientist or machine learning engineer.
Here is what to expect for this week:
Thursday - What Is A Data Warehouse - Video
Friday - Walk Through Data Warehouse Design - Video
Friday - What Is A Data Warehouse - Post
If You Can’t Wait, And Want To Start Learning. Consider Checking Out The Content Below:
4 SQL Tips For Data Scientists
What Is Dask and How Can It Help You as a Data Scientist?
Data Engineering 101: An Introduction To Data Engineering