
From Basics to Challenges: A Data Engineer's Journey with APIs
Back To The Basics
If you've had to build any data pipelines for analytics, then you're likely very familiar with the extract phase of an ELT or ETL.
As the name suggests the extract phase is when you connect to a data source and "extract" data from it. The most common data sources you'll be interacting with being databases, APIs, and file servers(via FTP or SFTP).
With my recent focus on going back to the basics, it occurred to me that I have never written about APIs and how we interact with them as data engineers.
Now, there are plenty of APIs that have caused me a lot of heartburn in my career and there are others that have been a piece of cake to handle.
But it all comes down to how the API is set up and the design choices made when it was built.
So, in this article, I wanted to talk about, first, the basics of an API, followed by reviewing some of the issues you'll deal with as a data engineer.
What Is An API
As a quick refresher, an API, or Application Programming Interface, is like a bridge that allows different software systems to talk to each other.
A good analogy for an API that is probably over used is the restaurant example.

Picture this: you're at a restaurant. You, the customer, have a menu that is like the API documentation, and you can choose what you want. You tell the waiter, the API, your order; then they take your order to the kitchen, which acts as the API server and brings back the food, the data, or the result.
You don't need to know how the kitchen works to enjoy your meal, and similarly, with an API, you don't need to know how the other software system works; you just send a request and get a response.
Requesting Data Examples
In order to explain how we, as data engineers, work with APIs, let's actually go through the process of making a request, and then I'll break out the various steps.
There are a few good examples of public APIs from which you can pull data. Many of them are pretty easy to work with.
For example, you could use the US earthquake data or the Purple Air API.
Below is how you could call back data from the US earthquake data API using Python.
import requests
from datetime import datetime, timedelta
#Setting parameters
today_date = datetime.now()
date_15_days_ago = today_date - timedelta(days=15)
start_time= date_15_days_ago.strftime('%Y-%m-%d')
end_time = today_date.strftime('%Y-%m-%d')
# Define the API endpoint
url = f"https://earthquake.usgs.gov/fdsnws/event/1/query?format=geojson&starttime={start_time}&endtime={end_time}"
# Send a GET request
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
data = response.json()
# Extract earthquake features
features = data['features']
...As you can see, this is far from a complex example.
You’ve got the:
End point - https://earthquake.usgs.gov/fdsnws/event/1/query
Parameters - format=geojson&starttime={start_time}&endtime={end_time}
The request - requests.get(url)
The response - response
You’ll also notice that we’re using a GET method in the requests.get(url) of which there are more methods, including POST, DELETE, PUT and several others. Truthfully, you’ll mostly use GET and POST.

Authentication
Something you don’t see in the code above is any form of authentication.
And authentication is an important part of APIs. After all, if you’re working with any sort of system that has internal data from your company, you don’t want just anyone to access it.
So, you might use something like the code below.
import requests
# Define your API endpoint and API key
url = 'https://api.example.com/v1/data'
api_key = 'API KEY HERE'
# Set up headers with the API key for authentication
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
# Send a GET request
response = requests.get(url, headers=headers)
# Check if the request was successful
if response.status_code == 200:
data = response.json() Of course, there are multiple ways a SaaS or a solution might implement their API authentication. In some cases, a solution might actually use multiple methods. In fact, on one project I worked on, I was provided the standard API key and secret and proceeded to test the API. I immediately found out that I still couldn't access the API.
After further discussion, no one informed me that the API also required whitelisting.
So, when you're dealing with APIs, here is a list of some of the methods you might use to authenticate your API.
API Keys - API keys are simple. A unique string gets generated by the server, which clients use to authenticate their requests. In this case, simple also means less secure.
OAuth (Open Authorization) - This is a token-based authentication method, which means that instead of using traditional session-based authentication methods like username and password, the server will create a token that the user will store once the user is authenticated. It then allows users to grant third-party applications access to their resources without sharing credentials. Also, don’t forget that there is OAuth 2.0.
Basic Authentication - With simple authentication you send a Base64-encoded string containing the username and password with each request.

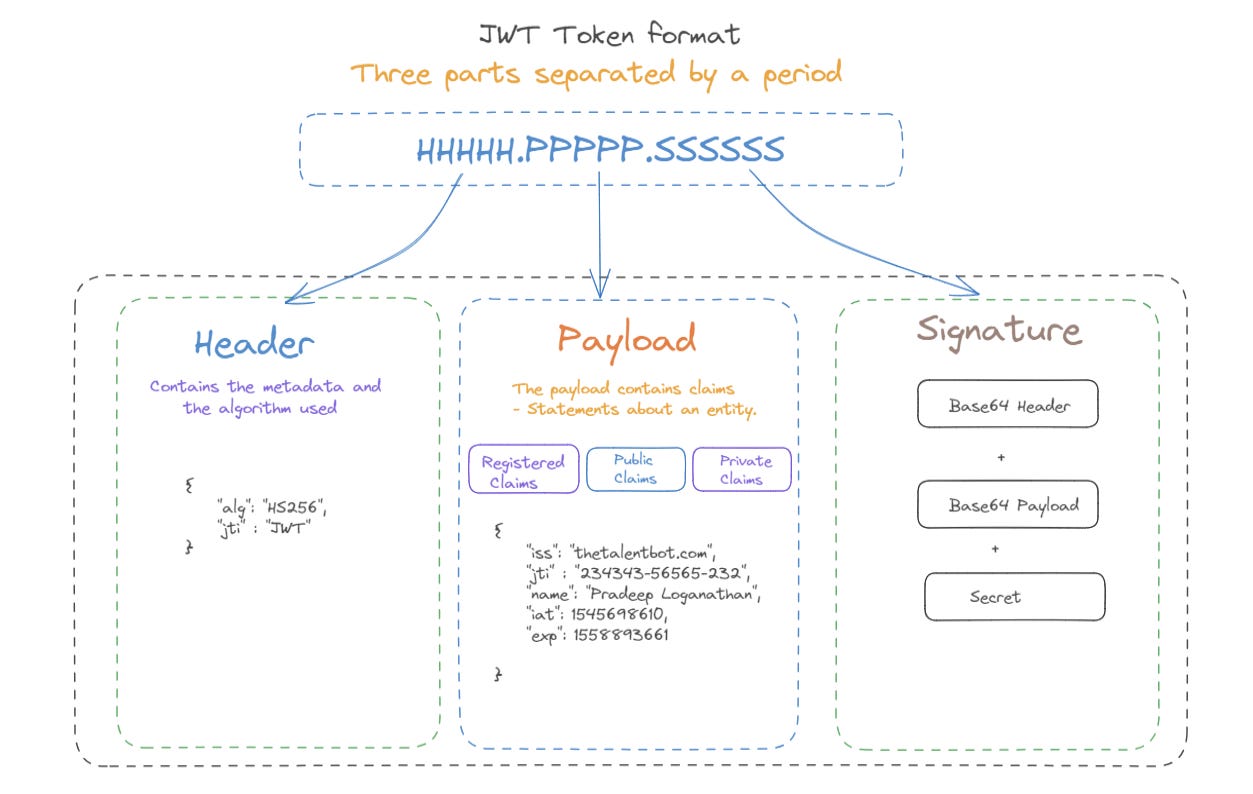
JWT (JSON Web Tokens) - A JWT is a compact, URL-safe token that represents some set of information, broken down into a header, payload and signature.
IP Whitelisting - Restricts API access to a list of known, trusted IP addresses.
If you’d like to learn more, Alex Xu has a great image here walking through some of the most frequently utilized API authentication methods.
Looking back through this article so far, most of what we’ve discussed so far has been the set-up. We haven’t actually even touched any data.
Parsing Data
So you've made your request, you've been authenticated, and now we can get back to the data.
That’s why the next step you'll face is parsing the data. This data often comes back in a few different forms.
Many APIs you’ll work with will return JSON, but they might also give you a CSV to download. Still in other cases they might give you XML and a handful of other data formats, but in my experience it’s mostly been JSON.
Assuming you get back JSON, then you can use a script like the one below to parse it. The script you create will likely be more generalized but for now I am going to be explicit.
# Check if the request was successful
if response.status_code == 200:
# Parse the JSON response
order_data = response.json()
# Initialize an empty list to store the parsed data
order_list = []
for order in order_data:
# Parse the relevant information from each order object
order_dict = {
'id': order['id'],
'customer_name': order['customer_name'],
'product_id': order['product_id'],
'cost': order['cost'],
}
# Append the parsed data to the list of dictionaries
order_list.append(order_dict)I do need to point out that this assumes your data is flat and you don’t have any nested fields with multiple layers of data.
If you do start getting multiple entities that are nested inside your JSON, then it’s time to start looking at your data model.
All that being said, you still need to deal with the fact that you might be pulling over more data than a single response might be able to return.
Pagination
Ok, I did skip pagination.
But likely, you're parsing the first set of data returned and then dealing with pagination. That is to say that you'll get your JSON back, but then you need to use pagination.
Pagination is the process of dividing a large set of data into smaller, more manageable chunks. Also you could view this as pages.
And, of course, pagination can come in all sorts of flavors!
Offset-Based Pagination - In this approach, you, the client, specify an offset or the number of records to skip and a limit or the number of records to return. For example, in a query like GET /items?offset=20&limit=10, the API would skip the first 20 records and return the next 10. It does tend to feel a little clunky as a user. Because now, I need to try to keep track of how I am pulling the data. Which makes me nervous. Although all you really need to do is offset += limit to get the next offset. However, there is also a risk of inconsistent results if data is being modified concurrently.
Cursor-Based Pagination - Instead of an offset, the server provides a cursor (often a unique identifier or encoded string) representing the last item on the current page. For example, you might use this cursor to fetch the results on the next page, and the URL could look something like GET /items?cursor=abc123&limit=10. Then, in your code, you'll use a cursor = data['next_cursor'].
Page-Based Pagination - In this approach, you'll use a page number and a page size to get the next set of data. It would look something like GET /items?page=2&per_page=10. In which the request would fetch the second page with 10 items per page. When it comes to pagination, I'd say this is my second most preferred method to interact with.
Hypermedia Pagination (HATEOAS) - The API includes pagination links in the response, guiding the client on how to navigate to the next or previous pages. For example, the API might return links like "next": "/items?page=3" and "previous": "/items?page=1". I have seen some versions of this in APIs I have worked with, but generally it’s only included a “next” value and not previous, last, etc.

Overall, the type of API you interact with as well as how you authenticate, paginate and have to parse your data will be the key decision points you'll have to make as you're building the E for your ETL/ELT, assuming you're not using something out of the box.
Now I will be listing out some of the challenges you'll run into on top of the points above, but if you're enjoying this topic do let me know because I'd also like to go into a few other similar topics and would love your feedback.
Challenges You'll Run Into With APIs
APIs Change - One of the most common issues you'll likely hear from data engineers trying to maintain their data pipelines is that some APIs can change frequently. This means that the values they were expecting can be removed, the endpoints can change, etc. Which can lead to a lot of maintenance work.
Sometimes the API doesn't tell you there's a limit - Whether it is due to poor documentation or just a lack of error messaging; I have personally run into this issue and talked to half a dozen people who have also suffered this problem. You reach out to an API, and for some reason, you only get 1000, 5000, and 10000 entities back. And the documentation doesn't talk about any limits or any way to get the next set of data. One API was so bad that it randomly picked 1000 data points to bring back, and you couldn't even paginate it if you wanted to.
Nested API calls - One of the challenges I ran into was when I worked at Facebook, we wanted to pull data from the Asana API. At the time, I recall having to go through two or three steps. If I recall correctly, at the time, it went something along the lines of Projects → Sections → Task(or something like that, it’s been 3 years). Looking at the API now, it doesn't look like this is the case. But at the time, I had to get a list of all the projects, then a list of all the sections in each project, and then a list of all the tasks in said project.
Back To Basics With APIs
Data engineers continue to need to understand how to write code that extracts data from APIs. Even when there are some tools that do manage some of these connections, they don't manage all of them.
In turn, understanding what to expect when working with APIs can help you work quickly when developing your extract script.
As always, thanks for reading.

Join an exclusive virtual event on October 1 in which VAST Data and other leading AI thought leaders will provide the latest perspective on enterprise AI adoption and the future of data, tech innovation, and progress for every industry across the globe.
Accompanying VAST on the virtual stage will be AI's visionary leaders, including:
Jensen Huang, Founder and CEO of NVIDIA
Charles Liang, Chairman, President and CEO of Supermicro
Michael Intrator, CEO and Co-Founder of CoreWeave
Andrew Ng, Founder of DeepLearning.AI
Nicolas Chapados, Vice President of Research at ServiceNow
David Rice, Global Chief Operating Officer at HSBC
Lila Tretikov, Partner and Head of AI Strategy at NEA
And many more
The event will include multiple announcements that bring to market new technology to drive innovation, form communities to connect and nurture the AI ecosystem, and establish new partnerships to accelerate AI deployments.
Don’t miss this opportunity to position yourself at the forefront of data and AI.
Event Details:
Date: October 1, 2024
Time: 8AM PT / 11AM ET
Thank you Vast Data for sponsoring this newsletter!
Join My Data Engineering And Data Science Discord
If you’re looking to talk more about data engineering, data science, breaking into your first job, and finding other like minded data specialists. Then you should join the Seattle Data Guy discord!
We are now well over 7000 members!
Join My Technical Consultants Community
If you’re a data consultant or considering becoming one then you should join the Technical Freelancer Community! We have over 700 members!
You’ll find plenty of free resources you can access to expedite your journey as a technical consultant as well as be able to talk to other consultants about questions you may have!
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Building Credibility As A Data Leader
“It’s usually not enough to point out impending problems/opportunities or even to propose solutions. You may have to garner support for your proposed solution or conduct small pilot tests. All of this involves the need to influence powerful people.”
― Allan R. Cohen, Influencing Up
Having good ideas and communicating them effectively isn’t enough—especially in larger organizations where numerous competing ideas and initiatives are constantly at play from different directors and VPs.
To make real progress, you need to build influence within the organization.
Sometimes, influence means convincing others that your idea is right. Other times, it means convincing them that they are wrong. Many of us in the technical world believe that because we are the experts, we’re already the voice of authority. That might be true in smaller companies where you’re the sole technical person. But in larger organizations, it’s rarely that simple.
I used ChatGPT o1 to do PostgreSQL basics
By Daniel Beach
Weap and moan all you keyboard jockeys, you simple peddlers of code. Your doom and what you feared greatly is coming to pass. You’ve been replaced.
At least that’s what the AI pundits are saying about the new o1 OpenAI model that apparently blows the socks off the previous 4o model when it comes to programming and other benchmarks.

I’ve been trying to ride down the middle of the tracks when it comes to AI and programming. I’ve been writing code and doing Data Engineering long enough to see the obvious flaws in the current AI models. I’ve also embraced AI into my development lifecycle for probably 2 years now.
End Of Day 145
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
Thanks
#BuildStrongFoundations-- I appreciate you took the time to write this!
I'd add a few points surrounding the authentication key. We don't want to expose that. I'd expect companies have systems in place to prevent pushing code with exposed keys. For personal projects, GitHub has a tool now that signals when that happens.
Thank you!