
Breaking Down Data Silos: Will Iceberg Finally Let Us Create A Single Source Of Truth?
With the recent acquisition of Tabular, it’s hard for me not to wonder...
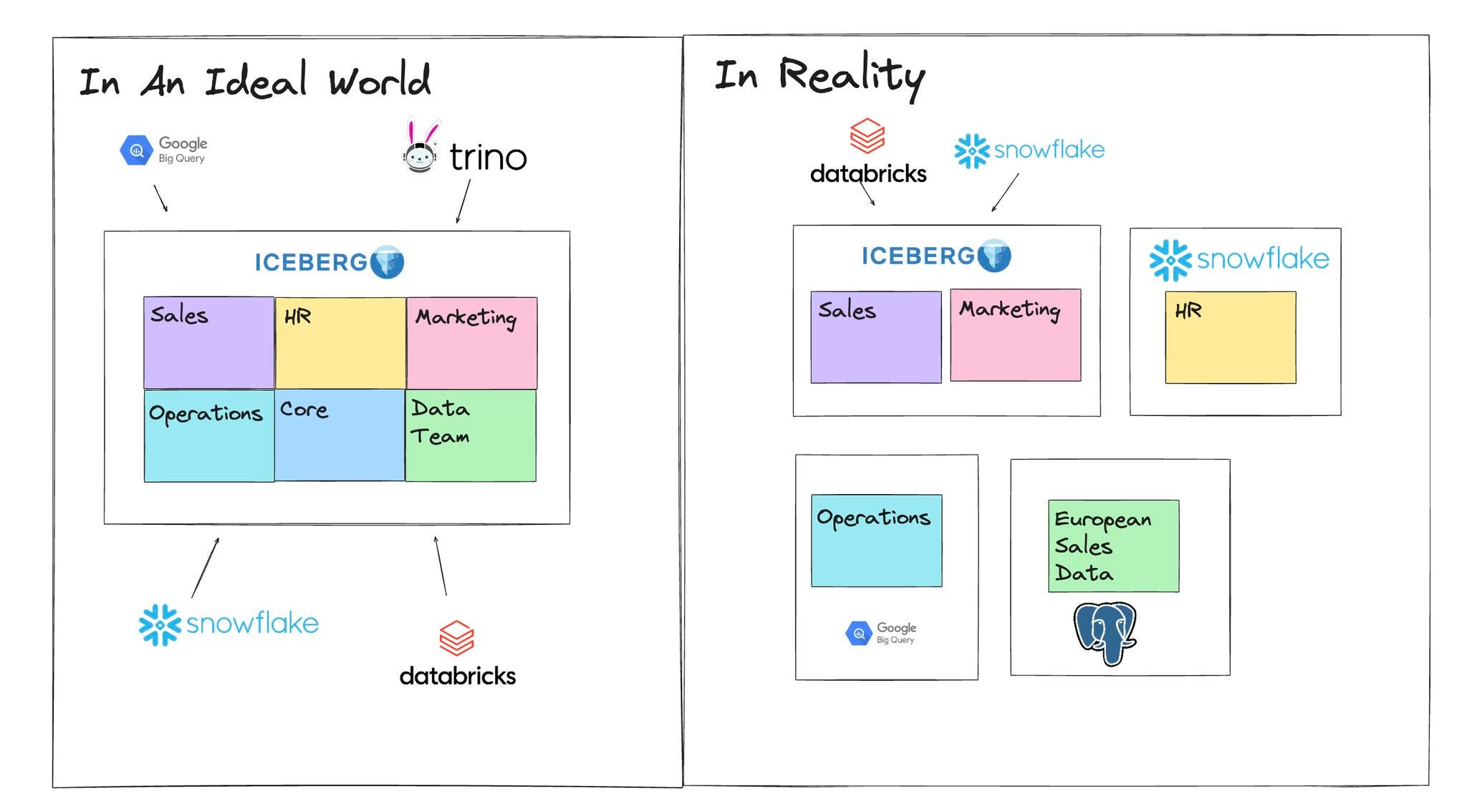
Will large enterprises really create a single core data layer around Iceberg?
I have seen companies where their data is centralized into a single core data layer for analytics(which I am saying data layer as a general term to cover data warehouse, lake house, mesh, etc).
But in particular, that was at companies like Facebook which had a mature set of processes in place to ensure engineers utilized the same technology tool sets. This made it really easy to use data from other teams. Not to mention the fact that it was very clear which table was “THE” table, like the User table at Facebook that everyone knew and was literally referenced in the onboarding.
This isn’t always the case in many large enterprises. Many companies must deal with multiple data analytics platforms, one for marketing, one for the UK office, one for the recently acquired competitor, etc. To add to the problem, in some cases, there is a struggle to even have a single agreed-upon customer table.
This is caused by:
Office politics
Regulations
Shadow data teams
A single engineer who thinks that using <Insert Technology> will be optimal
Now perhaps I am thinking about this too rigidly. I am just curious to see if we could actually get to a point where we get to that mythical "EDW" we all read about but rarely have seen.
And perhaps it’s time to throw off some of the limitations of needing to only use one solution like BigQuery, Teradata or Snowflake to get there.
In this article I wanted to outline some of blockers that data teams and organizations will have to overcome as they attempt to create a single core data layer for analytics.
Is It Possible?
Is the final state possible?
Yes.
Let’s just get that out of the way. I referenced my example at Facebook and I have seen other companies do it. Many who are traditional large enterprises.
But it takes a considerable amount of effort, and even once completed, there are always little exclaves of data that live here and there.
Politics and Silos

One of the common issues many large enterprises run into is company politics. If you’re the VP or department head, you’ll likely want to spearhead the new and cool AI, Big Data LLM initiative, especially if you just got hired on.
That way you can say you drove some level of impact that perhaps doesn’t even make sense.
Or as brought up by Ravi, you want to be the one that successfully runs the migration to the new cool technology.

Each of these VPs and department heads create yet another data silo. All so they can have control. I was part of one of these projects early in my career. Did several data warehouses and a data lake already exist.
Yes.
Did someone on our leadership team want to get control of their own so they could pick what projects were done.
Yes.
Now suddenly you have a 5th data silo with a lot of repeat data.
Of course, not all data silos are created due to politics. Some are due to regulations, others due to shadow data teams, and still others just come from a lack of communication between different departments.
Shadow Data Teams
Now as referenced above, data silos have multiple sources. Even if you do get a company on board with building a single core data layer, some team, somewhere, will want a data set before it’s scheduled to be deployed.
In turn, they’ll buy a low code solution that keeps them from having to bubble up to management and use that to build their own data layer.
What’s great is that nowadays, things are in the cloud. Meaning you don’t have to ask IT to set up a server or manage anything. You can just spin up your own BigQuery or Snowflake instance and “Boom,” you have a “data warehouse.”
Now before you know it, you’ve got three customer tables each with different sources and different definitions of the term customer.
The Unspoken Problem of Data Silos
Here is the problem with data silos that goes beyond just the fact that data is partitioned by different tooling.
Even if you were to have federated queries, that can run across multiple data platforms. You run into the issue of every team creating their own versions of the same tables. A company might have five different customer tables, six sales tables, and three general ledger tables that all might be updated at different rates and might have different sources.
Some will include all data and some might just include data from specific entities; they all could be named in such a way that you can’t tell them apart.
This is the other side of attempting to create a single core layer of data (when I say that, I mean the base building blocks of data that represent your business, think customer, transaction, etc).
It’s not impossible but it won’t be fixed by technology alone, unless the technology makes it easy to fall in line and create very clear and concrete data models.
Security What I Am Really Scared About
Now you can manage security through various solutions such as Unity Catalog. But, you still have to actually do it. For example, below is a conversation coming from a post I made about having a single layer of data stored in Iceberg where one of the data analysts referenced not knowing how security would be implemented in a future project where they were doing just that.
My best guess is that the engineering team does know how security will be implemented. However, that is an assumption. If you plan to make a single core layer of data, it’s still important to maintain security and privacy. Not everyone should have access to everything. So part of your project should consider this as a crucial aspect.

What Will Likely Happen Next
I think my biggest point in this article is that companies won’t be able to switch to a single data layer overnight.
It’ll take a lot of communication, process and collaboration to get multiple department leaders on the same page.
I also believe that Iceberg has the potential to play a bigger role beyond just creating a single analytical layer. For example, Veronika posted their thoughts on how Iceberg might be used even for transactions or at least to make managing the process of getting data from transaction systems to analytical ones even easier.

But much of this is currently just theory(I assume some companies have something like this implemented somewhere).
Nevertheless, I am sure there are large consulting companies currently putting together presentations and white papers on how and why you should switch to a single Iceberg layer (some supporting Databricks and others Snowflake because, you know, those are the only two options). It might be the new meta that keeps consultants paid for the next 5 years.
So do watch out for new “best practices” and repackaging of old design practices. And make sure that whatever the future holds, you ask why you’re building what you’re building.
Technology Hasn’t Been the Only Issue
Rarely has technology alone been enough to change the way humans operate. I will add that if Iceberg or the future state of Tabular + Databricks makes it easy for engineers and analysts to do the right thing, then yeah, it’ll be more common to have a single core layer of data that represents a business.
Because then despite all of our politics, bad habits, and other internal company issues, the data layer might be able to push past it.
So is the ideal state possible? Yes. Will a lot of consulting companies make a lot of money from convincing companies that they should switch to this new future stay? Also yes.
With that, thanks for reading.
Complete Real-Time Stream Processing

The Power of Apache Flink in Minutes
Powered by Apache Flink, DeltaStream simplifies stream processing by eliminating setup complexities and the need for Flink expertise. Build materialized views and streaming applications with simple SQL and centralize all your data stores for a unified view and comprehensive insights. DeltaStream's flexible permissions model allows precise control over data access, enhancing team collaboration and security. With Role-Based Access Control, data governance is streamlined across the enterprise. Adapting to cloud-based or private SaaS deployment, DeltaStream's serverless structure eliminates cluster maintenance. Empower your team with real-time insights and innovative capabilities.
Interested? Check the link below for a free trial.
Join My Data Engineering And Data Science Discord
If you’re looking to talk more about data engineering, data science, breaking into your first job, and finding other like minded data specialists. Then you should join the Seattle Data Guy discord!
We are close to passing 7000 members!
Join My Technical Consultants Community
If you’re a data consultant or considering becoming one then you should join the Technical Freelancer Community! I recently opened up a few sections to non-paying members so you can learn more about how to land clients, different types of projects you can run, and more!
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
Explaining Data Lakes, Data Lakehouses, Table Formats and Catalogs
In the past few years, open table formats have shaken up most of the data world. They have revolutionized how data lakes are managed which led to the Data Lakehouse. This article aims to explain key aspects of open table formats, their evolution, and their impact on data lake ecosystems.
We will take a look at leading formats like Apache Iceberg, Delta Lake, and Apache Hudi, providing insights into their technical methodologies and implementation strategies and we’ll also discuss how catalogs fit into the lakehouse architecture to demystify some of the confusion and complexity around Snowflakes and Databricks catalog services; Polaris and the open source Unity Catalog.
End Of Day 133
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
Microsoft is attempting “one source of truth” with their Microsoft Fabric OneLake.