
Behind the Rust Hype: What Every Data Engineer Needs to Know
Rust, Rust, Rust. It’s truly amazing how this language feels like it has taken the Data Engineering community by storm.
It’s the cool new and shiny toy everyone is playing with. Can we just blame Polars for this newfound obsession? But is it just a toy? Is there a future for Rust in everyday Data Engineering? Is Python in danger?
That’s what we are going to look into today. Like one of the inquisitive hobbits peering into the Lost Seeing Stones, we will try to divine the future for the hoards of Python Data Engineers. Do they have anything to fear? Should they pay attention to Rust? What does the future hold?
Let’s dive in.
Starting with the Conclusion
Instead of doing what I’m supposed to do, keep you in suspense until the end, I’m going to give it to you straight. I will provide you with the conclusion, then try to back it up for the rest of the time.
“Rust will not take over the average day-to-day Data Engineering tasks. Rust will eventually take over more backend tooling by those building tools for Data Engineers to use.”
Sure, we’ve seen Rust show up in a few areas …
Polars and Datafusion for high-performance Dataframes
Developer tooling like Ruff
Building backend tools like Delta-rs
Certain high-performance and reliability pipelines
Rust essentially seems to be the language of choice to build the underlying tooling and systems that Data Engineers use … abstracted away with Python bindings.

Backing up the Conclusion by Diving In
It was important to start with the conclusion when talking about Rust for Data Engineering in the age of Python because folks are liable to drop what they are doing and run off into the Rust sunset only to find a goose egg at the end of the rainbow instead of a pot of gold.
First, are there any actual jobs for Data Engineering with Rust?
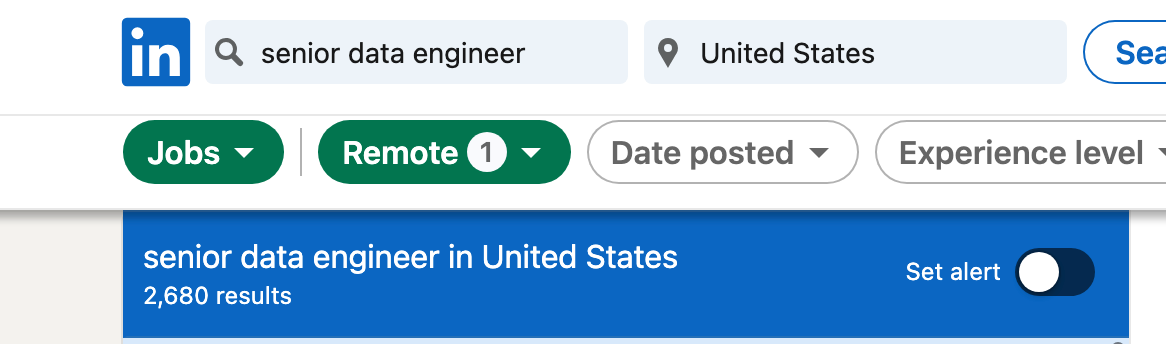
If we search Linkedin for remote Senior Data Engineer jobs, we get about 2,680 results.
How many of them have Rust listed? Pretty much none. You will find Java, Scala, and even Golang (besides Python), but not Rust.
The reality of bringing Rust into a Data Platform team is going to be low, probably reserved for the forward-thinking and cutting-edge groups. The moral of the story is don’t learn Rust because you think it will help you get a Data Engineering job anytime soon.
Where is Rust Being Used in Data Engineering?
Well, all is not lost. Rust has made some inroads into Data Engineering, hence people like me talking about it. How so?
Rust appears to be taking the road less traveled, the road that paves the way to building high-performance Data Engineering tools; things like Polars and Datafusion. Where could Rust be used? Well, everywhere, even though that won’t happen.
Check out - https://datawithrust.com/ - if you want to spend some more time in-depth exploring how Rust can fit into your ecosystem.
Again, what does the Data Engineering community think? Check out this question and answer on r/dataengineering concerning Rust in the DE space.

More importantly, the consensus seems to be Rust for building new backend tools used by Data Engineers. No one thinks that Rust will replace Python. If Scala and Golang couldn’t do it, neither would Rust.

So, Rust in the tooling, not Rust in the data pipelines (unless it’s wrapped in Python bindings).
Introduction to Rust for Python Data Engineers.
While Rust might never (in will probably never) make it into your everyday Data Engineering tasks, I think it is worthwhile to spend some time writing a few simple Rust programs. Why? The same reason you should write little Scala, Golang, or Java.
Having even a cursory knowledge of some other language besides Python will make you a better Python Data Engineer. It will help you think about problems differently, expanding your horizons while at the same time helping you to relate to other tools and people.
Let me give you a quick and academic download on Rust; then, we will write a sample program to show you how “simple” Rust can be at times.
Rust Download

Rust is a language focused on performance, safety, and concurrency. Here are some of the main programming concepts in Rust:
Ownership and Borrowing:
Ownership is a core concept in Rust, which ensures memory safety without needing a garbage collector. Each value in Rust has a single owner, and the scope of the value is tied to the owner.
Borrowing is another critical concept where data can be accessed either immutably or mutably, but not both at the same time, preventing race conditions.
Concurrency:
Rust has strong support for concurrent and parallel programming, allowing for efficient execution of tasks without data races.
Immutability:
By default, variables in Rust are immutable, promoting a more functional programming style and aiding in making concurrent programming easier and safer.
Error Handling:
Rust encourages the use of Result<T, E> and Option<T> enums for error handling in a robust manner rather than relying on exception handling.
Zero-cost abstractions:
Rust provides high-level abstractions that don't come at the cost of runtime performance, allowing developers to write expressive code without sacrificing speed.
Traits and Generics:
Traits are a way to share interfaces and behavior across multiple structs and enums. Generics are used to create definitions for items that can operate on data types specified later.
Cargo:
Cargo is Rust’s build system and package manager that helps you manage dependencies, build your project, run your tests, and more, making it a critical part of the Rust programming environment.
Safety and Performance:
Rust is designed to be memory-safe while maintaining high performance, largely through the ownership system that manages memory and resources deterministically.
Modules and Crates:
Rust organizes code into modular units. A crate is a compilation unit in Rust, and modules allow for organizing code within a crate into namespaces.
These concepts, among others, provide a solid foundation for creating reliable, efficient, and concurrent systems and applications in Rust.
What Rust Code Actually Looks Like.
To prove to you that you can write Rust, and it isn’t all as unapproachable as you might think, let’s write a simple program that downloads a remove .gz CSV file over HTTP.
You might not understand all the syntax, but the goal is to show you that you can certainly read Rust and divine what a program is doing, meaning you could write one yourself.
First, here is the main program, broken up into different functions.
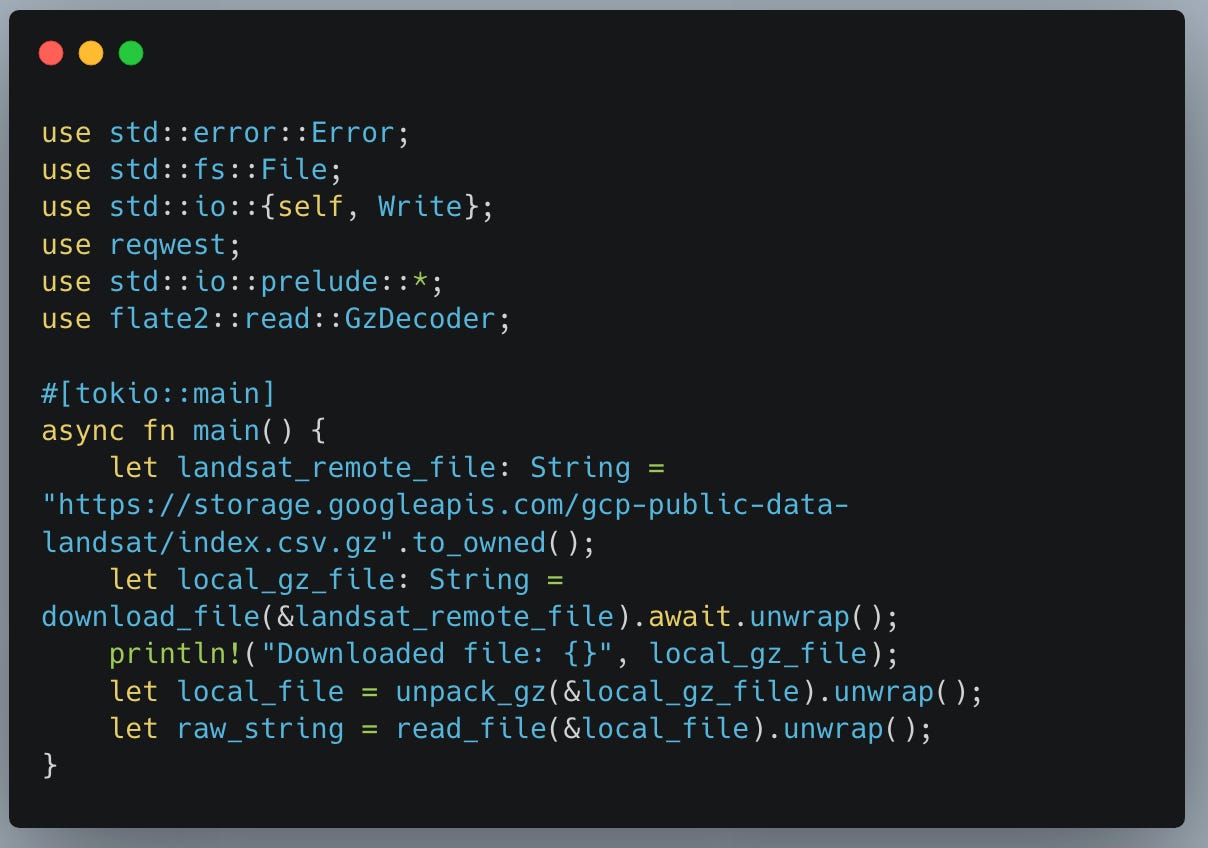
You can see we have a variable, a string that holds the URI of the file we are interested in. Also, we download the file to a local drive, at which point we unpack the .gz file into its CSV format, and then read the file.
Easy!
The actual Rust code to download a file over HTTP is not all that dissimilar to what you would see in Python. We get a response and save the contents to a file.

Next, we need to unpack the .gz file to its CSV format.
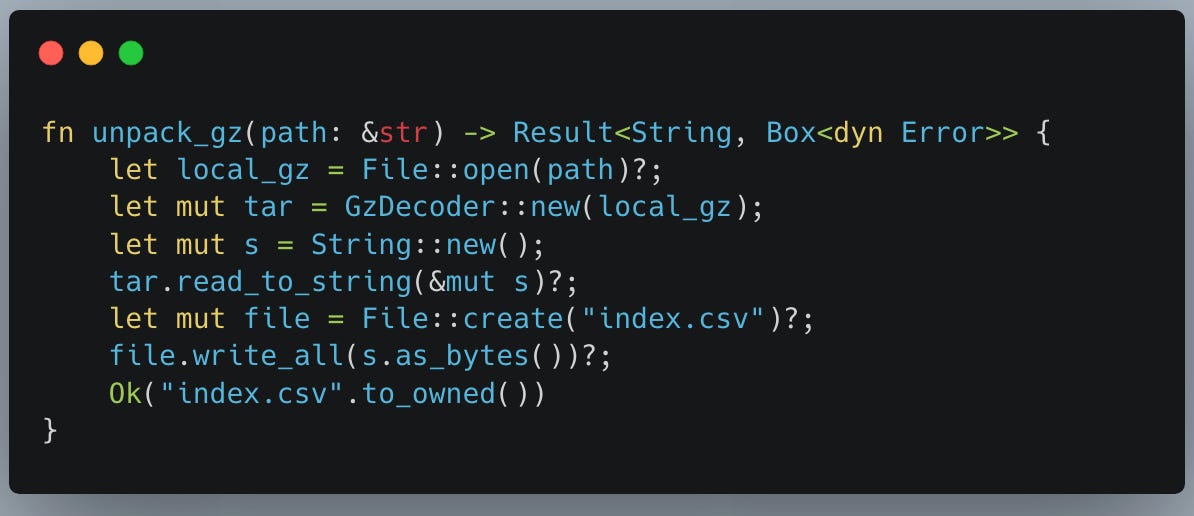
Again, no rocket science going on here. Open the .gz file, make a String, read the contents into the String, and write that String back out to a CSV file.

Lastly, of course, now that we have the CSV file, we could open it and do more processing as necessary.
The Downsides to Rust
Okay, so now you know a little about Rust concepts and have seen a simple Rust program in practice–what next? Well, all is not always golden.
Why is it that Rust won’t replace Python/Golang/Scala for everyday Data Engineering tasks?
The cognitive overburden of any Rust program will always be higher than that of other languages.
The borrower check (ownership memory model) is hard to grasp and code, even with experience.
Rust gets verbose and will lead to larger codebases to do simple things.
Complex problems in Rust aren’t a joke.
The cargo/package system isn’t as built out for Data Engineering tasks like Python or Golang.
It takes longer to do a task in Rust.
I say this as someone who loves to write Rust … I love it, but Python is just a better choice for a lot of things. I will absolutely write more Rust now and in the future.
I’ve even taken the time to write some of my own Rust open-source tools for Data Engineers … like this CSV sniffer. What do I see as the biggest boon to myself because I’ve learned to write a little Rust?
It’s changed how I think about Data Engineering tasks and how I write Python code. Love live Python. Long live Rust!
Data Engineering And Machine Learning Summit 2023!

The Seattle Data Guy and Data Engineering Things are coming together to host the first Data Engineering And Machine Learning Summit on October 25th and 26th.
The purpose of this summit is to focus on the data practitioners who are actually doing the work at companies. Solving real problems with real solutions.
For example, here are just a few of the talks we have planned!
Sudhir Mallem - Centralized ETL framework for Decentralized teams at Uber
Jessica Iriarte - Optimizing oilfield operations using time-series sensor data
Kasia Rachuta - Overcoming challenges and pitfalls of A/B testing
Siegfried Eckstedt - Test-Driven Development for Your Data, Models and Pipelines
👩🏻💻 Mikiko Bazeley 👘 Bazeley - MLOps Beyond LLMs
Joe Reis 🤓 - WTF Is Data Modeling
You’re definitely not going to want to miss this event!
Also I want to give a very special thanks to our sponsors Decube, Segment, and Onehouse! Their support is ensuring we can make this conference even bigger and better.



Data Architects Vs Data Engineers - Is There A Difference?
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
6 Bad Habits Killing Your Productivity in Data Science
Learning data science is like learning how to play a musical instrument — you must develop good habits and get the foundations straight to succeed.
Just like a musician requires scales, arpeggios, and rhythm exercises before being able to play concertos, a data scientist needs to ingrain key practices to develop their potential.
Avoiding detrimental habits and cultivating productive ones allows you to shift your mental focus from the mechanics to the artistry of your work.
Developing data science habits like using virtual environments and tracking experiments transforms your workflow from a struggle to a smooth-flowing creative process.
In this article, we’ll explore six everyday bad habits that can secretly destroy your effectiveness as a data scientist and provide tips to help boost your productivity.
Operational Data Stores Vs Data Lakehouses And All The Other Data Management Methods

A few months back, I posted a video discussing data warehouses, data lakes, and transactional databases. But there are so many other methods technical teams use to manage their data, especially as AI and machine learning are having another resurgence. I wanted to go over the various ways companies are managing their data.
End Of Day 98
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
 | A guest post by
|
Generally agree with the overall thought process.
Quick question:
Have you come across Fluvio - https://github.com/infinyon/fluvio ?
Python and Go is not going anywhere. Java and JVM is here to stay.
However Rust and WASM are going to deliver backends that would outperform most of what exists today.
We know for sure that Rust would outperform the JVM based tools with ease and it would not only be faster, it would also be cheaper.
The biggest hurdle right now is the simplicity of implementation and integration, and the ease of use at the level of abstraction that data engineers are comfortable.
For me Rust scratches an itch to do some low level code, it's been a long time since I've been able to do that. With DE getting so platformized (DataBricks, Snowflake, DBT) this job is becoming more about slinging YAML and HCL.
I think if you were writing Redis or Kafka today, Rust would be a strong choice, but it's not going to replace Python. The overall friction is way too high. I like that it makes me think about ownership and error handling up front, but that definitely makes for slower development and I don't see the data science cohort becoming Rust enthusiasts. On the other hand, I just don't see a reason to use C/C++ anymore, Rust seems like a much better choice for those applications where you'd reach for C. Java is meh, there's a lot of infra and it's the easiest path for existing integrations, but Java itself is just a bad language. The JVM alternatives like Scala and Kotlin have nice features and are nice languages but in the end you're still on the JVM with its attendant headaches. I observed to a friend recently that we've traded time saved chasing resource leaks with time wasted dealing with the operational headaches of GC.