
5 Things in Data Engineering That Have Changed In The Last 10 Years
What Will Change Next?
Hi, fellow future and current Data Leaders; Ben here 👋
Before diving into today’s newsletter, I want to take a moment to thank this issue’s sponsor: Hex. Hex brings the magic of AI to data analysis workflows, whether you’re using code or no-code. Hex helps organizations work together with data and avoid jumping between different data tools for querying, data science, visualization, and spreadsheets. Over 1600 organizations use Hex to do everything from deep analysis to self-serve.
Now let’s jump into the article!
A few months back, I wrote an article about what hasn’t changed in the data world. And much of what hasn’t changed are the problems we face.
Of course, there are also plenty of things that have changed in the data world since I started. For example, the technologies and practices we use.
Even the words and terms we use, although mostly the same, have changed. Whether you like it or not.
When I started, no one used the term analytics engineer, and even the concept of a data engineer was still relatively new(at least in terms of how popular it later became).
In the same way, I have seen plenty of things change. Some of these changes are temporary, I believe (like my first point), others are likely larger trends.
So let’s dive into what’s changed in the data world in the last decade.
1) Everyone Wants Seniors On Their Team
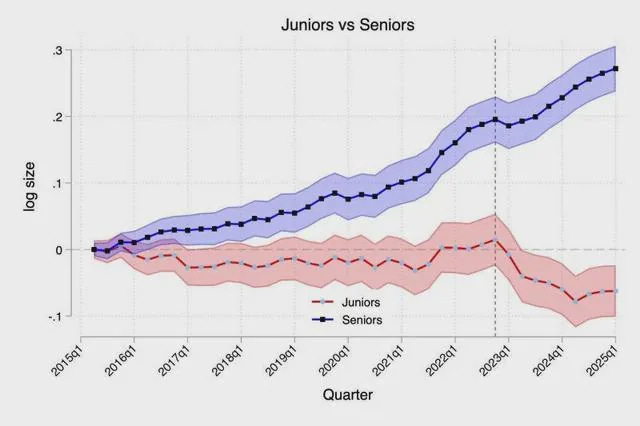
Something strange started to happen a a few years ago. Whenever I was speaking with data leaders and they brought up hiring, they always referenced senior engineers and analysts. That’s the only position they were looking for.
It didn’t really click what was going on until the chart above came out recently…and well things became clear.
Both in terms of anecdotally and in terms of data there is a trend to hire more senior engineers over a mixed team.
I’ve heard a couple of causes:
A senior engineer with a copilot can get far more work done by themselves.
Senior engineers tend to be able to jump into problems faster and apply what they’ve used in the past to solve said problem.
Data teams are smaller than they were a few years back and in turn they don’t have the head count for juniors.
That last point is from my experience, so it’s anecdotal. But, I think it’s also what many other consultants and data leaders are seeing. Smaller teams, perhaps in response to the considerably larger data teams of the early 2020s.
I do have some friends who are currently working to try to create tools to help junior engineers become more productive even if a senior engineer is around. And I imagine there will be a correction in this trend. Because if you only hire senior engineers, eventually said seniors will just demand more income until it’s no longer viewed as cost effective to mostly hire seniors.
Don’t just take my word for it, feel free to share your own thoughts.
2) Let’s Just Start With The Cloud
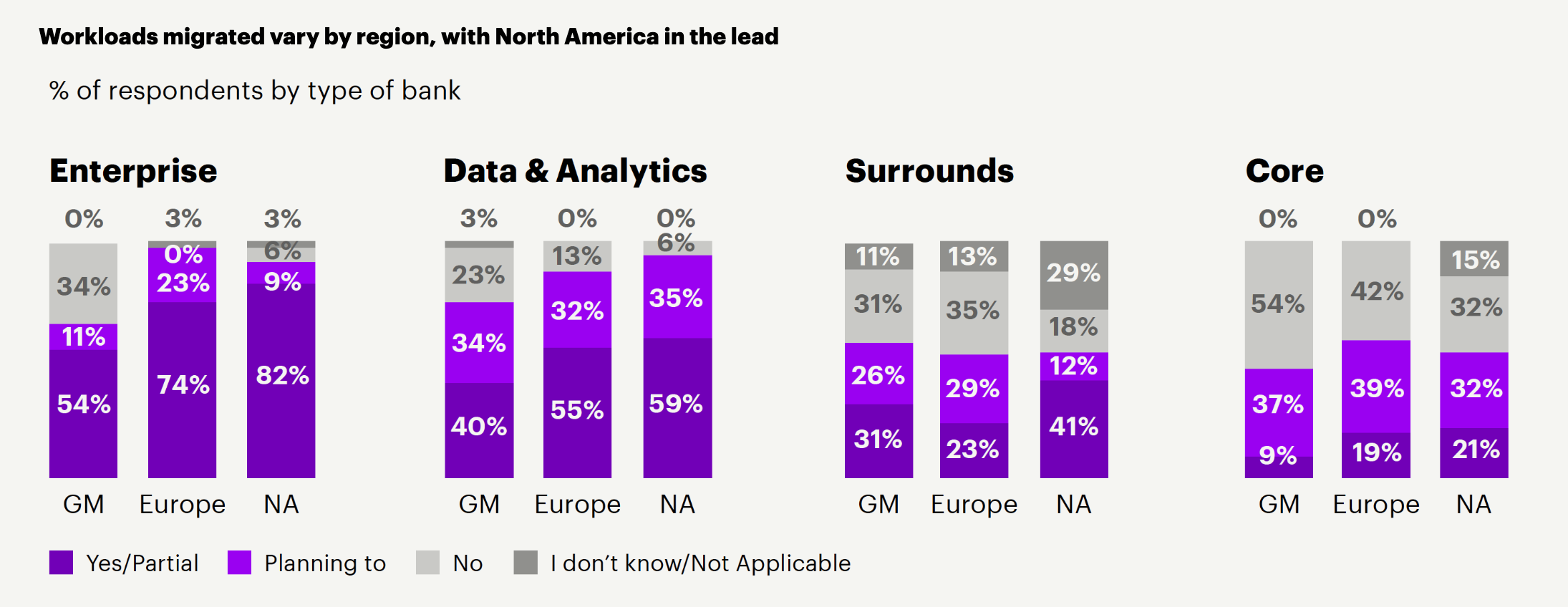
It was only a few years ago where the cloud was still an option that companies would consider.
It wasn’t the default.
Now I find many companies and data teams jump to the cloud immediately. And those not on the cloud already are migrating. Over the past few years I’ve done over half a dozen SQL Server to Snowflake migrations. Don’t just take my word for it. Looking at the chart above from Accenture back in 2021 also showed a similar trend of migrating away from on-prem to the cloud for analytics.
Cloud has become the first choice for many companies.
This is true up and down the ladder in terms of company size. Small, large, medium, I haven’t had one project where someone decided to run a database or data pipeline locally. Other than to test an idea or via a dev workflow. I know, some of y’all are probably reading this thinking, well, I am still on-prem!
There are still plenty of data stacks on-prem. Some have to be for regulations others find it cost effective to be on-prem.
However, in my experience, I am running into fewer and fewer teams that are relying on an on-prem solution for analytics.
3) Data Teams Don’t Jump To Building Their Own Custom Data Pipeline Solutions
When I first started in the data world, many “data pipeline” systems were built with cron, Windows task scheduler, maybe SQL Server agent as the scheduler, calling either a bash or Python script, or directly calling SQL or SSIS.
Most companies I’d walk into would likely have built their own data pipeline and orchestration solution. Many of which were built over the past decade or so, and you’d literally be able to sense when data leaders changed because the style of how things were written would change.
Now this isn’t the default.
Instead, there are plenty of other options, especially with the Cloud(again), from as simple as using a Lambda and Eventbridge or going straight to a tool like Airflow. People are using pre-built tools to manage their automated pipelines.
I imagine there are many reasons for this:
There is an expectation to deliver actual impact faster. Meaning if you spend time just building a data orchestration system which requires you build logging, meta-data tracking, scheduling and other components before even delivering a data pipeline, you’re likely going to hear it from the business.
There is a lot more intro content out there, and a lot of it starts with tools such as Airflow. So if you’re a new data engineer or looking to set-up your first pipeline for your company, you’ll likely run into it and start there.
Job requirements often ask for tools such as Airflow, Coalesce, dbt, and so on which means that’s what new data engineers pick-up.
Whatever the reason, building heavily custom data pipeline systems seems to be a less frequent occurrence.
As always, I’d love to hear your thoughts on this as well.
4) No One Is Questioning SQL As The Lingua Franca Of Data Anymore
Alright, that’s not 100% true. There are still people who dislike or want to replace SQL. In fact, I usually find that most data engineers fall into liking. Either SQL or Spark(via data frames and Python).
However, had you joined the data world in 2015, every tool seemed to be building its own query language. Some were just offshoots of SQL, like BigQuery’s Legacy SQL, HiveQL, etc.
Other query languages tried to build a completely new approach to how you queried data. And of course, there was NoSQL, which was always touted as “Not Only SQL. But it’s hard for me not to read it as a way of pushing against SQL in both an underhanded/overt way via a name.
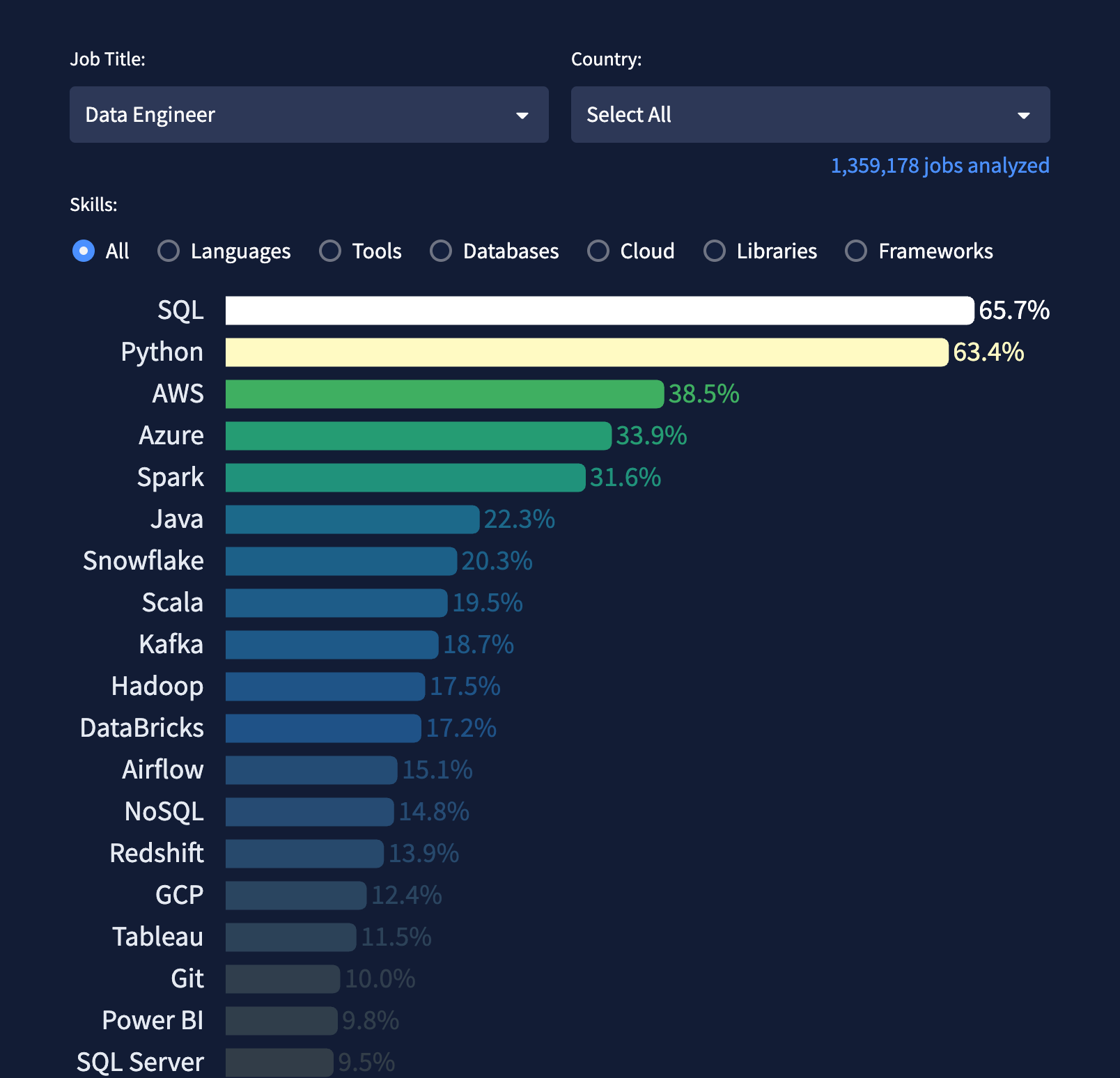
Regardless, here we are in 2025, SQL is more popular than ever.
You can check out Luke Barousse’s graph above, where he scraped data for job requirements. As you can see, SQL is almost always required. People now start by learning tools that further enforce that, like dbt.
5) AI Is Changing Workflows
It’s impossible not to acknowledge that AI is playing a role in how data teams work. Whether someone is just adding in an LLM to get rid of having to write DDL statements, or your IDE has three different copilots running at once. AI is changing the way we work.
On the positive side, I’d say I’ve personally used it and seen it remove a lot of the redundant work I’ve done in the past.
On the more negative side, I’ve also seen people start to rely on it so heavily that they don’t really look into debugging. Even when an error arises, they just put said error back into their copilot and have it try to figure out the problem. Sometimes this works, but many times I’ve seen more and more code bloat get written as a result…I guess we kind of debugged in a similar fashion during the peak of Stack Overflow.

My final thought here is that: I wouldn’t be surprised if some of that feeling of efficiency we get when using an LLM is more similar to just the feeling of movement over progress.
Final Thoughts
The more things change, the more they stay the same. But things do change. Not overnight. Just because someone in SF released some magic box that makes us all constantly question our own self-worth, doesn’t mean that tomorrow all work will cease.
Just because many of our data workflows are online, we will magically start finding new value from data, no matter how much marketing there is out there.
What I have seen change is the size of companies looking into their data, and the speed at which companies are demanding data to provide them value. Perhaps that’d better be rephrased as the impatience the business has for the data team. This could account for the hiring of seniors and the usage of the cloud, which might be viewed as faster.
But don’t let me be the only one sharing. I’d love to hear your thoughts, what has changed, what has stayed the same?
Feel free to comment, and as always, thanks for reading!
Articles Worth Reading
There are thousands of new articles posted daily all over the web! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
How and Why Netflix Built a Real-Time Distributed Graph: Part 1 — Ingesting and Processing Data Streams at Internet Scale
The Netflix product experience historically consisted of a single core offering: streaming video on demand. Our members logged into the app, browsed, and watched titles such as Stranger Things, Squid Game, and Bridgerton. Although this is still the core of our product, our business has changed significantly over the last few years. For example, we introduced ad-supported plans, live programming events (e.g., Jake Paul vs. Mike Tyson and NFL Christmas Day Games), and mobile games as part of a Netflix subscription. This evolution of our business has created a new class of problems where we have to analyze member interactions with the app across different business verticals. Let’s walk through a simple example scenario…
Is “data-driven” just slowing down your decisions?
For decades, companies have been chasing the idea of being data-driven. I recall when I first started the term was plastered everywhere.
Every blog you read and conference you went to, someone referenced that term along with the idea of data being the new oil.
Everyone wanted to be driven by data. After all, companies like Facebook and Google were doing so well. And not just them, there were plenty of statistics that showed that companies that used data were more profitable than their competitors.
Is It Time to Say Goodbye to Data Engineers?
Ever since tools like SSIS came onto the scene, vendors and business leaders have been on a mission to remove what they see as the biggest roadblock to data-driven decision-making: data engineers.
Or their counterparts—DBAs, ETL Developers, and Data Architects.
Sure, not everyone says it so explicitly, but you can see it in vendor marketing and in the decisions made by the business.
I remember talking to a veteran data expert who’s been in the field for three decades. They told me that when SSIS first launched, people were genuinely afraid for their jobs. The idea that you could just drag-and-drop tasks that once required code was nerve-racking. But if you’ve used SSIS, well, you know the truth.
To some extent, I get why the idea is appealing. When a leader requests a report, a software engineer wants to modify an application table, or a data scientist wants to explore a new dataset, who’s the one slowing down the project?
The data engineers.
End Of Day 201
Thanks for checking out our community. We put out 4-5 Newsletters a month discussing data, tech, and start-ups.
If you enjoyed it, consider liking, sharing and helping this newsletter grow.
"No one questions SQL anymore..." Great insight here. Makes me think of another thing that hasn't changed: executives expecting a silver bullet to solve their data problems :)