


The State Of Data Engineering - Part 2
Data Catalogs, Observability, ETLs And Trends
A few weeks back I started to review the data from well over 400 respondents who answered my State Of Data Survey. In that newsletter we outlined who filled out the survey as well as covered some bits about the data warehouses they were using and best practices they were implementing
In this newsletter we will be diving deeper into the types of solutions the respondents rely on. Here is a quick breakdown of the sections.
Data Catalogs
Data Observability And Quality
ETLs/ELTs
Trending Topics
Also, I invite you to post comments asking questions of the data I haven’t answered. The truth is, I could probably slice and dice this data all day and write another half dozen articles but I will likely only write 1-2 more based on this data.
For now, let’s dive into the responses on data catalogs.
1. Data Catalogs
Once data teams reach a certain size, data catalogs start becoming more than just a nice to have.
At Facebook having iData made my life easier as a data engineer because I would be able to quickly find other teams’ data sets and understand what data they represented. I could also easily track where data came from and how accurate it was.
Meaning I could avoid having to spend days or weeks tracking down owners of data sets just so I could answer simple questions.
This was also a common point brought up a while back when I interviewed people about data catalogs. Many of them pointed out that the reason they realized their team needed a data catalog was that they ran into productivity issues. Where other teams would reach out to them so constantly to ask about data, that no other work could easily move forward.
Despite the benefits, these solutions aren’t heavily utilized. 69% of respondents don’t have any form of data catalog.

This can make a lot of sense. After all, there is generally a certain size of company and data maturity that is required before companies should be spending money on a data catalog.
Below is a chart breaking down the percentage of respondents that had a data catalog broken down by company size.

From anecdotal experience, the top chart makes a lot of sense. Generally speaking, most companies don’t start looking into data catalogs until they are a certain size because they don’t have enough data or the data maturity and focus to require it. Add to that the budget factor and I’d say most of my clients don’t start really thinking about data catalogs until around 500+ employees.
Now in terms of the actual breakdown. Here were the top 10 data catalogs.

It’s great to see products like Select Star and Stemma.ai on the list. And I am not surprised to see DataHub as one of the more popular solutions! Although I am slightly surprised to not see more Atlan or Alation. But perhaps those products are more common at larger companies and thus an interesting question to ask here is:
What is the difference in the number of analysts that are impacted by these solutions?
To do so I looked at what percentage of companies that have a data catalog was over 1000 employees.

Based on the chart above, it does look like products such as Atlan, Collibra and Alation are more prominent at companies with more than 1000 employees. This overall makes sense as these products tend to be marketed at different sized companies.
For now, I will this section as we could likely continue asking questions like:
What data warehouse is most common with which data catalog?
Are companies with data catalogs more likely to have a data quality solution?
etc
2. Data Observability And Quality
Similar to data catalogs, many teams don’t have some form of data observability/data quality solution in place. To be more specific about 45% of companies have no form of data quality solution.
So although there is a lot of talk about data quality being a major issue, there is still a decent amount of companies not investing in the space. There is always talk about garbage in garbage out being a major issue, especially when you not only want to build basic analytics but also deploy machine learning models.
It’s hard to build anything on top of bad data.
That aside, here were the 10 most commonly referenced data observability/quality tools( I did remove none from this chart).

Based on the data above about 25% of respondents referenced custom or in-house built options. When I worked at a healthcare start-up they had developed an entire framework that allowed you to create data checks easily as well as track them. So it’s very common to see companies of all sizes implement a custom solution.
The first vendor-based product that is not an open-source solution is Monte Carlo at 5% (Great Expectations was ahead at 11%). Followed by products like Informatica Data Quality. But really out of over 400 respondents, this was pretty meager in terms of vendor solutions.
Other products referenced include dbt tests, Validio, DataFold, Elementary Data, Re:Data, and SodaSQL.
I’d still like to see if some products were more common at different sized companies.
For example, I assumed that Great Expectations was likely used by a lot of smaller companies as it offers an open-source product that would be pretty simple to implement.
Below I charted out what percentage of companies were using Great Expectations by size.

This was a little less clear in terms of any form of trend as even with there being a high usage of Great Expectations, it doesn’t seem to be size dependent.
Overall, when looking between no data quality solutions, in-house solutions, and Great Expectations, these options make up over 75% of the answers. So it also makes sense that it’ll be difficult to figure out which solution is more prevalent at different sized companies.
3. ETLs And ELTs
Diving into ELT/ETL tools it’s a little harder to breakdown by percentage. That’s because in this case 45% of respondents used multiple solutions.
But if we break down those solutions, here are the counts of by reference.
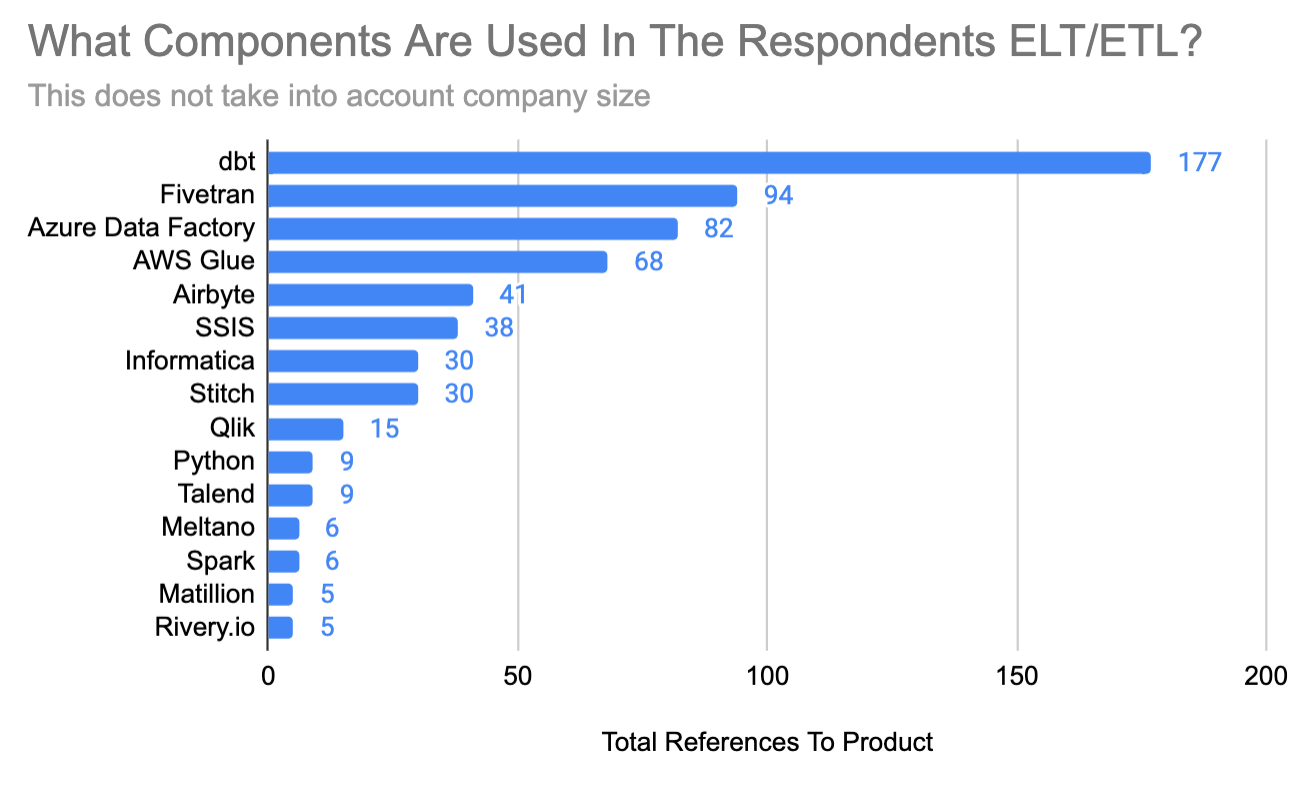
dbt, Fivetran, Azure Data Factory(ADF), AWS Glue and Airbyte were all part of the top 5 as you can see above. With dbt by far being the most common.
Other products referenced include SSIS, Informatica, Stitch, Qlik, Python, Talend, Meltano, Spark, Matillion, and Rivery
Since we have already done a breakdown by size of companies for data catalogs and data quality solutions let’s do it again for dbt.
Below is a chart showing the percentage of companies that used dbt in their ETL/ELT solution.

Looking above, we can see that there is at least a trend that most respondents implementing dbt work at companies that range from about 100-1000 employees( in terms of having about 50% of respondents that did use dbt).
This aligns with what I have seen in my experience(dbt being more common in SMB and MM companies).
Just to double-check another one of my assumptions, I wanted to see if Azure Data Factory was more frequently relied on at larger organizations.
Thus below you can see the breakdown of who uses ADF.
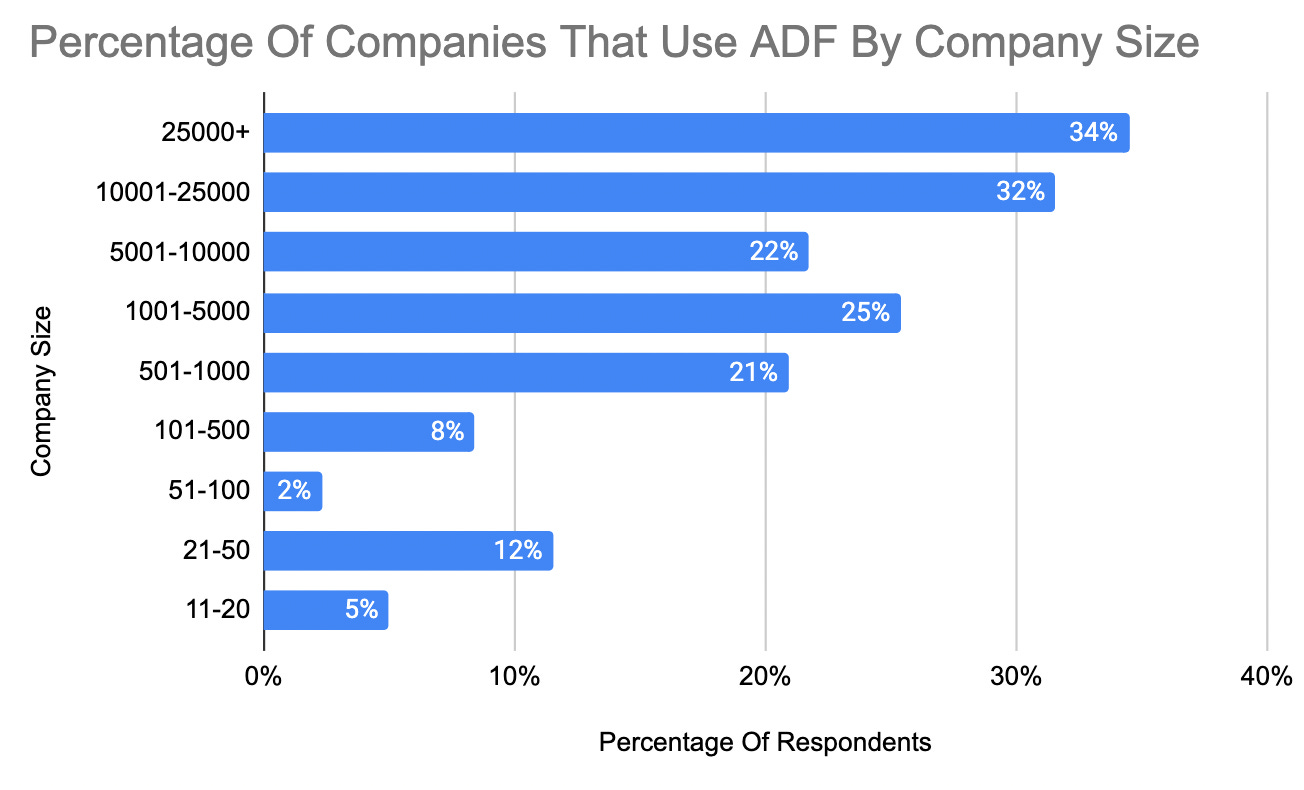
As you can see, ADF tends to be relied on more at larger organizations and trends downward as the companies become smaller. I could hypothesize why this is, but I’d need to follow up with the respondents to confirm my theories.
Now that we have gone over several more categories of data solutions, let’s dig into what trends people are aware of.
4. Trends
I wanted to dig into what people are talking about. To keep this simple I just asked if the respondents had heard of a topic. Did they know about topics like DuckDB or WASM?
Well here were the results.
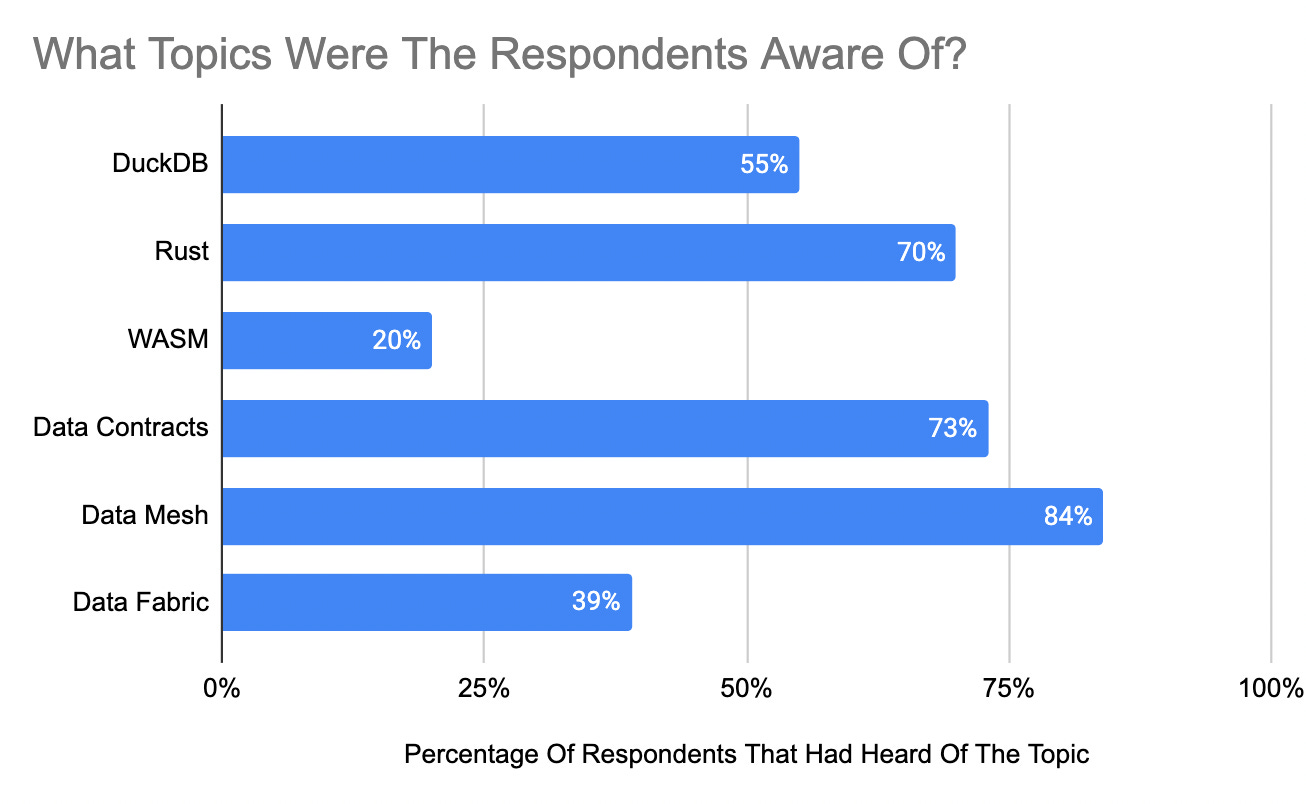
I was a little surprised to see that so many people heard about Data Mesh but so few people heard about Data Fabric. Those sometimes get associated with each other so I assumed both would be heard about a nearly equal amount.
Other than that, I’d say most of the results make sense as data contracts and Rust have been popular topics over the past year and I have slowly been hearing more about DuckDB( especially on data Twitter).
In the end, I am honestly still most excited for next year when I can do this review again.
What Questions Do You Have
Thank you again for everyone who participated in the survey. I do hope you’re finding this data as interesting as I am.
I would love to hear about your questions on this data, so feel free to ask them below and I might just include it in the next newsletter.
GA4 is a mess. Build analytics on data you can trust.

If you’re still heavily reliant on Google for data collection and reporting, now is the perfect time to center your analytics strategy around your data warehouse. This guide from RudderStack details how you can replace GA with analytics on your warehouse to eliminate data silos, avoid compliance issues, and serve every team with reliable data.
Video Of The Week
Join My Data Engineering And Data Science Discord
Recently my Youtube channel went from 1.8k to 53k and my email newsletter has grown from 2k to well over 34k.
Hopefully we can see even more growth this year. But, until then, I have finally put together a discord server.
I want to see what people end up using this server for. Based on how it is used will in turn play a role in what channels, categories and support are created in the future.
Articles Worth Reading
There are 20,000 new articles posted on Medium daily and that’s just Medium! I have spent a lot of time sifting through some of these articles as well as TechCrunch and companies tech blog and wanted to share some of my favorites!
How does AI see your country?
Welcome! This isn’t so much a blog post as an exhibition made with Midjourney, showcasing the beauty and bias of AI art. My inspiration was wondering how AI systems reflect national identity, so I used the same prompt with different country names to generate some art and the results are fascinating!
Confluent + Immerok: Cloud Native Kafka Meets Cloud Native Flink
Confluent has long helped contribute to the emerging stream processing ecosystem around Kafka with Kafka Streams, KSQL, and some of the underlying transactional capabilities in Kafka that help enable correctness for all streaming technologies.
Why add Flink? Well, we’ve watched the excitement around Flink grow for years, and saw it gaining adoption among many of our customers. Flink has the best multi-language support with first class support for SQL, Java, and Python. It has a principled processing model that generalizes batch and stream processing. It has a fantastic model for state management and fault tolerance. And perhaps most importantly, it has an incredibly smart, innovative community driving it forward. In thinking about our cloud offering and what we wanted to do with stream processing, we realized that offering a Flink service would help us provide the interfaces and capabilities that our customers wanted, and could serve as the core of our go-forward stream processing strategy.
End Of Day 69
Thanks for checking out our community. We put out 3-4 Newsletters a week discussing data, tech, and start-ups.
Great follow-up to Part 1! 👏 I really appreciate the deep dive into how the data engineering landscape is shifting—especially the points around the increasing convergence of data engineering and analytics. The growing focus on real-time data and modular architectures definitely resonates with what we’re seeing on the ground too. It's clear that the role of a data engineer is evolving from just pipeline builders to strategic enablers of business intelligence. Curious to hear your thoughts on how low-code/no-code tools will impact the field going forward. Keep these insights coming!
https://kaliper.io/data-engineering-services/
Hey Ben!
Thank you for your investigation!
I would love to see the databricks and snowflake adoption as well as cloud competition: aws vs gcp vs azure.
My feeling is GCP is catching up very aggressively.